Create Unique combination as Key out of N columns
-
Ahoi,
i have a set of 7 int columns in a table.
My goal is im trying to create a unique key/integer for each possible combination of these 7 by merging these 7 together.
My issue:
- Has to be calculated in runtime so i cant just place them into a table and use identity column
- I cant use ROWNUMER() because it is partitioned, so depending on the partition it will restart counting, so the column has to be calculated out of the 7 somehow
- I cant simply combine them by just adding them as strings and back to bigint (ex. 2020,12,69 --> 20201269) because the key size and number of keys, because it will become even bigger as bigint as ridiculess as it sounds
I have around 2500 combinations i need to take care of, as ridiculess as it sounds i need to find how create a calculation based on these 7 numbers that allows me to not create integers (big int) that dont become ridiculessly big.
Anyone ideas?
I want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
Has to be calculated in runtime so i cant just place them into a table and use identity column
Not following you there. Why can't you look up the "meta-key" from a table at run time? Besides, I think that's by far the most viable solution overall. When a unique combination is added to the main table, you add a corresponding row to the "meta-key" table, and, if you want, add that new value into the original table row (denormalize the meta-key so it doesn't require a separate look up every time).
I cant use ROWNUMER() because it is partitioned, so depending on the partition it will restart counting, so the column has to be calculated out of the 7 somehow
ROWNUMBER() doesn't have to be partitioned, but the required sort would be massive overhead and would be inconsistent as new values are added, so, yeah, I don't think ROWNUMBER() will help you here.
I cant simply combine them by just adding them as strings and back to bigint (ex. 2020,12,69 --> 20201269) because the key size and number of keys, because it will become even bigger as bigint as ridiculess as it sounds
Nope, doesn't sound ridiculous, sounds correct. No way you could reasonably ever generate and work with a number large enough to handle 7 separate int values.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ktflash wrote:
Ahoi,
i have a set of 7 int columns in a table.
My goal is im trying to create a unique key/integer for each possible combination of these 7 by merging these 7 together.
My issue:
- Has to be calculated in runtime so i cant just place them into a table and use identity column
- I cant use ROWNUMER() because it is partitioned, so depending on the partition it will restart counting, so the column has to be calculated out of the 7 somehow
- I cant simply combine them by just adding them as strings and back to bigint (ex. 2020,12,69 --> 20201269) because the key size and number of keys, because it will become even bigger as bigint as ridiculess as it sounds
I have around 2500 combinations i need to take care of, as ridiculess as it sounds i need to find how create a calculation based on these 7 numbers that allows me to not create integers (big int) that dont become ridiculessly big.
Anyone ideas?
If I'm reading this correctly, it's a fairly simple task. Please post 10 rows of data as "readily consumable data" and I'll show you a way.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
>> I have a set of 7 INTEGER columns in a table. My goal is I'm trying to create a unique key/integer <<
Why? While very unusual, and something I've never seen in all the time I've been programming in SQL, it is perfectly legal to have a declaration like:
PRIMARY KEY(c1, c2, c3, c4, c5, c6, c7). The most of ever used in the key was five columns; the first three were XYZ coordinates in the last two physical locations.
There is no need to try to come up with some elaborate hashing algorithm if these are actually columns. By definition, each column should model independent and separate attributes of the entity in the table. Your concatenation makes no sense.
Please post DDL and follow ANSI/ISO standards when asking for help.
-
Sorry for the late answer
Jeff Moden wrote:ktflash wrote:Ahoi,
i have a set of 7 int columns in a table.
My goal is im trying to create a unique key/integer for each possible combination of these 7 by merging these 7 together.
My issue:
- Has to be calculated in runtime so i cant just place them into a table and use identity column
- I cant use ROWNUMER() because it is partitioned, so depending on the partition it will restart counting, so the column has to be calculated out of the 7 somehow
- I cant simply combine them by just adding them as strings and back to bigint (ex. 2020,12,69 --> 20201269) because the key size and number of keys, because it will become even bigger as bigint as ridiculess as it sounds
I have around 2500 combinations i need to take care of, as ridiculess as it sounds i need to find how create a calculation based on these 7 numbers that allows me to not create integers (big int) that dont become ridiculessly big.
Anyone ideas?
