Availability Group Failing Over with All Replicas Set to Manual Failover
-
I have an availability group that has failed over for 5 days straight at approximately 7am. The availability group has 5 replicas and they are all set to manual failover. AG properties are listed below:

Checking the SQL Server error log, each failover is preceded by this message:
AlwaysOn: The local replica of availability group 'XXXXXXXX' is preparing to transition to the resolving role in response to a request from the Windows Server Failover Clustering (WSFC) cluster. This is an informational message only. No user action is required.I am trying to figure out what information I should be looking for in the cluster logs.
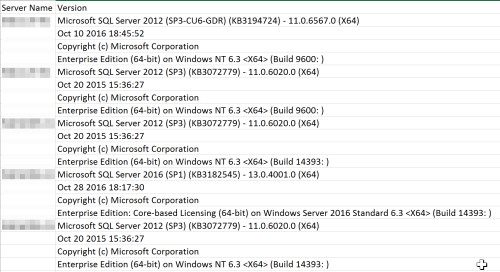
Windows and SQL version information for each replica is listed below (replicas are in the same order as the AG properties):
Let me know if additional information is required.
Thanks,
Frank -
Does it actually fail over (i.e. does another replica take on the Primary role) or is it just a brief blip?
Anything in the cluster event log at around 07.00 a.m.?
- skreebydba - Tuesday, September 19, 2017 10:38 AM
why arent your replicas all the same minimum base version??
-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
-
This is a client environment and they are planning to upgrade two of the nodes to SQL Server 2016 and fail the availability groups over one at a time to upgrade the SQL version. Once the AGs have all been failed to 2016, the remaining 2012 nodes will be removed from the cluster.
The existing SQL Server 2016 node is not being used for AGs.
The client is opening a ticket with Microsoft and I will post any information I receive from them.
-
Beatrix,
It does not fail over, just fails. The client has been able to bring it online via Failover Cluster Manager. As far as we can tell, it comes back online itself on retry if left alone.
Prior to each failure, we see messages like this:
00007f5c.00005c88::2017/09/19-12:01:25.000 ERR [RES] SQL Server Availability Group: [hadrag] ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Could not serialize the data for node 'filePath' because it contains a character (0x001F) which is not allowed in XML. To retrieve this data convert it to binary, varbinary or image data type (6842)The character , in this case 0x001F, changes but is always invalid.
In some cases, this message is preceded by information about SQL health check:
00007f5c.00005c88::2017/09/19-12:01:25.000 INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from '' to 'clean' at 2017-09-19 07:01:25.003
00007f5c.00005c88::2017/09/19-12:01:25.000 INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'resource' health state has been changed from '' to 'clean' at 2017-09-19 07:01:25.003
00007f5c.00005c88::2017/09/19-12:01:25.000 INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'query_processing' health state has been changed from '' to 'clean' at 2017-09-19 07:01:25.003
00007f5c.00005c88::2017/09/19-12:01:25.000 INFO [RES] SQL Server Availability Group: [hadrag] SQLFetch() returns -1 with following informationIn this example the SQL Server component it is failing on is io_subsystem. In other cases, SQLFetch() returns -1 for other SQL Server components.
I would love to find a commonality, but it isn't there as far as I can see.
Thanks for your reply.
- skreebydba - Wednesday, September 20, 2017 9:54 AM
Any chance you've got flaky hardware? Check the System error logs. A flaky disk controller might just freeze up for a while and then start responding again. Could be there's a fan that has failed, allowing some components to overheat...
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy)

Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply