Columnstore or not to columnstore?
-
Should we think about compressing tables like MyHugeTbl 200 million rows table which during the day only has reads/scans but is refreshed-truncated and loaded every night. Will the compression or columnstore indexing change the job runtime drastically? there are only 2 indexes on the table, one CI and one NCI.
I am thinking that before load indexes should be dropped and then recreated? Or not necessarily and only testing can suggest a verdict?
Likes to play Chess
-
you are the one that needs to figure that out for your own environment. test test test.
-
Compression means more rows stored on a page, reducing I/O by reducing the number of pages needed to retrieve a value and the number of pages needed in memory.
Columnstore is a completely different storage mechanism (although it also has compression) that is reorienting your data storage from rows to columns. This more directly supports analytical style queries (GROUP BY, SUM, AVG, etc.) while sacrificing performance of point lookup style queries (one row or one small set of rows based on tight filtering criteria).
These are not interchangeable parts, compression & columnstore. They do different things. They have different purposes. Could one help you more than the other? Yes. However, you have to determine what the problem is in the first place in order to understand which of these mechanisms is more likely to help. For example, if you primarily have point lookup queries, implementing columnstore won't help performance and will likely seriously, negatively, impact that performance. That assumes you use a clustered columnstore. If you just add a nonclustered columnstore and you're running point lookup queries, chances are, you've sacrificed a lot of disk space and added a bunch of overhead to loading the data, but the optimizer will just ignore the index in favor of those that better support point lookups.
I wish there were easy answers when we start talking about performance tuning. If A do Z. If B do Y. However, it's just rarely that simple. You have to understand what the purpose of your queries is. You have to understand the structures that you have in support of those queries. You have to understand how SQL Server works to use the structures in support of those queries. Then, you have to understand all the options & methods that can better support your queries and structures. There isn't a shortcut like put NOLOCK on every query, enable compression, or switch all storage to columnstore. Any of these, situationally could help. Equally, any of these, situationally, could be neutral or could hurt. We have to understand the situation in order to better apply a solution.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning - VoldemarG wrote:
Should we think about compressing tables like MyHugeTbl 200 million rows table which during the day only has reads/scans but is refreshed-truncated and loaded every night. Will the compression or columnstore indexing change the job runtime drastically? there are only 2 indexes on the table, one CI and one NCI.
I am thinking that before load indexes should be dropped and then recreated? Or not necessarily and only testing can suggest a verdict?
Since the data is totally reloaded every day, this sounds like maybe a reporting table of some type. Are you doing a large number of aggregate queries on the data? If not, what is the table being used for? What the table is being used for is a large part of the decision making process. Also, do the columns contain a lot of repetitive data? That's another part of the decision making process.
But... I agree with Frederico and Grant... It's totally worth it to test. One good set of tests will identify the correct option to use because, ultimately and always, "It Depends".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks everyone for your valuable input!
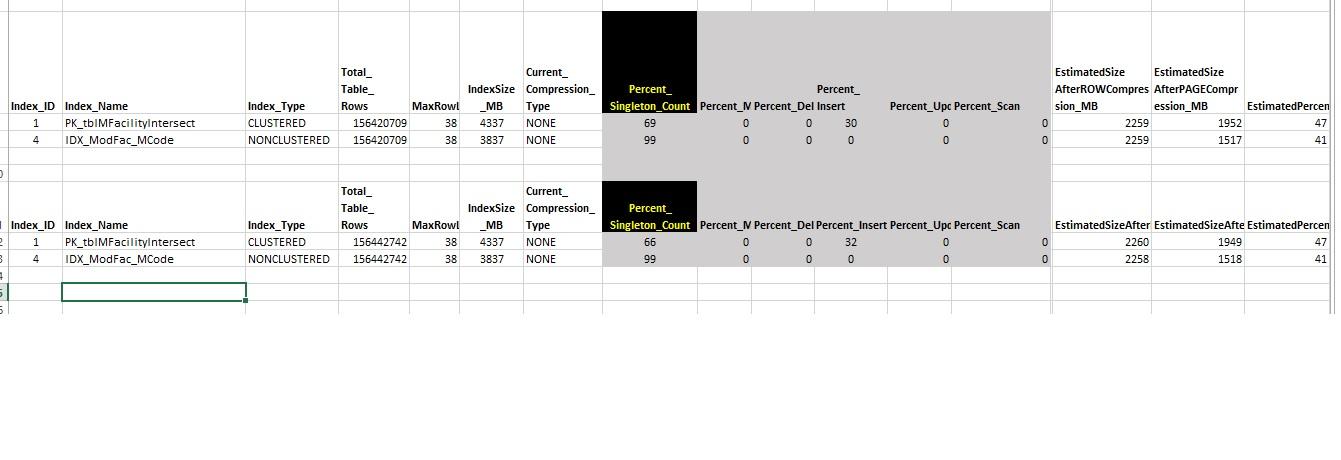
as far as the mentioned usage of the table is concerned, this is what the indexes' usage stats are:

Likes to play Chess
- VoldemarG wrote:
Thanks everyone for your valuable input!
as far as the mentioned usage of the table is concerned, this is what the indexes' usage stats are:
I assume it's a truncation on the screen but I'll ask anyway... is the max row length of the clustered index actually only 38 bytes?
I also thought you said that this table was replaced every day... why then does it suffer any inserts? Or are the inserts in the graphic just from the original population of the table?
Any chance of you posting the CREATE TABLE and the indexes for this table? And, just to be sure about the inserts, could you post the logical fragmentation values for the two indexes?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
here is a nice ref:
by Brent Ozar
https://www.brentozar.com/archive/2020/10/want-to-use-columnstore-indexes-take-the-columnscore-test/
or direct https://columnscore.com/
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
yes, only 38 max length.
2 cols only.
Likes to play Chess
-
I attached an Excel file with all the stats and details.
Likes to play Chess
-
thats all pretty and so on. but what tests did you do so far - and what was the performance difference between loading the data onto that table
- table with no compression (and separately also time to create the clustered index after the load)
- table with row compression (and separately also time to create the clustered index after the load)
- table with page compression (and separately also time to create the clustered index after the load)
- table with clustered index created
- table with clustered index and with no compression
- table with clustered index and with row compression
- table with clustered index and with page compression
- table with clustered columnstore index
and what was the performance difference of the queries you do for the particular cases below?
- table with clustered index and with no compression
- table with clustered index and with row compression
- table with clustered index and with page compression
- table with clustered columnstore index
and this not to mention all the bad practices you have on your code (4 name convention, nolock)
FacilityID - Decimal (12, 0) - takes 9 bytes - better to use a bigint - 8 bytes so I would look at this particular column to see if the change is feasible (other tables would require a similar change so the datatype matches that of the lookup table as this would potentially save some space.
-
Yes, am engaging right now into doing the test you mentioned.
thank you.
I was just attaching the Excel file to answer Jeff's questions.
Regarding some best practices/col datatypes... useful info, too, but it won't be easy to promote something like a column type change or removing sp_ from sp name, and other things, I know. It is particularly Compression/Columnstore decision I am trying to make on this table. Will be doing testing religiously all night, as Federico kindly reminded.
Likes to play Chess
- frederico_fonseca wrote:
thats all pretty and so on. but what tests did you do so far - and what was the performance difference between loading the data onto that table
- table with no compression (and separately also time to create the clustered index after the load)
- table with row compression (and separately also time to create the clustered index after the load)
- table with page compression (and separately also time to create the clustered index after the load)
You should always create the clustered index before you load the table (typically only the clus index first, although there may be times when it's also better to create non-clus index(es) before the load).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- frederico_fonseca wrote:
FacilityID - Decimal (12, 0) - takes 9 bytes - better to use a bigint - 8 bytes so I would look at this particular column to see if the change is feasible (other tables would require a similar change so the datatype matches that of the lookup table as this would potentially save some space.
No, it won't use 9 bytes under row compression unless it truly needs all 9 bytes. Row compression should automatically be used for most tables.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:frederico_fonseca wrote:
thats all pretty and so on. but what tests did you do so far - and what was the performance difference between loading the data onto that table
- table with no compression (and separately also time to create the clustered index after the load)
- table with row compression (and separately also time to create the clustered index after the load)
- table with page compression (and separately also time to create the clustered index after the load)
You should always create the clustered index before you load the table (typically only the clus index first, although there may be times when it's also better to create non-clus index(es) before the load).
As with most things it depends - I had cases where creating the index after the load was faster than doing load with the index on.
And as such testing as I suggested is the way to check it.
- ScottPletcher wrote:frederico_fonseca wrote:
FacilityID - Decimal (12, 0) - takes 9 bytes - better to use a bigint - 8 bytes so I would look at this particular column to see if the change is feasible (other tables would require a similar change so the datatype matches that of the lookup table as this would potentially save some space.
No, it won't use 9 bytes under row compression unless it truly needs all 9 bytes. Row compression should automatically be used for most tables.
going this route then bigint won't use the 8 bytes either unless it needs to do it.
and Row Compression is only enabled if the table/index is defined to have it (either on creation or through a rebuild), and is most cases in my experience using Page Compression would be better than row compression.
but maybe you were referring to vardecimal storage which is enable by default on the database - but this is not the same as compression.
Viewing 15 posts - 1 through 15 (of 25 total)
You must be logged in to reply to this topic. Login to reply