If I'm reading this correctly, it's a fairly simple task. Please post 10 rows of data as "readily consumable data" and I'll show you a way.
Sorry for late reply:
select One=28,Two=106,Three=001,Four=5,Five=2672,Six=428,Seven= 272
into #table
insert into #table
(One,Two,Three,Four,Five,Six,Seven)
values
(29,106,0001,5,2611,415,269)
,(28,106,0001,5,2442,480,270)
,(28,106,0001,5,2735,520,271)
,(28,106,0001,5,2466,520,270)
,(27,117,0030,5,2328,496,270)
,(26,106,0001,5,2666,427,273)
,(26,128,0060,5,3082,431,270)
,(27,106,0001,5,2640,504,270)
,(26,106,0001,5,2695,427,273)
select *
from #tableI want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
You have some values that have leading zeros. Must the leading zeros be preserved? If so, then not all of the columns are actually INTs as you said. Let me know, please.
And, just in case we need to go another route than I was first thinking...
It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
[EDIT] Actually, I need to know the latter in either case.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
You have some values that have leading zeros. Must the leading zeros be preserved? If so, then not all of the columns are actually INTs as you said. Let me know, please.
And, just in case we need to go another route than I was first thinking...
It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
[EDIT] Actually, I need to know the latter in either case.
Hmm, does that really matter? I mean, if the data type of the column is int, would you want to rely on only smallint or less values being INSERTed to the columns? I know I wouldn't. That is, if the column is int, I would want any code to always work for the entire range of all valid int values.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:Jeff Moden wrote:
You have some values that have leading zeros. Must the leading zeros be preserved? If so, then not all of the columns are actually INTs as you said. Let me know, please.
And, just in case we need to go another route than I was first thinking...
It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
[EDIT] Actually, I need to know the latter in either case.
Hmm, does that really matter? I mean, if the data type of the column is int, would you want to rely on only smallint or less values being INSERTed to the columns? I know I wouldn't. That is, if the column is int, I would want any code to always work for the entire range of all valid int values.
Understood. Not every one right-sizes their columns but they should. If a column will never contain a number that exceeds a SMALLINT or TINYINT, it's a total waste of disk space and (more importantly) RAM to create it as an INT.
That being said, if there's some other application plugging data into this column and that application has relegated all columns to INT, then I totally agree but the right-sizing thing may need to hold off until someone does the analysis and determines the ROI of possible right-sizing the junk in the app. For example, ya just gotta "love" people that program the front end for DECIMAL(18,0) for anything and everything that will contain some form of int even if its only ever going to contain a "1" or "0".
I first need to know if KT knows of any required limits. I don't want to write code that perpetuates the mistake of not right-sizing.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
nvm, OP obviously not interested at all in this approach.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeff Moden wrote:
You have some values that have leading zeros. Must the leading zeros be preserved? If so, then not all of the columns are actually INTs as you said. Let me know, please.
And, just in case we need to go another route than I was first thinking...
It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
[EDIT] Actually, I need to know the latter in either case.
All columns have values
leading zeroes dont matter.
I want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was - Jeff Moden wrote:ScottPletcher wrote:Jeff Moden wrote:
You have some values that have leading zeros. Must the leading zeros be preserved? If so, then not all of the columns are actually INTs as you said. Let me know, please.
And, just in case we need to go another route than I was first thinking...
It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
[EDIT] Actually, I need to know the latter in either case.
Hmm, does that really matter? I mean, if the data type of the column is int, would you want to rely on only smallint or less values being INSERTed to the columns? I know I wouldn't. That is, if the column is int, I would want any code to always work for the entire range of all valid int values.
Understood. Not every one right-sizes their columns but they should. If a column will never contain a number that exceeds a SMALLINT or TINYINT, it's a total waste of disk space and (more importantly) RAM to create it as an INT.
That being said, if there's some other application plugging data into this column and that application has relegated all columns to INT, then I totally agree but the right-sizing thing may need to hold off until someone does the analysis and determines the ROI of possible right-sizing the junk in the app. For example, ya just gotta "love" people that program the front end for DECIMAL(18,0) for anything and everything that will contain some form of int even if its only ever going to contain a "1" or "0".
I first need to know if KT knows of any required limits. I don't want to write code that perpetuates the mistake of not right-sizing.
In SQL 2016, it's rarely a waste of disk space. Specifying ROW compression is standard procedure for all tables unless there's a specific reason not to.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
In SQL 2016, it's rarely a waste of disk space. Specifying ROW compression is standard procedure for all tables unless there's a specific reason not to.
"Standard Procedure for ALL Tables"???? Lordy... Be careful about that, Scott. I hope no one even thinks of calling it or using it as a "Standard Procedure". In fact, I would hope that the exact opposite would be true. If there were to be a "Standard Procedure" for this it should be to "AVOID ROW AND PAGE COMPRESSION unless you can PROVE that it will do no harm".
There is good reason not to use it willy-nilly (especially not as a "Standard Procedure" of some ill-conceived supposed "Best Practice" )... it actually DOES waste a huge amount of disk space (and Log File space) and seriously slows down inserts and wastes huge amounts of I/O and CPU time because of the massive number of page splits it causes when it expands to the "next size", which also causes seriously reduced page density not to mention the resulting serious fragmentation on indexes that would ordinarily not suffer from either. Never before has right-sizing been more important!
If you have a link where someone has recommended this practice as a "Standard Procedure" or a bloody "Best Practice", let me know so I can prove to them just how bad an idea it all is! Using it on WORM and totally STATIC tables is a great idea... just on on table that can suffer updates.
Don't take my word for it, though)... try it for yourself! Details are in the comments. (Replace dbo.fnTally with your favorite sequence generator of get the function for the article and the like-name link in my signature line below).
EXPANSIVE INTEGER UPDATES WITHOUT ROW COMPRESSION
/**********************************************************************************************************************
Purpose:
Demonstrate that updates to INT columns from a number that would fit in 1 byte to a number that cannot causes NO
fragmentation WHEN ROW COMPRESSION IS NOT ACTIVE.
This is because the INTs are fixed width when ROW Compression is NOT active.
Revision History:
Rev 00 - 15 Dec 2020 - Jeff Moden
- Initial creation and unit test.
**********************************************************************************************************************/
--===== If the test table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS dbo.JBM_RCTest
;
GO
--===== Create the test table with a Clustered PK.
-- Note that ALL of the columns are fixed width and this index should
-- NEVER fragment.
CREATE TABLE dbo.JBM_RCTest
(
JBM_RCTestID INT IDENTITY(1,1)
,IntCol01 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol02 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol03 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol04 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol05 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol06 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol07 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol08 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol09 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol10 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,OtherCols CHAR(100) NOT NULL
,CONSTRAINT PK_JBM_RCTest PRIMARY KEY CLUSTERED (JBM_RCTestID)
WITH (DATA_COMPRESSION = NONE)
)
;
--===== Populate the table
INSERT INTO dbo.JBM_RCTest
(OtherCols)
SELECT String01 = 'X'
FROM dbo.fnTally(1,1000000)
;
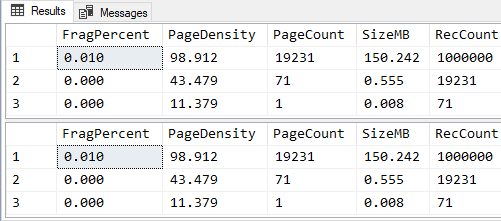
--===== Check the Logical Fragmentation and Page Density.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
--===== Update 4 columns with numbers that usually won't fit in 1 byte.
UPDATE tgt
SET IntCol04 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol05 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol06 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol07 = ABS(CHECKSUM(NEWID())%16777215)
FROM dbo.JBM_RCTest tgt
WHERE JBM_RCTestID % 100 = 0 -- Only updating 1 out of 100 rows
;
--===== Check the Logical Fragmentation and Page Density, again.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
GORESULTS (absolutely no extra fragmentation caused):

@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
EXPANSIVE INTEGER UPDATES WITH ROW COMPRESSION
/**********************************************************************************************************************
Purpose:
Demonstrate that updates to INT columns from a number that would fit in 1 byte to a number that cannot causes MASSIVE
fragmentation WHEN ROW COMPRESSION IS ACTIVE.
This is because the INTs are NOT fixed width when ROW Compression is active.
Revision History:
Rev 00 - 15 Dec 2020 - Jeff Moden
- Initial creation and unit test.
**********************************************************************************************************************/
--===== If the test table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS dbo.JBM_RCTest
;
GO
--===== Create the test table with a Clustered PK.
-- Note that ALL of the columns are inherently variable width thanks to ROW Compression being turned on and
-- THIS INDEX IS SERIOUSLY PRONE TO FRAGMENTATION!
CREATE TABLE dbo.JBM_RCTest
(
JBM_RCTestID INT IDENTITY(1,1)
,IntCol01 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol02 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol03 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol04 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol05 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol06 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol07 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol08 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol09 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,IntCol10 INT NOT NULL DEFAULT (ABS(CHECKSUM(NEWID())%256))
,OtherCols CHAR(100) NOT NULL
,CONSTRAINT PK_JBM_RCTest PRIMARY KEY CLUSTERED (JBM_RCTestID)
WITH (DATA_COMPRESSION = ROW) --THIS IS THE ONLY CODE CHANGE MADE FOR THIS TEST!
)
;
--===== Populate the table
INSERT INTO dbo.JBM_RCTest
(OtherCols)
SELECT String01 = 'X'
FROM dbo.fnTally(1,1000000)
;
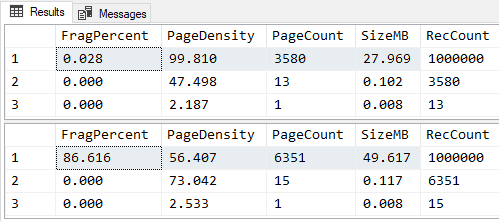
--===== Check the Logical Fragmentation and Page Density.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
--===== Update 4 columns with numbers that usually won't fit in 1 byte.
UPDATE tgt
SET IntCol04 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol05 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol06 = ABS(CHECKSUM(NEWID())%16777215)
,IntCol07 = ABS(CHECKSUM(NEWID())%16777215)
FROM dbo.JBM_RCTest tgt
WHERE JBM_RCTestID % 100 = 0 -- Only updating 1 out of 100 rows
;
--===== Check the Logical Fragmentation and Page Density, again.
SELECT FragPercent = CONVERT(DECIMAL(6,3),avg_fragmentation_in_percent)
,PageDensity = CONVERT(DECIMAL(6,3),avg_page_space_used_in_percent)
,PageCount = page_count
,SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,RecCount = record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.JBM_RCTest'),NULL,NULL,'DETAILED')
;
GORESULTS (MASSIVE fragmentation and reduction in Page Density caused):
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ktflash wrote:Jeff Moden wrote:
You have some values that have leading zeros. Must the leading zeros be preserved? If so, then not all of the columns are actually INTs as you said. Let me know, please.
And, just in case we need to go another route than I was first thinking...
It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
[EDIT] Actually, I need to know the latter in either case.
All columns have values
leading zeroes dont matter.
You haven't answered my other question... here it is again...
Jeff Moden wrote:It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ktflash wrote:Jeff Moden wrote:
You have some values that have leading zeros. Must the leading zeros be preserved? If so, then not all of the columns are actually INTs as you said. Let me know, please.
And, just in case we need to go another route than I was first thinking...
It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
[EDIT] Actually, I need to know the latter in either case.
All columns have values
leading zeroes dont matter.
You haven't answered my other question... here it is again...
Jeff Moden wrote:It appears that all of the columns have values < the max of a SMALLINT and some are smaller than a TINYINT and it also appears that no negative numbers are present. Are those aspects consistent for each column in the real table?
Sorry missed out on that one.
Yes, all columns are:
- Positiv
- All columns are integer, varying from 1 to the thousands or ten thousands
I want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
Ok, KT... here you go. I made a million row table just for test purposes. Although the use of HASH(MD5) is no guarantee of avoiding collisions forever, the "PIPES" in the conversion make it a whole lot less likely. Remember that for such hash conversions, if they're different between two items, then those items being different is guaranteed. If the hashes are the same, the two items could still be different. For the 2500 rows of 7 different columns, I don't believe you'll run into a problem although it is still possible.
Perhaps I'm reading it wrong but you said that these were going to be partitioned... why on Earth would you need to partition just 2500 rows???
Also, you need to treat the hashed column as if it were a random GUID especially when it comes to index maintenance. NEVER (and I don't use that word often, so you know I'm serious) use REORGANIZE on this clustered index (or a GUID). Don't wait for 5% logical fragmentation, either. REBUILD it if it goes over 1% as soon as it goes over. Such randomly distributed PKs very quickly explode with page splits if you let it go for more than 1%.
The other problem with this PK is that it's not necessarily static but that almost doesn't matter because of the broad random nature it has.
There's some more info in the comments in the code...
--===== If the test table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS dbo.TestTable
;
GO
--===== Create the test table.
CREATE TABLE dbo.TestTable
(
NKHash BINARY(16) NOT NULL
,Col1 INT NULL
,Col2 INT NULL
,Col3 INT NULL
,Col4 INT NULL
,Col5 INT NULL
,Col6 INT NULL
,Col7 INT NULL
,CONSTRAINT NK_TestTable
PRIMARY KEY CLUSTERED (NKHash) WITH (FILLFACTOR = 81)
)
;
--===== Populate the test table. NKHask is the clustered PK.
-- That's a bit like having a random GUID for a PK and so
-- that's why I setup a FILLFACTOR of 81. Since this is the
-- first insert on the new clustered index and we're using
-- WITH (TABLOCK), the data will "follow the FillFactor".
WITH cteBaseData AS
(
SELECT TOP 1000000
Col1 = CONVERT(INT,ABS(CHECKSUM(NEWID())%100000)+1)
,Col2 = CONVERT(INT,ABS(CHECKSUM(NEWID())%100000)+1)
,Col3 = CONVERT(INT,ABS(CHECKSUM(NEWID())%100000)+1)
,Col4 = CONVERT(INT,ABS(CHECKSUM(NEWID())%100000)+1)
,Col5 = CONVERT(INT,ABS(CHECKSUM(NEWID())%100000)+1)
,Col6 = CONVERT(INT,ABS(CHECKSUM(NEWID())%100000)+1)
,Col7 = CONVERT(INT,ABS(CHECKSUM(NEWID())%100000)+1)
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
)
INSERT INTO dbo.TestTable WITH (TABLOCK)
(NKHash,Col1,Col2,Col3,Col4,Col5,Col6,Col7)
SELECT NKHash = HASHBYTES('MD5',CONCAT(Col1,'|',Col2,'|',Col3,'|',Col4,'|',Col5,'|',Col6,'|',Col7))
,Col1,Col2,Col3,Col4,Col5,Col6,Col7
FROM cteBaseData
;
--===== Prove that the INSERT followed the FILLFACTOR
SELECT SizeMB = CONVERT(DECIMAL(9,3),page_count/128.0)
,avg_fragmentation_in_percent
,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.TestTable'),1,NULL,'SAMPLED')
;
--===== Note the the PIPE characters are essential in preventing hash collisions.
-- You can use that same formula in an INSERT and UPDATE trigger to maintain
-- the table. I don't recommend using a PERSISTED computed column because
-- CONCAT is a system scalar function and Brent Ozar has proven that those
-- (or UDFs) will not allow queries against the table to go parallel if
-- such things are present even if they're not in the query.
--REFs: https://www.brentozar.com/archive/2020/10/using-triggers-to-replace-scalar-udfs-on-computed-columns/
-- https://www.sqlservercentral.com/articles/some-t-sql-inserts-do-follow-the-fill-factor-sql-oolieAnd, yeah... I know that MD5 has been deprecated. It should also never be used for encryption anymore. We're not using it for that. I used it because it provides a pretty good 16 byte hash, which is the smallest viable hash in T-SQL at this point. Next step up is 20 bytes but that's also been deprecated (which we don't know if or when it will actually go away) and the step after that is 32 bytes, which seems kind of stupid to do for only 7*4=28 bytes of data.
And, no... I wouldn't use BINARY_CHECKSUM. It is much more prone to collisions than even HASHBYTEs with MD5. If you lookup BINARY_CHECKSUM, they actually do say that HASHBYTES with MD5 is better and so I'm thinking that it's not going away any time soon (could still be wrong about that but there aren't many other choices).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 1 through 15 (of 27 total)
You must be logged in to reply to this topic. Login to reply