Calculating Total # Days Per Year with Start Date to Today
-
Have you considered using a Calendar or Tally Table?
Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
Can't you just group by YEAR(date) counting distinct dates?
--Vadim R.
-
If you have a calendar table - or a date dimension table:
Declare @startDate date = '2017-05-07'
, @endDate date = getdate();
Select dd.[Year]
, [Days] = count(*)
From dbo.DimDate dd
Where dd.Date >= @startDate
And dd.Date <= @endDate
Group By
dd.[Year]
Order By
dd.[Year];If you don't have a calendar/date dimension - you can do something like this:
Declare @startDate date = '2017-05-07'
, @endDate date = getdate();
With years
As (
Select [Year] = year(@startDate) + n.Number
From (Select row_number() over(Order By @@spid) - 1 As rn From sys.all_columns ac) As n(Number)
Where year(@startDate) + n.Number <= year(getdate())
)
Select [Year]
, [Days] = datediff(day, iif([Year] = year(@startDate), @startDate, datefromparts([Year], 1, 1))
, iif([Year] = year(@endDate), dateadd(day, 1, @endDate), datefromparts([Year] + 1, 1, 1)))
From years;Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
Brilliant! Thank you Jeffrey.
- Jeffrey Williams wrote:
If you don't have a calendar/date dimension - you can do something like this:
Declare @startDate date = '2017-05-07'
, @endDate date = getdate();
With years
As (
Select [Year] = year(@startDate) + n.Number
From (Select row_number() over(Order By @@spid) - 1 As rn From sys.all_columns ac) As n(Number)
Where year(@startDate) + n.Number <= year(getdate())
)
Select [Year]
, [Days] = datediff(day, iif([Year] = year(@startDate), @startDate, datefromparts([Year], 1, 1))
, iif([Year] = year(@endDate), dateadd(day, 1, @endDate), datefromparts([Year] + 1, 1, 1)))
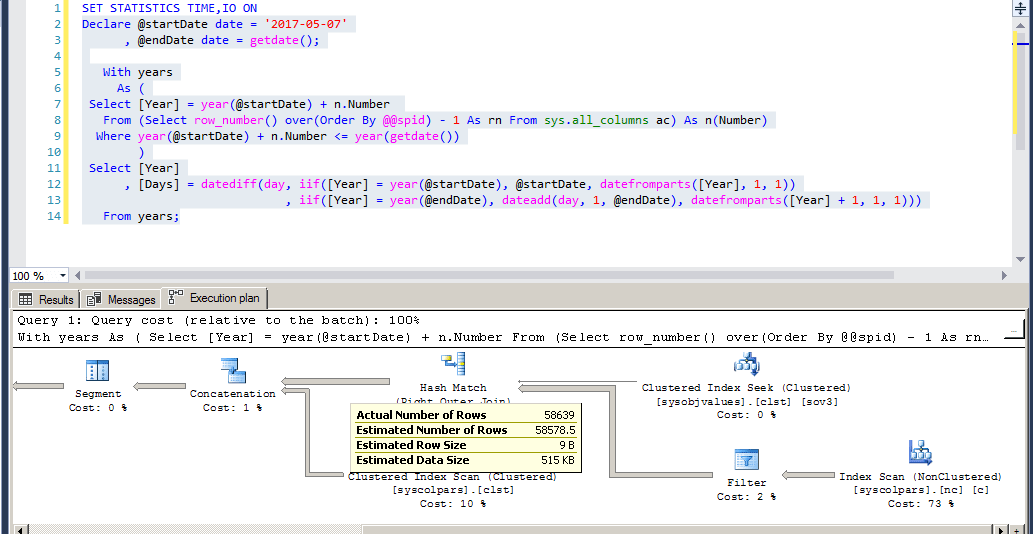
From years;Oh, be careful now... that has a nasty little problem in it. I ran that in one of my databases at work and it turns out that you have all rows of sys.all_columns being materialized behind the scenes. It has to materialize all of the internal rows before it can calculate the date limits. On the database I used, that resulted in 58,639 rows being read and took 113 ms to resolve (imagine running this against just 10,000 rows... it would take 18.8 minutes).

That resulted in 447+3,592+3 logical reads (4,042 pages of data read) or 31.6 MB of memory I/O (4,042 pages/128.0 pages per MB). And, remember, you're just calculating for a 3 row output.
(3 rows affected)
Table 'syscolpars'. Scan count 1, logical reads 447, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'syscolpars'. Scan count 1, logical reads 3592, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'sysobjvalues'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 125 ms, elapsed time = 113 ms.
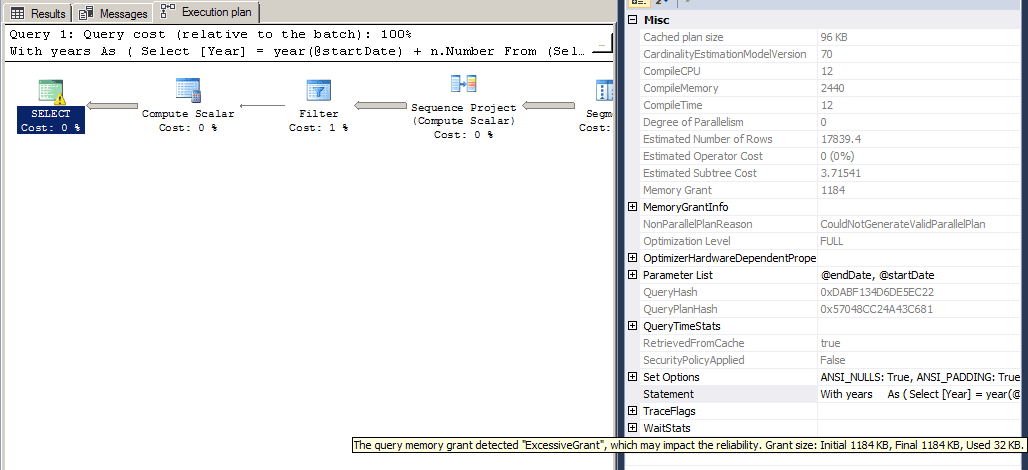
It gets worse... it also resulted in an "Excessive Memory Grant"
If we change modes a little and calculate the number of year boundaries (+1) instead of actual days and use Itzik Ben-Gan's cCTE (Cascading CTE) method for generating the numeric row source to create the dates from (and it generates absolutely ZERO reads), we end up with code that looks like this (which can easily be converted to an iTVF)...
--===== These would be parameters in an iTVF (Inline Table Valued Function)
DECLARE @pStartDT DATE ='2017-05-07'
,@pEndDT DATE = GETDATE()
;
WITH
--=========== This generates values from 0 up to 9999 but is limited by the TOP calculation
-- to just 1 row per year boundary + 1
E1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1))E0(N))
,Tally(N) AS (SELECT TOP (DATEDIFF(yy,@pStartDT,@pEndDT)+1)
N = ROW_NUMBER() OVER (ORDER BY(SELECT NULL))-1
FROM E1 a, E1 b, E1 C, E1 D)
--=========== This uses the row source from above to Jan 1st of each year boundary.
-- The DATENAME trick is what causes the 1st of the year for each date.
,cteYearDates AS
(
SELECT YearStartDT = DATEADD(yy,t.N ,DATENAME(yy,@pStartDT))
,YearEndDT = DATEADD(yy,t.N+1,DATENAME(yy,@pStartDT))
FROM Tally t
)
--===== This just returns the year from the dates produce above and does the necessary
-- comparisons to calculate the days for each year in the range paying attention
-- the the required offset for the start and end years. The middle years are just
-- a full year DATEDIFF for each row from above. Again, just 1 row per year.
SELECT Year = DATEPART(yy,YearStartDT)
,Days = CASE
WHEN @pStartDT >= YearStartDT THEN DATEDIFF(dd,@pStartDT,YearEndDT)
WHEN @pEndDT < YearEndDT THEN DATEDIFF(dd,YearStartDT,@pEndDT)
ELSE DATEDIFF(dd,YearStartDT,YearEndDT)
END
FROM cteYearDates
ORDER BY Year
;That returns in much less than a millisecond of CPU or Duration (actually, it was in less than a microsecond according to SQL Profiler) and ZERO reads.
(3 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
And, as usual, we end up with tutorial comments that are longer then the code. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - rVadim wrote:
Can't you just group by YEAR(date) counting distinct dates?
Yes but, as you can see in my comments in the previous post, it's comparatively horribly slow.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Not so sure it is as bad as you stated, here is what it shows on my system. With that said - I have started moving away from using sys.all_columns and should have updated this code (see following):
(3 rows affected)
Table 'syscolpars'. Scan count 1, logical reads 443, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'syscolpars'. Scan count 1, logical reads 167, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'sysobjvalues'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 25 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.I do agree that an inline tally would be better...however I would go further and determine the maximum number needed. For something like this I would validate whether or not we needed an open ended number of years - or just 2 or 3 years. If we would only ever be looking at a max of 3 years I would not even bother with the inline tally:
Declare @startDate date = '2017-12-07'
, @endDate date = getdate();
With years
As (
Select [Year] = year(@startDate) + n.Number
From (Values (0), (1), (2)) As n(Number)
)
Select [Year]
, [Days] = datediff(day, iif([Year] = year(@startDate), @startDate, datefromparts([Year], 1, 1))
, iif([Year] = year(@endDate), dateadd(day, 1, @endDate), datefromparts([Year] + 1, 1, 1)))
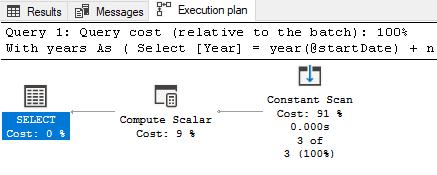
From years;This results in this plan:
This has no worktables at all...
Now - if you need to be able to do this across more years, this method would probably be better:
Declare @startDate date = '1900-12-07'
, @endDate date = getdate();
With t(n)
As (
Select *
From (
Values (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)
, (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)) As t(n)
)
, years
As (
Select [Year] = year(@startDate) + n.Number
From (Select row_number() over(Order By @@spid) - 1 As rn From t t1, t t2) n(Number)
Where year(@startDate) + n.Number <= year(getdate())
)
Select [Year]
, [Days] = datediff(day, iif([Year] = year(@startDate), @startDate, datefromparts([Year], 1, 1))
, iif([Year] = year(@endDate), dateadd(day, 1, @endDate), datefromparts([Year] + 1, 1, 1)))
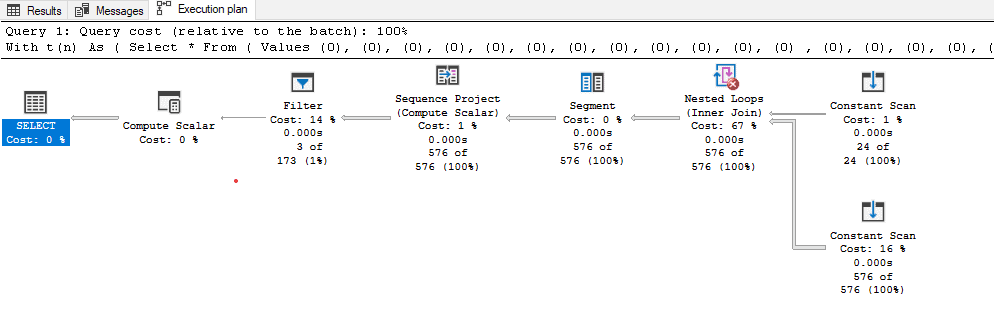
From years;In the above - we start from 1900 through current and we get this plan:
Again - no worktables and 0ms CPU and IO times.
Just be aware that you will see a decrease in performance as soon as you add another table to the 'tally' above. If you do this:
From (Select row_number() over(Order By @@spid) - 1 As rn From t t1, t t2, t t3) n(Number)
It will increase to 16ms CPU and 4ms IO (on my system, yours will probably be different) - and this isn't needed to get the appropriate number of rows returned. Even if you change the filter to n.Number < datediff(year, @startDate, @endDate) + 1 you still get the same plan.
If you need more numbers...just add another row to the 't' CTE. With just 2 rows of 12 we get 576 rows...add another 12 and we get 1,296 numbers and the same exact plan and performance. Increase the number of zeros to 15 x 3 = 45 zeros and you get 2,025 numbers with no additional overhead.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
This is a great excuse to write a recursive query 🙂
DECLARE @InputDate datetime;
DECLARE @InputYear smallint, @EndYear smallint;
-- test date:
SELECT @InputDate = '2011-05-04', @EndYear = YEAR(getdate());
-- Fun with recursion!
WITH YearLoopr AS
(
SELECT YEAR(@InputDate) AS [Year],
datediff(day, @InputDate, datefromparts(YEAR(@InputDate) + 1, 1, 1)) AS [DaysThisYear]
UNION ALL
SELECT yl.[Year] + 1,
CASE WHEN yl.[Year] + 1 = @EndYear THEN datediff(day, datefromparts(yl.[Year] + 1, 1, 1), getdate())
ELSE datediff(day, datefromparts(yl.[Year] + 1, 1, 1), datefromparts(yl.[Year] + 2, 1, 1))
END
FROM YearLoopr yl
WHERE [Year] <= @EndYear - 1
)
SELECT * FROM YearLoopr;Eddie Wuerch
MCM: SQL - Eddie Wuerch wrote:
This is a great excuse to write a recursive query 🙂
Heh... no it's not. ( https://www.sqlservercentral.com/articles/hidden-rbar-counting-with-recursive-ctes )
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeffrey Williams wrote:
Not so sure it is as bad as you stated, here is what it shows on my system.
The key here is that you have to make it system agnostic. Not everyone will have such a small sys.all_columns.
Jeffrey Williams wrote:With that said - I have started moving away from using sys.all_columns ...
I don't actually use sys.all_columns for work so you'll get no argument from me there. To be sure, the only reason why I use sys.all_columns on forums is because of two things.
- A whole lot of people crab about the fnTally function and the Tally Table because they're not allowed to create objects in the database. With that, I got tired of rewriting code to use sys.all_columns.
- Everyone using SQL 2005 and above has a sys.all_columns.
I usually use a programmable fnTally function if I want zero reads and a Tally Table if I want the maximum in performance even though it produces reads. Of course, you can run into the same problems with either of those, similar to the way you did with sys.all_columns, if you don't properly constrain the upper limit of the rouw source early.
Jeffrey Williams wrote:I do agree that an inline tally would be better...however I would go further and determine the maximum number needed. For something like this I would validate whether or not we needed an open ended number of years - or just 2 or 3 years. If we would only ever be looking at a max of 3 years I would not even bother with the inline tally:
I just happened to use an inline Tally because people have also taken to crabbin' about sys.all_columns, which is super easy to use, but I agree.
I strongly recommend against such an esoteric limit as you suggest, though. There are 9999-1753 0r 8,246 year "boundaries" in the DATETIME datatype. A 4 way by 10 row cCTE is very convenient to cover that and, like I said, it doesn't matter how few rows you use, you'll run into excessive reads or excessive CPU usage (depending on the row source you use for the Pseudo-Cursor) if you don't limit it. Just using an inline cCTE or fnTally function or Tally table will not solve that problem.
The easiest way to solve that problem is simply to calculate the number of periods you want to return (years in this case) and use the result of that calculation in a TOP() expression.
Jeffrey Williams wrote:Now - if you need to be able to do this across more years, this method would probably be better:
Declare @startDate date = '1900-12-07'
, @endDate date = getdate();
With t(n)
As (
Select *
From (
Values (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)
, (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0), (0)) As t(n)
)
, years
As (
Select [Year] = year(@startDate) + n.Number
From (Select row_number() over(Order By @@spid) - 1 As rn From t t1, t t2) n(Number)
Where year(@startDate) + n.Number <= year(getdate())
)
Select [Year]
, [Days] = datediff(day, iif([Year] = year(@startDate), @startDate, datefromparts([Year], 1, 1))
, iif([Year] = year(@endDate), dateadd(day, 1, @endDate), datefromparts([Year] + 1, 1, 1)))
From years;In the above - we start from 1900 through current and we get this plan:
Again - no worktables and 0ms CPU and IO times. Just be aware that you will see a decrease in performance as soon as you add another table to the 'tally' above.
That's a perfect example of the problem that I'm talking about. Your code contains an inline Tally table of just 24 rows. Because you necessarily need 120 for your example, you added a necessary CROSS JOIN and the Cartesian Product of that is 576 rows. The necessary CROSS JOIN isn't a problem. Your WHERE clause that uses it is. Because you didn't limit the number of rows early, 576 internal rows will be generated even if you only need 1 year . Instead, you calculate all 576 RNs and THEN you filter them down to 120 rows in the WHERE clause. You can even see that late filter in the execution plan you posted.
If you go back and look at the code I wrote, I don't create the limit in the WHERE clause. I create the limit very early by creating it in the TOP() expression when I'm generating the RNs so that I only generate the number of RNs that I actually need. Yes, on huge numbers, there can be a very slight overage of the rows generated but it won't even come close to the full length of the Cartesian Product.
All you need to do is use a TOP() expression to limit the number of rows (you won't need the WHERE clause after that) and you'll be good to go and it doesn't matter what your row source for the RN generation is if you do it that way.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply