Database doesn't decrease in size after shrinking .mdf file
-
Database total size is 5.35 Tb.
1.6 Tb of it is free space (30%).
So, thinking logically, if I shrink .mdf file then my database will be decreased in size by 1.6 Tb.
However, after shrinking size does not change at all. Still 5.35 Tb.
How can I free up that 1.6 Tb of that free space?
-
did you do a shrink database or a shrink file? looks like the first 1 and that is the wrong one to use
-
I shrank file. Not database
-
What command did you run to shrink, please post the exact TSQL.
Also note the largest index in the database and double it. Never shrink so that free space is less than that number as you will need to perform index maintenance to sort out the fragmentation caused by shrinking. So ensure you leave enough space for that index to be rebuilt.
-
@Ant-Green thank you for the tip.
The code:
-- Shrink the mdf file.
DBCC SHRINKFILE(N'FileName', 0, TRUNCATEONLY);
GOAfter one of the replies I decided to shrink database (not file), using SSMS Wizard. It's been executing for 3 hours now.
-
shrink database is pointless - you do need to do shrinkfile but not using the option truncateonly as that will not move data around the file so it can free up space at the end and then free the space to the OS
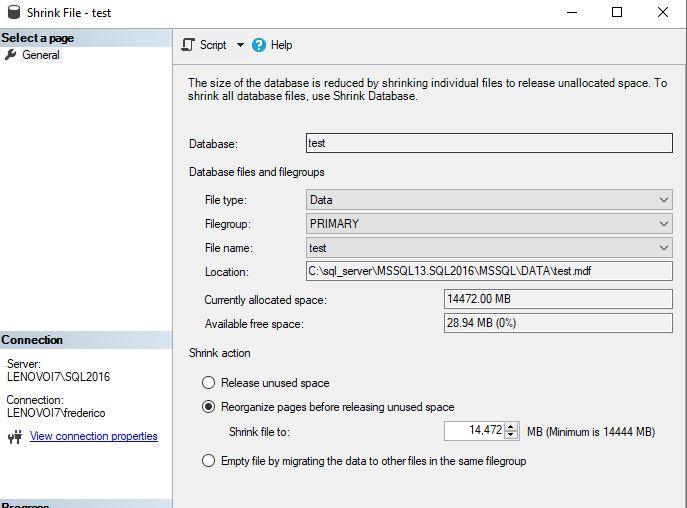
on the wizard select the following and enter space accordingly.
it will give you a command of DBCC SHRINKFILE(N'FileName', YYYY) where YYYY is the desired space

- olegserdia wrote:
@Ant-Green thank you for the tip.
The code:
-- Shrink the mdf file.
DBCC SHRINKFILE(N'FileName', 0, TRUNCATEONLY);
GOAfter one of the replies I decided to shrink database (not file), using SSMS Wizard. It's been executing for 3 hours now.
BWAAA-HAAAAA-HAAAA !!! Lordy.... You move to0 damned fast. 😉
The TRUNCATEONLY is the problem. You really need to read the documentation on SHRINKFILE I also wouldn't try to do the shrink file in one go. Doing it in one go provides absolutely no clues as to what the progress is and, if you stop it, you have no clue how far it got. I'd write a bit of code to do it 5GB chunks in a loop that also reported progress AT THE FILE LEVEL.
You're also missing a prime opportunity to move some of your larger Clustered Indexes to their own file groups so that you don't end up with a shedload of unwanted free space the next time you have to do a rebuild on them. You know... like right after you get done with this shrink because they "inverted" during the shrink, which is the worst form of logical fragmentation there is.
And did you check for allocated but unused space on the database to figure out if maybe the "FAST INSERT" mode is actually the cause of so much unused space? "Fast Insert" is notorious for this especially on single row inserts on an OLTP system because "Fast Insert" doesn't actually care if you have any free pages available. Under the easily common "right conditions", it will allocate a full EXTENT for every single row that gets inserted. Yeah... there are a couple of fixes for that.
If it were me, I'd stop the shrink and do some more homework about the things I just mentioned.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Also, free space is not a bad thing.
Michael L John
If you assassinate a DBA, would you pull a trigger?
To properly post on a forum:
http://www.sqlservercentral.com/articles/61537/ -
You should never shrink a database, only shrink a file(s).
It seems as if you have one gigantic data file (very bad idea, btw, you should use multiple data files, but that's for later). Presumably it's the PRIMARY data file, which would be file #1. If so, you need to run this command:
DBCC SHRINKFILE ( 1, 4194304 ) --shrink file to 4TB (leave ~250GB free, don't want to remove all empty space from the file)
Even as big as that file is, I'd do one shrink, as above, rather than hundreds of small ones because I've found that for larger files small shrinks often take as long, or nearly as long, as a very large one.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Like I said earlier, the trouble with doing a single big shrink is you have no way of telling how far it's gone nor how much is left to do. Since there's no real cost to doing the smaller ones, then enjoy the reporting.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply