Clustered Index Scan vs Seek
-
Hi,
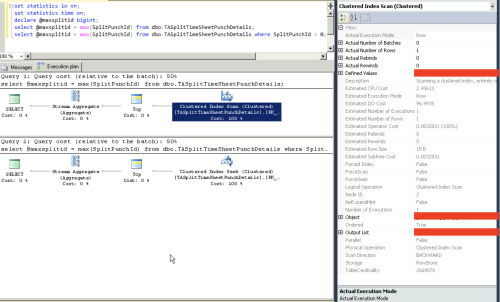
I have a table with an Id field. It is NOT auto increment. Every time we insert the new rows, we get Max(id) and increment by 1. When looking at the execution plan, it says "Clustered Index scan". But, the cost doesn't seem to be high. It is like 1% of the total cost. If I change the query to get max(id) where Id > 0, the execution plan changes to "Clustered Index Seek". But the query cost is still 1%. There is no change.
My question is does it make any difference performance wise to change the queries to include where clause with Id > 0?
Thank you,
Sridhar. -
Not seeing the query or the structure, my answer is going to be vague.
In general, yes. Situationally, a seek is better than a scan. However, it really depends on the situation and since I don't know the situation at all, we may not be in the general position.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Hi Grant,
It is a simple query. Let’s say I have table A with columns Id, Empno, Punchdate. The primary key is on Id field. It is not set as auto increment for some other reasons. When we need to insert a new row, we get maxid as follows
Select max(id) from A;
If I look at execution plan, it says Clustered index scan.
If I change the query as
Select max(id) from A where id > 0, the execution plan says it uses clustered index seek.
I am curious to know if there is a performance difference? The cost estimate % is same for both queries.
Thank you.
Sridhar.
-
The real key (no pun intended) is that the method you're using to do such an increment is prone to problems. I strongly recommend that find a better way. For example, SQL Server 2012 and up does have the ability to use SEQUENCEs.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff, I will look into that. But, I am still curious to know if there is a performance difference between the two queries.
Thank you.
Sridhar. -
If there is any (non-filtered) index keyed first on id, then MAX(id) will do an index seek/lookup. Internally it could officially be a scan, but it will be a scan with the equivalent of top (1), so it's the same performance-wise either way.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Sridhar-137443 - Tuesday, December 4, 2018 9:22 PM
The key is to measure the query performance with and without the WHERE clause. The cost estimates in the plan are just that, estimates. You need the actual measurements to know which is actually working better.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
It is doing an index scan but it isn't doing a full index scan. It's doing a VERY limited range scan.
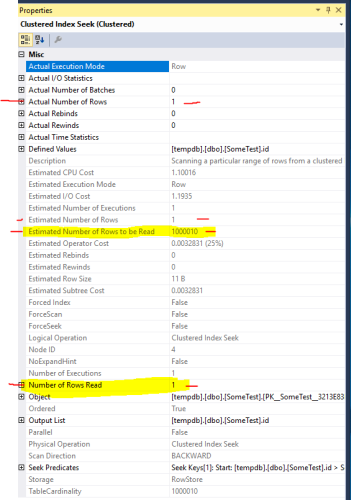
SQL Server knows that ID is the clustered key... So odds are it can go directly to the "last" leaf level page, faster than it can do a seek.If you kook at the "actual" execution plan and hover over the Clustered Index Scan node and you should see a) "Estimated Rows to be Read" = row count of your table and b) "Number of Rows Read" = 1...
Right click the Clustered Index Scan node and choose Properties... You should see "BACKWARD" as the scan direction.Going back to the old "think of an index like an old phone directory" analogy... If you know the number is the very last number in the directory, you don't have to go through the hassle of using the index to find the listing by using the alphabetical or numerical sequence... You just jump to the last entry of the last page.
-
Here's a quick test to verify...
USE tempdb;
GOCREATE TABLE dbo.SomeTest (id INT NOT NULL PRIMARY KEY CLUSTERED);
WITH
cte_n1 (n) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) n (n)),
cte_n2 (n) AS (SELECT 1 FROM cte_n1 a CROSS JOIN cte_n1 b),
cte_n3 (n) AS (SELECT 1 FROM cte_n2 a CROSS JOIN cte_n2 b),
cte_Tally (n) AS (
SELECT TOP (1000000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM
cte_n3 a CROSS JOIN cte_n3 b
)
INSERT dbo.SomeTest (id)
SELECT
t.n
FROM
cte_Tally t;-- do a CTRL+M to turn on Actual Execution Plan...
SET STATISTICS IO ON;
INSERT dbo.SomeTest (id)
SELECT
MAX(st.id) + 1
FROM
dbo.SomeTest st;
SET STATISTICS IO OFF;-- Let's see if TOP(1) ... ORDER BY... does anything differnt.
SET STATISTICS IO ON;
INSERT dbo.SomeTest (id)
SELECT TOP (1)
st.id + 1
FROM
dbo.SomeTest st
ORDER BY
st.id DESC;
SET STATISTICS IO OFF;DROP TABLE dbo.SomeTest;
-
Hi Jason, Thank you for detailed explanation. I ran the query and turned on Actual Execution Mode. Following are the results. I see that the Estimated number of rows is actually 1 and Actual number of rows is also 1. The Scan Operation is Backwards like you said.
So, if I understand this right, there won't be any difference between the two queries. Is that true or am I missing anything?

- Sridhar-137443 - Wednesday, December 5, 2018 8:23 PM
There's a difference between "Number of Rows" and "Number of Rows Read". I was referring to the later. That said, I'm testing on SQL Server 2017 and I'm not certain when that property was added. I was thinking 2012 but apparently not...
As for differences... Obviously there are differences... One has a Clustered Index Scan and the other has a Clustered Index Seek. The real question is, is there a meaningful performance difference? To that, I'd say probably not. At least nothing you'd every be able to notice in the real world.
That said, unless you have an actual reason to do so, I would try to avoid intentionally doing things to "trick" the optimizer. The optimizer chose to do a scan because the algorithm calculated that it has the lowest cost or the two options. (just my own 2 cents)I updated the insert queries to look like this...
-- do a CTRL+M to turn on Actual Execution Plan...
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
GO
SET STATISTICS IO ON;
INSERT dbo.SomeTest (id)
SELECT
MAX(st.id) + 1
FROM
dbo.SomeTest st;
SET STATISTICS IO OFF;
GO-- Let's see if TOP(1) ... ORDER BY... does anything differnt.
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
GO
SET STATISTICS IO ON;
INSERT dbo.SomeTest (id)
SELECT TOP (1)
st.id + 1
FROM
dbo.SomeTest st
ORDER BY
st.id DESC;
SET STATISTICS IO OFF;
GO-- See what impact adding a WHERE clause has.
SET STATISTICS IO ON;
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
GO
INSERT dbo.SomeTest (id)
SELECT
MAX(st.id) + 1
FROM
dbo.SomeTest st
WHERE
st.id > 0
SET STATISTICS IO OFF;
GO
Table 'SomeTest'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SomeTest'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SomeTest'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.The key thing to take away is the fact that not all scans are created equally. There's a world of difference between a full index scan, that scans every leaf level page of the index and an ordered range scan that only needs to scan a few pages. Simple existence of a scan operator in the execution plan isn't necessarily a bad thing You have to dig a little deeper...
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply