Clarification on the database design process
-
I was reading the book: "Database Design: For Mere Mortals" by Michael J.Hernandez. In it, he goes into detail on the database design process. There is a section where he summarises it as best as he could:
"Next we looked at an overview of the entire database design process. The process was consolidated into the following phases to provide you with a clear picture of the general steps involved in designing a database.
1. Define a mission statement and mission objectives for the database. The mission statement defines the purpose of the database, and the mission objectives define the tasks that are to be performed by users against the data in the database."
This is straightforward to understand.
"2. Analyse the current database. You identify your organisation's data requirements by reviewing the way your organisation currently collects and presents its data and by conducting interviews with users and management to determine how they use the database on a daily basis."
I'm curious to know what sort of information do users and management commonly provide here. How could the way they use the database affect the data requirements?.
"3. Create the data structures. You establish tables by identifying the subjects that the database will track. Next, you associate each table with fields that represent distinct characteristics of the table’s subject and designate a particular field (or group of fields) as the primary key. You then establish field specifications for every field in the table.
4. Determine and establish table relationships. You identify relationships that exist between the tables in the database and establish the logical connection for each relationship using primary keys and foreign keys or by using linking tables. Then you set the appropriate characteristics for each relationship."
ScottPletcher wrote:..a "data dictionary"
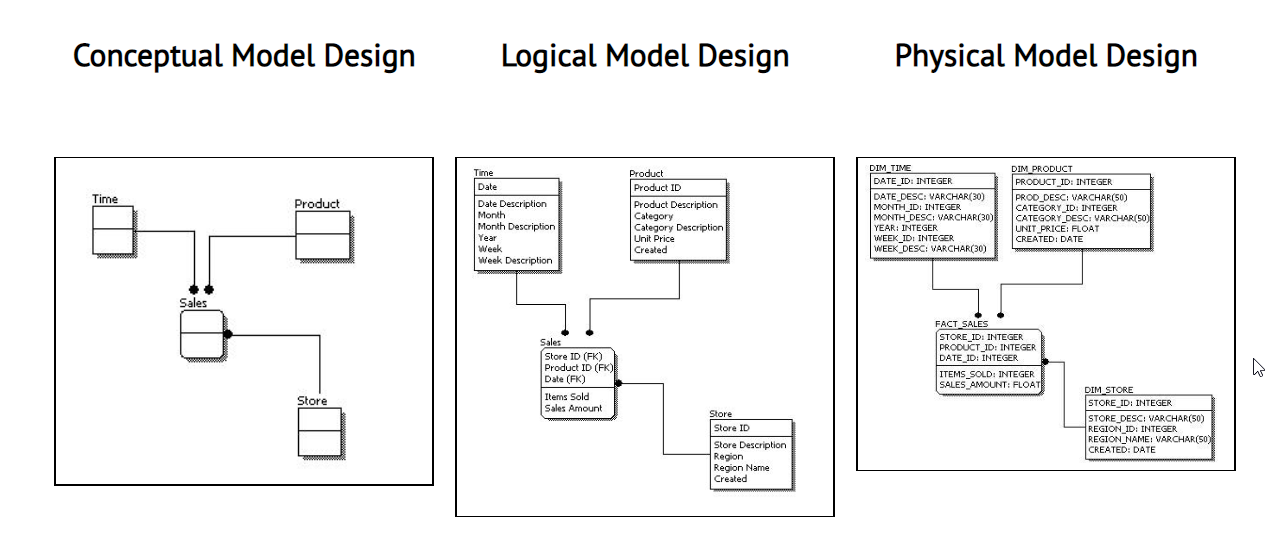
For steps 3 and 4 I’m not sure which one the data dictionary would come in and where the following models should be:
I saw this picture on this stackoverflow thread:

"5. Determine and define business rules. You conduct interviews with users and management to identify constraints that must be imposed upon the data in the database. The manner in which your organisation views and uses its data typically determines the types of constraints you must impose on the database. You then declare these constraints as business rules, and they will serve to establish various levels of data integrity."
What are some examples of some common constraints?
"6. Determine and establish views. You interview users and management to identify the various ways they work with the data in the database. When your interviews are complete, you establish views as appropriate. You define each view using the appropriate tables and fields and establish criteria for those views that must display a limited or finite set of records."
Regarding views he goes on to write:
"You may find, for example, that many users require detailed information to perform their work, whereas others need only summary information to help them make strategic decisions for the organisation. Each group of users must access information in very specific ways, and you can use views to accommodate these situations."
Is a view an entirely separate table (outside of the database model) that has no relationship with the normalised tables?. Does it only work as a lookup summary table of some sorts.
"7. Review data integrity. This phase involves four steps. First, you review each table to ensure that it meets proper design criteria. Second, you review and check all field specifications. Third, you test the validity of each relationship. Fourth, you review and confirm the business rules."
I guess here you cross check with the guidelines and test to check data is correct when queried.
Thanks in advance
-
"5. Determine and define business rules. You conduct interviews with users and management to identify constraints that must be imposed upon the data in the database. The manner in which your organisation views and uses its data typically determines the types of constraints you must impose on the database. You then declare these constraints as business rules, and they will serve to establish various levels of data integrity."
What are some examples of some common constraints?
Constraints are often specific to the industry, the specific business, or the entity in question.
Constraints may be as simple as this value must be >= X and < Y (e.g., a batch or container size)
Constraints may be things like are invoice numbers or accounting codes always start with specific sets of letters, or have to be in a specific range for a specific department.
U.S. zip codes are always 5 digits with an optional 4-digit extension.
Business may limit what states/countries are allowed.
You may constraint available genders or ages -- there probably won't be any people > 150 years old. Business may require a minimum age.
Constraints for valid values for a column are often handled as foreign keys to lookup tables, which can server the dual purpose of a constraint and a list to be used for UIs.
-
"You may find, for example, that many users require detailed information to perform their work, whereas others need only summary information to help them make strategic decisions for the organisation. Each group of users must access information in very specific ways, and you can use views to accommodate these situations."
Is a view an entirely separate table (outside of the database model) that has no relationship with the normalised tables?. Does it only work as a lookup summary table of some sorts.
The ANSI standard doesn't dictate the physical implementation of views. I think most RDBMS, including MSSQL, treat "normal" views like a stored query rather than a copy of data. Indexed views in MSSQL or materialized views in other RDBMS actually maintain & store a copy of the data defined by the view.
A view is defined by queries on tables, normalized or not. In MSSQL, if a view is defined w/ schemabinding, the table cannot be dropped or modified w/o either dropping the view or altering it to not use schemabinding.
A view provides a way (much like a stored procedure, but w/o parameters) to provide a predefined query that can use joins, unions, CTEs, functions, where clause, etc. to provide specific data. One can use that to control permissions & limit access to certain tables/columns, provide users who aren't experts at SQL w/ a simple way to query the database, or define static queries. One should avoid layering views (querying another view within a view) as that tends to confuse the query engine & interfere with it's ability to optimize queries.
-
The conceptual model is too high level for data dictionary -- it's just a definition of entities. You'll often find that evaluating attributes sometimes leads to a better understanding of the entities & revising the defined entities (conceptual model)
Data dictionary applies to both the logical model & the physical model. The logical data dictionary is a tool to verify, document, & communicate understanding of the domain with users, and then as an input to the physical design. The physical data dictionary serves as documentation for consumers and maintainers of the database.
-
(2) "How could the way they use the database affect the data requirements?" It doesn't really, so your skepticism is correct. Hopefully the author just worded this somewhat awkwardly. What you're finding out if how they use the existing data. And, just as importantly, how they'd like to use the data but can't due to current system limitations.
(3) I generally accept the author's approach, as I'm not a stickler for rigid processes. But when gathering logical data requirements and doing logical design, you are not dealing with "tables". I'll admit "entity" instead can be awkward to use. If it is to use, or more critically your business people, then use some other name: object, thing, whatever.
That said, even I'm not as strict on "columns". If you want to use "columns" (rather than attributes) on the logical side, I say go ahead. The vast majority of business people are extremely familiar with spreadsheets so columns is a common term for them and they understand it.
Keep in mind that indexes do not exist at the logical level. Nor is performance any consideration at all. The idea is to get complete and accurate data requirements, regardless of how well current physical implements can deal with them or not.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
(5) (A) Customers with less than "Excellent" credit rating must get approval for any order over $500 (or whatever amount) before it is processed, or pay for the order in full in advance. (B) Customers must obtain pre-authorization before being able to do any Returns. (C) Customers may place new orders only on normal work days only, not on holidays/weekends (some companies may have different rules). (D) New inventory added to the warehouse must be barcode scanned before being placed into bins. (E) Order quantity must be between 1 and 99,999 (or whatever); exceptions require a person to override to allow. ...
You'll also have basic attribute rules:
(1) Sex code must 'F' or 'M' (perhaps now 'O' could be added)
(2) U.S. telephone numbers must be 10 digits (i.e. must include area code). ...
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
(6) A view is a customized set of columns or computed values from existing tables. The view may leave out some columns and may create new columns. What goes in the view depends on what the people using the view need to see. Typically it's a "need to know" thing. If they don't need certain info for their jobs, they don't see that data.
