Dataflow each batch takes longer
-
I'm looking for a technical reference on how fast-load work. Each buffer transfer seems to take longer
Case: Transfer data from Oracle to SQL Server
Dataflow Source: Oracle Oledb, fetchsize 50000, default buffer max rows 50000
Dataflow Destination: SQL Server (fast-load), rows per batch 50000, maximum commit size 50000
The transfers start quick, but as the transfer progresses the average oracle "SQL*Net message from client increases". From 2 seconds per 50000 to 8 seconds per 50000
-
Have you tried setting the fetchsize to the number of rows you are expecting from the query?
-
Thanks for the recommendation. In progress of tuning the fetchsize from 50000 (semi-halt at 140 million records) to 10000. 500000 crashes the driver (unexpected termination)
-
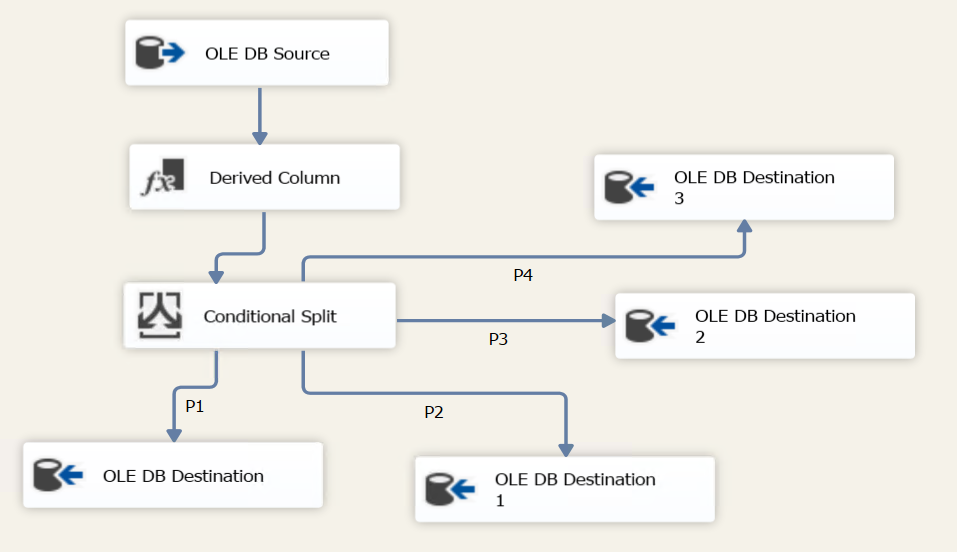
Have you tried splitting your input stream? This technique really speeds up the load.

-
I'll will try splitting it up.
The bottleneck is currently ssis or the sql destination. The source can deliver the data very vast (network spike) and then waits for ssis or sql server to catch up (only sending data to sql server).
Experimenting with network packet size smaller than mtu
-
Imagine a 2 inch pipe that you are trying to use for dumping waste from your house. 😉 That size pipe is way too small and will actually result in back-flow. Imagine you can't get a bigger pipe, but you can split the flow out several 2 inch pipes.
-
What is the target table?
Heap, indexed, columnstore, etc ?
-
Testcase
Use case:
Deleted primary key detection
Method: Copy PK from Oracle to SQL Server and compare
Problem: starts fast but slows in speed every fetch?
Expected duration: 3000 seconds , network 5 Mbps
After 542 seconds: 18 percent
Halfway todo:
Finished:
Experiment with
oracle fetchsize
sql server networkpacketsize
dataflow DefaultBufferMaxRows
dataflow DefaultBufferSize
oledb destination
Rows Per batch
Maximum insert commit size
Source: Oracle 11.2.0.4, records in table: 150000000
CREATE TABLE OMYPK(
MYPK NUMBER(19,0) not null
)
ALTER TABLE OMYPK ADD (
CONSTRAINT OMYPK_PK
PRIMARY KEY
(OMYPK)
USING INDEX OMYPK_PK
ENABLE VALIDATE);
Destination: SQL Server 2017 Enterprise, heap-table
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
BEGIN
CREATE TABLE [OMYPK__PK](
[MYPK] [numeric](19, 0) NOT NULL
) ON [SANITEL]
END
GO
Connectionstrings
Oracle: using Oracle OLEDB 19, try adjusting fetchsize?
"Data Source=MYORACLEDB;User ID=TESTUSER;Provider=OraOLEDB.Oracle.1;Persist Security Info=True;FetchSize=10000000;Pooling=False">
SQLServer: using MSOLEDBSQL instead of native client, try adjusting packetsize?
"Data Source=MYSQLSERVER\MYSQLINSTANCE;Initial Catalog=MYSQLDB;Provider=MSOLEDBSQL.1;Integrated Security=SSPI;Auto Translate=False;Application Name=ETL TEST;Persist Security Info=True;PacketSize=1460" />
SSIS 2017
Dataflow TransferPK
AutoAdjustBufferSize = False
DefaultBufferMaxRows = 2000
DefaultBufferSize = 1048576
OLEDB Source: Oracle
Data Access Mode: SQL Command
SELECT MYPK FROM OMYPK
OLEDB Destination: SQL Server
Data Access Mode: Table or view - fast load
Keep Identity = True
Keep Nulls = True
Table lock = False
Check Constraints = False
Rows Per batch = 1000000
Maximum insert commit size = 1000000 -
Didn't get much improvement with the current Oracle OLEDB driver. Even with balanced data distrubutor.
The new microsoft oracle connecter is promising (SQL Server 2019 CU1+).
Processing speed goes up from 2.000.000 records per 3 minutes to 40.000.000 records per 3 minutes. Have to check unicode conversions yet
-
Awaiting SQL 2019 backup support, trying with the ado.net driver. Doesn't seem to go slower after a while
-
DefaultBufferMaxRows = 2000 -- change to 50000
DefaultBufferSize = 1048576 -- change to 10485760 ( x 10 basically)
tablock = set to true so it can use minimal logging
connection string - set packet to max - not the 1460 you mention and native client can be better (not always)
PacketSize=32767
one thing you need to be careful when copying from Oracle to SQL server is trailing spaces - Oracle can keep them on their DB but on SQL Server you normally wish to trim them out.
As you have SQL Enterprise you are entitled to use the Attunity drivers for Oracle instead of the Connector for Oracle - performance should be the same and is not a preview hat one can be faster than the native Oracle so give it a try.
And in order to check that the issue is not Oracle but the load change your destination to be a row count so you can see the speed from source - should be constant and obviously faster than loading to sql.
Depending on your source data you may also bump into issues with charset on oracle. only you can know this, but in Europe it is very common for people to have had their charset set to ISO 8859-1 but the underlying data being ISO 8859-15.
on this case if you go directly from Oracle to SQL Server you will loose data on the conversion and your only options are
- script conversion between source and destination
- manual update of data on SQL Server post load
- do extract to file as 8859-1 from Oracle then load to SQL server as being 8859-15
-
How much memory do you have allocated to SQL Server and how big is the transfer in bytes? I ask because I've seen this before and it was simply due to not having enough memory for the data to be moved. Things would move fast until the buffers were full and then massive slowdown.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks frederico_fonseca and Jeff Moden for the extensive feedback.
I'm transfering 160 million rows of oracle 11g number (19,0) not null to sql server numeric(19,0) not null
Using SQL 2017 Enterprise + SSIS 2017
Original Dataflow: Oracle OLEDB Source -> SQL Server OLEDB Destination. No transformations. Fast Load Insert using variable
"Select mynumber from mytable" . Variable tablename "SQLServerMyTable"
"SQLServerMyTable" is a heap (no clustered index)
DefaultBufferRows: 2000
DefaultBufferSize: 104857600
FastLoad : Keep Identity, Keep Nulls, Table Lock. Rows per batch 50000, Commit after 50000
Using OracleOLEDB it slowly grinded to a halt after 90 million records. Throughput started around 20 Mbps and every few minutes it would lower to 19 MBps, 18 Mbps, .... I was lucky to transfer 3 million records in a day. At the same moment average oracle "SQL*Net message from client" wait rose from 2 ms to 3 ms, 4 ms, ... 200 ms
Preliminary testing with ado.net doesn't grind to a halt (apperantly uses OCI). Will convert to Attunity when SQL Server 2019 is supported by our company backup software.
Free RAM on server : 28 GB. Going to keep an eye on it.
-
note that as long as you have Enterprise version you can use the Attunity driver - does not need to be the 2019 version, and as they say on the link once you do manage to go to 2019 it will run with no issues.
Just make sure to get the version that matches your SSDT/Oracle version
Also note that as you are loading onto a heap you may be able to split the dataflow into a few and load in parallel.
e.g.
- DF1 - select 40 million rows from ... where ID < xxx
- DF2 - select 40 million rows from ... where ID >= xxx and < yyy
- DF3 - select 40 million rows from ... where ID >= yyy and < zzz
- DF4 - select 40 million rows from ... where ID >= zzz
- Jo Pattyn wrote:
Thanks frederico_fonseca and Jeff Moden for the extensive feedback.
I'm transfering 160 million rows of oracle 11g number (19,0) not null to sql server numeric(19,0) not null
Using SQL 2017 Enterprise + SSIS 2017
Original Dataflow: Oracle OLEDB Source -> SQL Server OLEDB Destination. No transformations. Fast Load Insert using variable
"Select mynumber from mytable" . Variable tablename "SQLServerMyTable"
"SQLServerMyTable" is a heap (no clustered index)
DefaultBufferRows: 2000
DefaultBufferSize: 104857600
FastLoad : Keep Identity, Keep Nulls, Table Lock. Rows per batch 50000, Commit after 50000
Using OracleOLEDB it slowly grinded to a halt after 90 million records. Throughput started around 20 Mbps and every few minutes it would lower to 19 MBps, 18 Mbps, .... I was lucky to transfer 3 million records in a day. At the same moment average oracle "SQL*Net message from client" wait rose from 2 ms to 3 ms, 4 ms, ... 200 ms
Preliminary testing with ado.net doesn't grind to a halt (apperantly uses OCI). Will convert to Attunity when SQL Server 2019 is supported by our company backup software.
Free RAM on server : 28 GB. Going to keep an eye on it.
Have you simply tried using OPENQUERY? About 3 days ago, one of the folks in a sister company was having similar issues "talking" to an IBM PowerSystem (the replacement for AS400's). It was taking about 2 hours to transfer the data (I don't know how much data though). Using OPENQUERY through a linked server dropped that down to 12 seconds.,
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 1 through 15 (of 16 total)
You must be logged in to reply to this topic. Login to reply