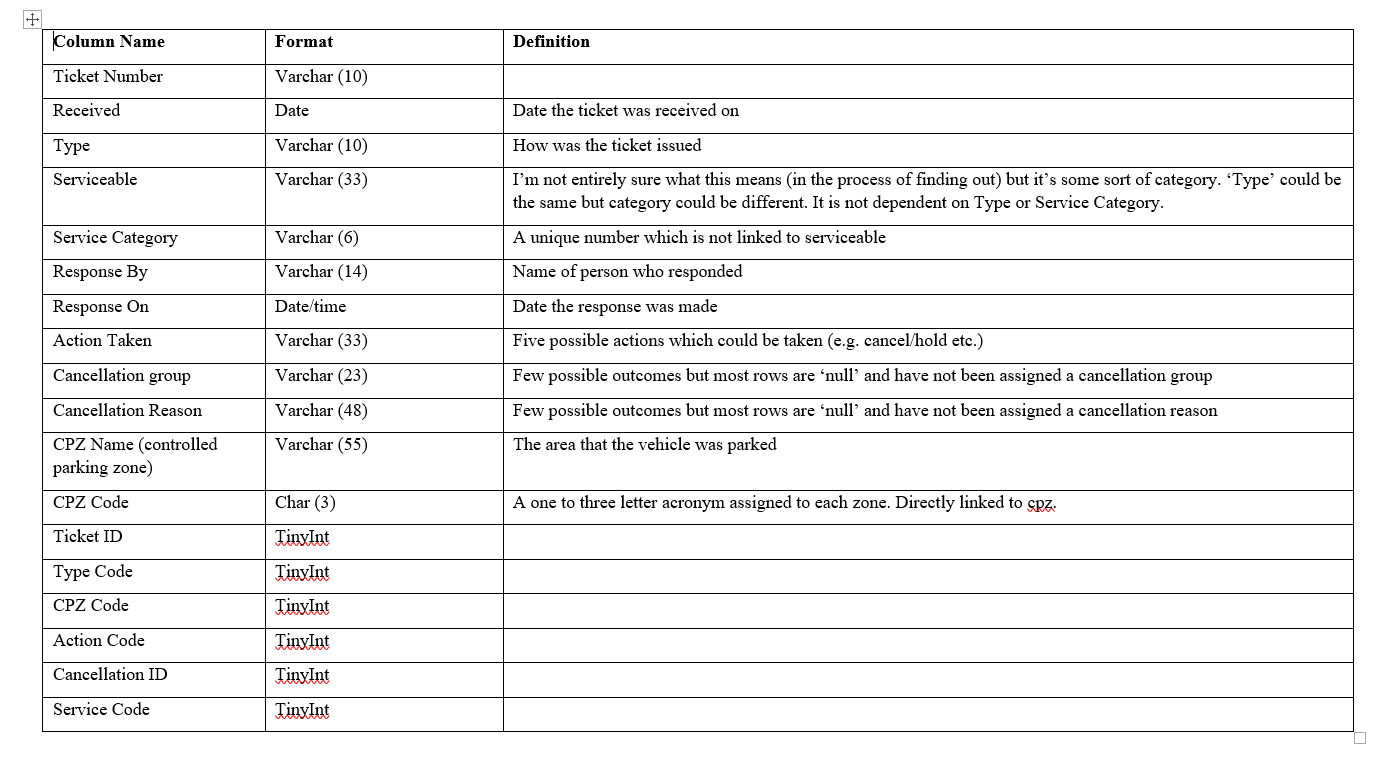
Are the data types I've chosen the best choices?
- ScottPletcher wrote:Phil Parkin wrote:
This link gives a few reasons for choosing shorter varchar lengths.
In terms of storage, CHAR(n) columns are always n characters long.
VARCHAR(n) columns are anything between 2 and (n + 2) characters, in storage terms (as varchar columns include two characters for length information).
As your data items are always 1, 2 or 3 in length, CHAR(3) will store the data more efficiently than VARCHAR(3) overall.
That also depends on whether you are using data compression or not. Typically for large amounts of data you will be, which means even char(n) columns will not store blanks after the actual value.
See what I mean, Scott? You say it's a "logical design" and you're talking about "compression" and datatypes.
This isn't a "logical" design where talking about here. The mere mention of datatypes makes in a physical design.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Mr_X wrote:
Thank you for your reply.
Jeff Moden wrote:I took a look at your spreadsheet and immediately found a pretty nasty issue... about 2/3rds of the rows have duplicated Ticket Numbers.
Scott suggested putting a 'Ticket Response ID' column I imagine this was the reason. Please correct me if I'm wrong.
[/quote]
Heh... that's too funny. Scott is normally the one to rail against the use of such things as ID columns.
What are you doing to ensure that true duplicate ticket responses are prevented? The "Ticket Response ID" column isn't going to prevent such a thing.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Mr_X wrote:
Thank you for your reply.
Jeff Moden wrote:I took a look at your spreadsheet and immediately found a pretty nasty issue... about 2/3rds of the rows have duplicated Ticket Numbers.
Scott suggested putting a 'Ticket Response ID' column I imagine this was the reason. Please correct me if I'm wrong.
Heh... that's too funny. Scott is normally the one to rail against the use of such things as ID columns.
What are you doing to ensure that true duplicate ticket responses are prevented? The "Ticket Response ID" column isn't going to prevent such a thing.[/quote]
FALSE. The ONLY thing I rail against is making the identity value the clustering key by default, as far too many people do. The clustering key is far too important to ever just default it to anything.
In particular in the case of a child table, such as this case. Ticket Response is a child table of the Ticket table. As in most such cases, the child table's clustering key should start with parent's clustering key(s).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeff Moden wrote:ScottPletcher wrote:
Remember, too, that the logical data model should be easily understood and use by business people. In fact, if possible, keep all developers out of the first one or two logical design meetings.
Done correctly, I absolutely agree. I rarely see it done correctly, though.
Indeed. It's extraordinarily rare for a logical data model to be done at all period, let alone done correctly.
And that is why there are so many just awful db (so-called) "designs". Developers are 99.9% of the time incapable of doing a logical model, partly because they just want to get to coding.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeff Moden wrote:ScottPletcher wrote:Phil Parkin wrote:
This link gives a few reasons for choosing shorter varchar lengths.
In terms of storage, CHAR(n) columns are always n characters long.
VARCHAR(n) columns are anything between 2 and (n + 2) characters, in storage terms (as varchar columns include two characters for length information).
As your data items are always 1, 2 or 3 in length, CHAR(3) will store the data more efficiently than VARCHAR(3) overall.
That also depends on whether you are using data compression or not. Typically for large amounts of data you will be, which means even char(n) columns will not store blanks after the actual value.
See what I mean, Scott? You say it's a "logical design" and you're talking about "compression" and datatypes.
This isn't a "logical" design where talking about here. The mere mention of datatypes makes in a physical design.
Quite correct. I should not have mentioned data compression at this stage.
You do specify broad data types in the logical model, like character, integer or decimal. And, if known, you should specify the data domains (the allowed values, which might be the lowest / highest value or a specific list of values).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:Jeff Moden wrote:ScottPletcher wrote:
Remember, too, that the logical data model should be easily understood and use by business people. In fact, if possible, keep all developers out of the first one or two logical design meetings.
Done correctly, I absolutely agree. I rarely see it done correctly, though.
Indeed. It's extraordinarily rare for a logical data model to be done at all period, let alone done correctly.
And that is why there are so many just awful db (so-called) "designs". Developers are 99.9% of the time incapable of doing a logical model, partly because they just want to get to coding.
ScottPletcher wrote:Jeff Moden wrote:Mr_X wrote:Thank you for your reply.
Jeff Moden wrote:I took a look at your spreadsheet and immediately found a pretty nasty issue... about 2/3rds of the rows have duplicated Ticket Numbers.
Scott suggested putting a 'Ticket Response ID' column I imagine this was the reason. Please correct me if I'm wrong.
Heh... that's too funny. Scott is normally the one to rail against the use of such things as ID columns.
What are you doing to ensure that true duplicate ticket responses are prevented? The "Ticket Response ID" column isn't going to prevent such a thing.[/quote]
FALSE. The ONLY thing I rail against is making the identity value the clustering key by default, as far too many people do. The clustering key is far too important to ever just default it to anything.
In particular in the case of a child table, such as this case. Ticket Response is a child table of the Ticket table. As in most such cases, the child table's clustering key should start with parent's clustering key(s).
But... Clustering is part of the physical implementation - not Logical Data Model. Seems you are contradicting yourself a bit here.
Having the Ticket Response ID as PK on its own does not require it to be the clustered index (neither should it be) - but having the PK made up of both the Ticket ID and the Response ID means there is a possibility of duplicate Response ID's.
Or would your "design" go through a process of ensuring that the Response ID is incremental per Ticket ID (some designs do have this as a requirement).
- frederico_fonseca wrote:ScottPletcher wrote:Jeff Moden wrote:ScottPletcher wrote:
Remember, too, that the logical data model should be easily understood and use by business people. In fact, if possible, keep all developers out of the first one or two logical design meetings.
Done correctly, I absolutely agree. I rarely see it done correctly, though.
Indeed. It's extraordinarily rare for a logical data model to be done at all period, let alone done correctly.
And that is why there are so many just awful db (so-called) "designs". Developers are 99.9% of the time incapable of doing a logical model, partly because they just want to get to coding.
ScottPletcher wrote:Jeff Moden wrote:Mr_X wrote:Thank you for your reply.
Jeff Moden wrote:I took a look at your spreadsheet and immediately found a pretty nasty issue... about 2/3rds of the rows have duplicated Ticket Numbers.
Scott suggested putting a 'Ticket Response ID' column I imagine this was the reason. Please correct me if I'm wrong.
Heh... that's too funny. Scott is normally the one to rail against the use of such things as ID columns.
What are you doing to ensure that true duplicate ticket responses are prevented? The "Ticket Response ID" column isn't going to prevent such a thing.[/quote]
FALSE. The ONLY thing I rail against is making the identity value the clustering key by default, as far too many people do. The clustering key is far too important to ever just default it to anything.
In particular in the case of a child table, such as this case. Ticket Response is a child table of the Ticket table. As in most such cases, the child table's clustering key should start with parent's clustering key(s).
But... Clustering is part of the physical implementation - not Logical Data Model. Seems you are contradicting yourself a bit here.
Having the Ticket Response ID as PK on its own does not require it to be the clustered index (neither should it be) - but having the PK made up of both the Ticket ID and the Response ID means there is a possibility of duplicate Response ID's.
Or would your "design" go through a process of ensuring that the Response ID is incremental per Ticket ID (some designs do have this as a requirement).
A PK key designation can be part of the logical model.
No, Ticket Response Id is a unique number by itself (typically physically implemented in SQL Server with an IDENTITY property).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
All that's nice but no one has identified how to identify duplicate entries for the various ticket responses possible for a given ticket number or prevent them. Or is "no duplicate" not considered to be a part of "logical design". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Does the system need to prevent duplicate responses to a Ticket? That would be complex to do at the very least.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
It's hard for me to say. Getting information from the people that supplied the data is very difficult. I've made some adjustments to the model. Here are the data types again:

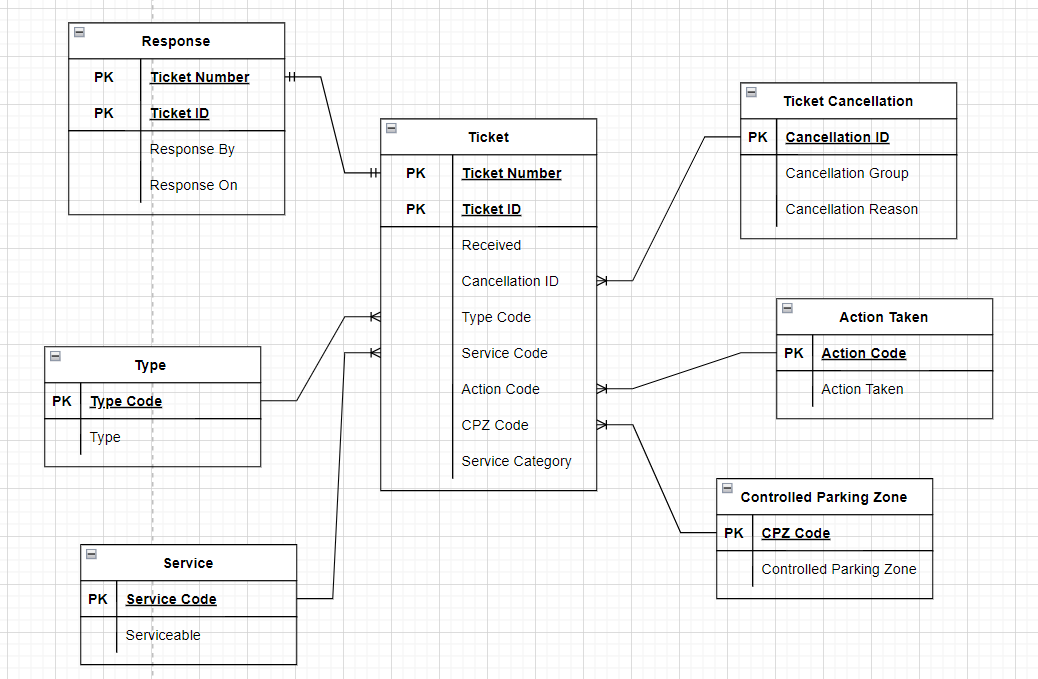
And the data model itself:
I hope it's an improvement.
-
My earlier comment on the model got lost (this site seems to do that sometimes with posts that go to a new page).
Overall I think you did an excellent job refining the model. It's not easy combining all these design ideas.
I would strongly recommend sticking with "integer" as the type. Add a domain (or range_of_values) property to limit the size rather than a data type name. Remember, the logical model is supposed to be generic, not tilted toward SQL Server.
For example, rather than "tinyint", use data type = "integer", min value = 0, max value = 255.
Ticket Id will definitely need to be at least an integer (it might even become a bigint on the physical side in SQL Server).
Since CPZ already has an 1 to 3 char alphanumeric code in use in the business, stick to that code to represent it rather than a number.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
I would strongly recommend sticking with "integer" as the type. Add a domain (or range_of_values) column to limit the size rather than a data type name. Remember, the logical model is supposed to generic, not tilted toward SQL Server.
Perhaps I misunderstood what Jeff said. I was following on from what he suggested before. If you recall:
Jeff Moden wrote:Columns like "Type", "Action Taken", Cancellation Group", and "Cancellation Reason" should be INT, SMALLINTs, or TINYINTs that point to reference tables.
But I now take it he was referring to the actual model when it is being built using SQL. So I'll be sure to change that to INT.
One thing someone said to me was that there cannot be two primary keys in a table. Is this true? if so, how can I adjust my data model to reflect this?. I understand that Ticket Number and Ticket ID make up a composite key. Should it look something like this?:
- Mr_X wrote:ScottPletcher wrote:
I would strongly recommend sticking with "integer" as the type. Add a domain (or range_of_values) column to limit the size rather than a data type name. Remember, the logical model is supposed to generic, not tilted toward SQL Server.
Perhaps I misunderstood what Jeff said. I was following on from what he suggested before. If you recall:
Jeff Moden wrote:Columns like "Type", "Action Taken", Cancellation Group", and "Cancellation Reason" should be INT, SMALLINTs, or TINYINTs that point to reference tables.
But I now take it he was referring to the actual model when it is being built using SQL. So I'll be sure to change that to INT.
One thing someone said to me was that there cannot be two primary keys in a table. Is this true? if so, how can I adjust my data model to reflect this?. I understand that Ticket Number and Ticket ID make up a composite key. Should it look something like this?:
I don't think you misunderstood. I think Jeff and I have different views on what goes into a logical data model.
I say stick with using common terms understood to everyone in the logical model. For example, integer not "tinyint". Tinyint is a technical term used in the physical implementation, not a common term to be used in data modeling.
Again, on the logical side, a data domain -- the range of values allowed -- is more appropriate and more useful than a technical data type.
So, rather than "tinyint", say an "integer" with a range of allowed values from 0 to 255. Typically that approach also allows you to refine the range better. For example, the business people may come back and say the valid values are from 1 to 100. On the physical side, that will be implemented as a tinyint, but now you have additional knowledge to allow you to add a CHECK constraint to limit the column to a value of 1 to 100 only.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
What is Ticket ID, and why is it a tinyint? The name implies it's a unique ID. A tinyint would only allow 256 tickets (0-255). If it's a type or categorization, that make the attribute name reflect that.
Why are you using both Ticket ID & Ticket Number as primary key for both Ticket & Response, and as the foreign key between the two?
The idea of an integer ID like Ticket ID is that it can serve as a more efficient surrogate key than a string, not that it supplements the natural key (e.g., Ticket Number) You would still want Ticket Number as a separate unique index or key.
But if both Ticket ID & Ticket Number comprise the primary key, you would be allowing for the same values to be used more than once in multiple combinations, and I don't think you want that. Having the same key on both tables means you can only have one response to a ticket. Is that true? You've been asked that more than once, but I haven't seen an answer.
Are you confusing Scott's mention of a Ticket Response ID Scott suggested for Response?
- Mr_X wrote:
One thing someone said to me was that there cannot be two primary keys in a table. Is this true? if so, how can I adjust my data model to reflect this?. I understand that Ticket Number and Ticket ID make up a composite key. Should it look something like this?:
The Ticket Id is a numeric code that represents the Ticket Number. Each is, and must be, unique on its own. For example, Ticket Number A3FNF8N3 might be represented as Ticket Id 1.
You can have multiple candidate PKs in a logical model, and both of these technically are potential PKs. Both should be specified as unique. But keep this techy properties in a separate document from the model used with business people. You'll get better input and a smoother conversation with business folks if you keep the tech out of it. And, indeed, that's exactly what you want to do in the logical model.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 15 posts - 16 through 30 (of 38 total)
You must be logged in to reply to this topic. Login to reply