Take info on other employees, for example. Typically you'll have a phone directory that gives everyone's extension, department, etc.. But naturally salary nor birth date appear there. An extremely limited number of people in the company should see this data. For everyone else, any view of employee data doesn't include either of them.
So, when might a new column be created and shown? For those emps who do need to see birth date, age is usually added. That column is not in any table but it would be in the view.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ratbak wrote:
Constraints may be things like are invoice numbers or accounting codes always start with specific sets of letters, or have to be in a specific range for a specific department.
Thanks, I like the examples you've listed. Just curious, are the constraints mentioned in this stage only referring to the raw data (so no calculated columns or anything)?.
Regarding Step 5 I have no follow up questions. You answered it perfectly.
I got a little confused reading this sentence though:
ratbak wrote:The conceptual model is too high level for data dictionary
Perhaps you meant 'low' instead of 'high' or I misunderstood. Having read the second paragraph I understood it as the conceptual model is too basic and doesn't contain enough detail to have a data dictionary. The logical and physical models however should have data dictionaries. Please correct me if I'm wrong.
ScottPletcher wrote:What you're finding out if how they use the existing data. And, just as importantly, how they'd like to use the data
I'm thinking of possible reasons in my head but honestly can't think of any but I also have no prior experience of doing this so I have nothing to compare things to. I referred back to the book and the only additional things written are:
"The analysis also involves reviewing the way your organization currently collects and presents the data. You examine how your organization uses paper forms and reports or desktop applications to collect data and present data. Finally, you take into account how your organization uses its data on the Internet and review any web-based applications that work with the database. Another part of the analysis involves conducting interviews with users and management to identify how they interact with the database on a daily basis. As the database developer, you ask users how they work with the database and what their information requirements are at the current time. You then interview management personnel and ask them about the information they currently receive and their perception of the overall information requirements for the organization. These interviews are an important component of your analysis because the questions you ask (or don’t ask) will have a great impact on your final database structure. You must conduct full and complete interviews in a timely, practical, and effective manner if you are to design a database that truly meets your organization’s information needs."
I'm struggling to find examples for steps 2 and identify how the answers acquired in step 2 differ from 5 and 6 (I totally understand the differences between steps 5 and 6 now though). Because in step 2 if the person finds out that users typically query for such data then that answers step 6. Or in step 2 you discover that users are only interested in data from certain zip/postal codes then that would be an answer for step 5 as it could be a constraint for the designer to think about.
Some interesting examples here.
ScottPletcher wrote:Customers must obtain pre-authorization before being able to do any Returns.
Would this mean that you may have a column called 'pre-authorization' with either 'yes' or 'no'. If it's a 'no' then the row would not allow any 'returns' information to be held for that ID?. Similar concepts for examples C and D?.
Regarding what you all said about views:
ratbak wrote:One can use that to control permissions & limit access to certain tables/columns, provide users who aren't experts at SQL w/ a simple way to query the database, or define static queries.
ScottPletcher wrote:If they don't need certain info for their jobs, they don't see that data.
Does this mean that the user has permanent restrictions from viewing certain rows and columns so even if they tried to query the data manually (outside of the view) they would never be able to see it. If you are familiar with Power BI, then it would be identical to Row Level Security (RLS) or Object Level Security (OLS) if you are familiar with those terms.
-
views/stored procedures to hide columns from some users --Sure, you wouldn't let just anyone see a patient's Social Security Number, for example. If you did, and someone misused it, that would be ugly.
The whole "what questions are they going to ask?" part - to some degree, if you have a normalized database, they can ask whatever they want and you can answer it. May require some degree of skill writing T-SQL, but...
Oh, the PowerBI part... Row-Level Security was introduced in SQL Server a long time ago. PowerBI just implemented it too. (For example, you could grant execute rights on different objects (tables/columns/views/stored procedures) to different groups, based on what groups they're in. Same idea in PowerBI.
- pietlinden wrote:
views/stored procedures to hide columns from some users --Sure, you wouldn't let just anyone see a patient's Social Security Number, for example. If you did, and someone misused it, that would be ugly.
Please correct me if I'm wrong but this is how I think it works based on the information provided:
If a User let's call him 'Mark' did not have the rights to view the employees 'Social Security Number's' (SSN). A view would be created for Mark (and those with the same restrictions) which does not contain the actual column consisting of SSNs. Mark will will not have access to the original tables (used to create the view) either as restriction would be applied to it so he cannot use SQL to query for the SSN. Alternatively OLS could be applied to the table consisting of the SSNs and there would be no need for a VIEW.
Maybe I'm way off.
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply