Are Indexes Actually Changes to the System?
-
Not taking it as a slam on me at all, nor is my arguing with you here a slam on you - I just don't like the generalization to never use it. Plenty of scenarios where rebuild is out of the question so reorganize is the only choice (e.g. no free space, no downtime available and not Enterprise, small maintenance window, synchronous AG/mirror and large indexes, and so on). I know all about the "won't make free space" issue - that's been a restriction since day 1. Thanks
Paul Randal
CEO, SQLskills.com: Check out SQLskills online training!
Blog:www.SQLskills.com/blogs/paul Twitter: @PaulRandal
SQL MVP, Microsoft RD, Contributing Editor of TechNet Magazine
Author of DBCC CHECKDB/repair (and other Storage Engine) code of SQL Server 2005 -
And btw, reorganize doesn't cause page splits. Random inserts (or row expansions) cause page splits. Just because reorganize isn't lowering the amount of free space, that doesn't mean it's causing page splits, that means it's not helping to prevent page splits on those pages. That's a very, very different thing than it causing page splits.
Paul Randal
CEO, SQLskills.com: Check out SQLskills online training!
Blog:www.SQLskills.com/blogs/paul Twitter: @PaulRandal
SQL MVP, Microsoft RD, Contributing Editor of TechNet Magazine
Author of DBCC CHECKDB/repair (and other Storage Engine) code of SQL Server 2005 - Paul Randal - Wednesday, October 10, 2018 5:40 PM
Of course REORGANIZE itself doesn't cause page splits. The effects of using REORGANIZE after the REORGANIZE cause unnecessary page splits. That's actually depicted in the charts above.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, October 10, 2018 5:52 PM
But above you say "REORGANIZE (NEVER USE REORGANIZE!!!! IT DOESN'T WORK THE WAY YOU THINK IT DOES AND IS A LEADING CAUSE OF PAGE SPLITS!!!".
Reorganize won't increase a page's fullness more than a rebuild does - it just won't decrease a page's fullness if it's over the fill factor. That's not causing unnecessary page splits - that's it not preventing them because you chose to use the less expensive algorithm for whatever reason. So you could say that if you have a bunch of over-fill factor pages, consider not using reorganize and do a rebuild instead, with all the other potential pros/cons considered, if you're expecting more random inserts. Still, that's not 'never use reorganize' - that's one case, without taking into account all the other pros/cons, insert/update/delete/select patterns, environmental factors like sync AG/mirror, and so on. I read through what you've posted, and I completely agree, and always have, that if pages are filling up because of random inserts a lot across the whole index, reorganize isn't going to cut it. But that's still not a generalizable 'never use reorganize'. There's so much more to consider.
That's the problem with general advice, like the various fragmentation thresholds for what to do. They're generalizations and there are always exceptions. But swinging the other way to say the original generalization is wrong is also wrong. Pointing out the cases where the generalization isn't the best course of action is much more productive and useful for the community. That's why I teach people to think past the generalizations and do the analysis to see what the best course of index maintenance is for their environment (which you'll remember me doing when I presented on this stuff to your UG in April).
In your case, with your table and indexes, insert pattern and so on, it seems that rebuilding is always best - for whatever performance metric you're monitoring (I didn't see/remember that part of your analysis). I'm assuming you don't have a sync AG/mirror where that 146GB of log would have to be sent across the wire and replayed, and you're cool with a 146GB log backup every time you do that rebuild. What's more important in the environment? Are a few page splits causing you more problems than out-of-order pages? What's the performance metric that fragmentation, page splits, index maintenance overhead is measured against? See - pros and cons.
There are generalizations but no absolutes. Never use something is an absolute that's not defendable in all scenarios.
Thanks
Paul Randal
CEO, SQLskills.com: Check out SQLskills online training!
Blog:www.SQLskills.com/blogs/paul Twitter: @PaulRandal
SQL MVP, Microsoft RD, Contributing Editor of TechNet Magazine
Author of DBCC CHECKDB/repair (and other Storage Engine) code of SQL Server 2005 -
The forum software keeps messing me up. I'll have to type this up all at once and paste it. I'm working on the response. Sorry for the delay.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Paul Randal - Wednesday, October 10, 2018 6:20 PM
Yes... it is the cause of page splits indirectly. I'm almost done typing up my full response. You'll see what I mean. It doesn't cause page splits itself. It's the cause of page splits after it runs. Therefor, it "causes" page splits.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
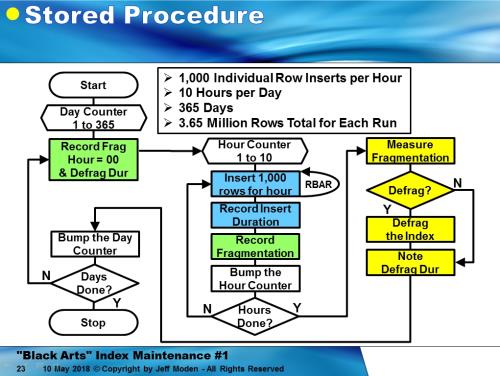
First, here’s a flowchart of the code that ran each test in each of the following charts. What’s NOT shown on this flowchart is that it always gets the same random GUIDs from the same table in the same random order (the original order they were generated in using NEWID()) with one exception. For the Baseline test (explained later), it gets the same GUIDs but they’re in sorted order.

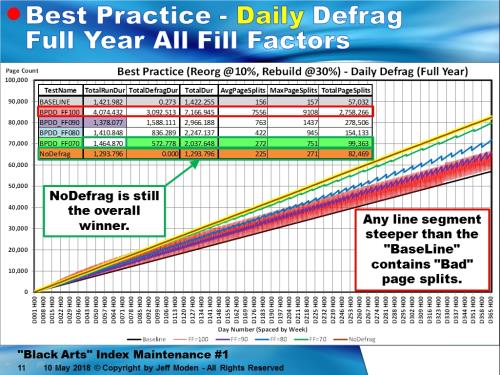
This is a chart of the results of the tests for the GUIDinserts. The spreadsheet-looking list has the name of the test and the results gleaned from the measurement tablesthat contain hourly measurements. TheTestNames that are in the format of “BPDD” stand for “Best Practice DailyDefrag”. That’s not to say that a defrag occurred each day. The code was executed at the end of each simulated test day and if the logical fragmentation was between 10 and 30%, the code did a Reorganize. If the logical fragmentation was above 30%, it did a Rebuild instead. Each test name is color coded to match the plotted result lines. The FFnnn notation identifies the FILL factor that was used for each test.
All of the tests used exactly the same random GUIDs in exactly the same random order except for the “Baseline” test (the Black line). The “Baseline” still used the exact same GUIDs as the other tests but in sorted “ever-increasing” order to simulate an “AppendOnly” index.
Each plotted line is simply the result of the hourly measurements of page counts as time wears on for each index. Any line steeper than the BaseLine contains “Nasty”page splits (and also includes the “Good” ones) because the Baseline contains only “Good” page splits.
The Brown line with the Yellow halo also used the exact same random GUIDs in the exact same random order as the other tests (other thanthe Baseline) but no defragging was done, hence the TestName of “NoDefrag”.
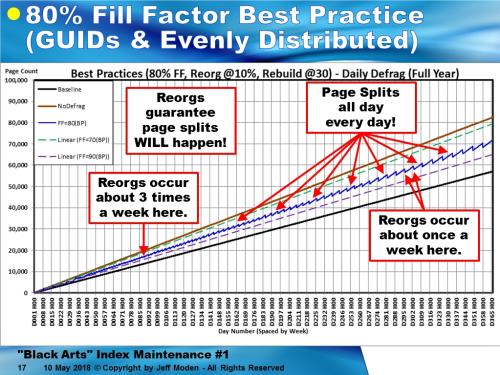
If we isolate the 80% Fill Factor test plot, we can see some unfavorable attributes associated with Reorganize. I know all of these points are Reorganize because I also capture whether a Reorganize or a Rebuild was done (or nothing at all) at the end of every simulated day. The reason why Reorganize always occurs is because, once the index gets large enough, inserting 10,000 random GUIDs just isn’t enough to fragment the table more than 30% in a single day. Note that the rows are 123 bytes wide (including the row header) fort hese tests.
Also note that the decreases in row count on the plots are due to the reduction of pages by the Reorganizes. We’ll also prove my seemingly wild claim that the reorgs guarantee that page splits will happen over the next few charts.
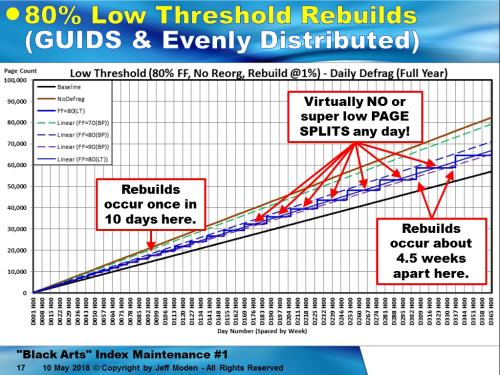
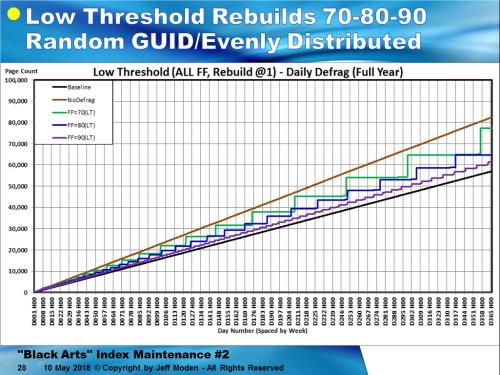
Now, lets do REBUILDs instead. Once again, I used exactly the same random GUIDs in exactly the same random order for this test but there's a remarkable thing that happens. Notice the"flats" (horizontal steps)? Those flats are where no page splits, "Nasty" or"Good" happened until just before the vertical lines, which is whereRebuild allocated new pages.
How is such a miracle possible?
1. I didn't useReorganize at all. I only did Rebuilds.
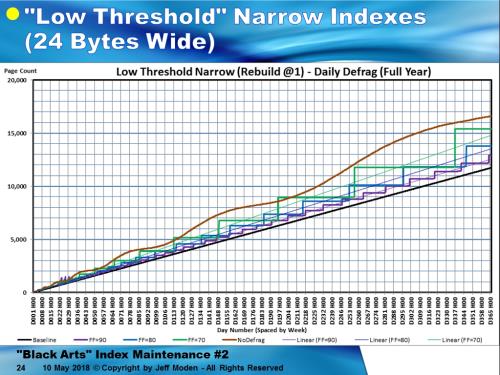
2. I didn't waitfor even 10% logical fragmentation to occur. As soon as logical fragmentation went over 1%, I did a Rebuild. This is also why I call them "LowThreshold Rebuilds".And it's all very repeatable for all Fill Factors andmore narrow NCIs except for very high Fill Factors. Here's the plot for 70, 90, and 90% FillFactor . As a bit of a side bar, the “LowThreshold Rebuilds” actually improve memory usage across multiple indexes because the "Low Threshold Rebuild"averages are always less that the "Best Practice" averages and, except for right after the Rebuild, never actually come close to using the amount of memory (number of pages) that the "Best Practice" methodsdo.
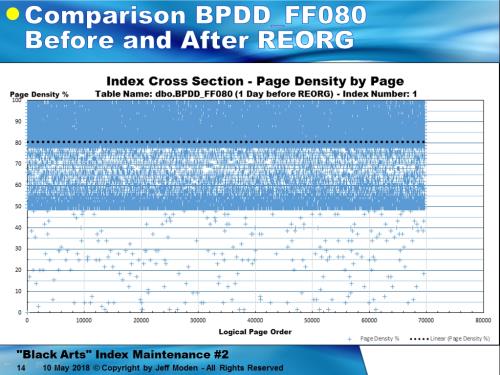
As for the extraordinary claim that Reorganize is responsible for all the extra ("Nasty") splits we've seen, if the previous charts aren’t enough to convince you, then let’s look at the page fullness profile near the end of the BPDD FF080 test. The following profile was measured using DBCC PAGE for every page (within the sp_IndexDNA proc I've attached) in the 123 byte index at 80% about one week after the most recent Reorganize. Looks pretty nasty. Each Blue “+” is the page fullness of one page (in this case... the sample rate varies by 1, 10, 100, 1000 depending on the size of the index so that I never have to plot more than 100,000 pages). Obviously, the darker the color,the more pages are in a given area.
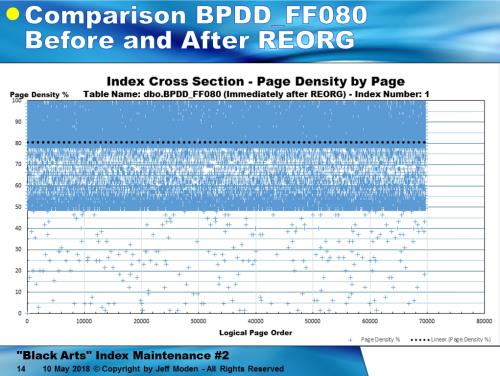
Here’s the same index immediately after the Reorganize. Although there was somemovement of data as witnessed in my test table, you certainly can’t tell even if you overlay this chart with the one above and switch back and forth betweent he two to see what moved. The bottom line is, reorg did almost nothing but combine some of the pages (the downward movement of the plot lines in the previous row count charts) and reduce the number of pages just when it was critical to actually make more pages rather than to condense them. Ipso Facto, Reorganize “caused”more page splits to happen and, like a bad drug habit, the more you use it, the more you need to use it.
Worse yet and contrary to the claim that Reorganize uses less resources, Reorganize is deadly to the log files thanks to the extra page splits that are caused after using it. If you look at the slope of the increase on the “NoDefag” line on the previous line charts (not the DNA charts), the slope is quite a bit less than the slope of the increases each week after the Reorganizes. That’s because the Reorganizes remove critical free space which causes morepage splits per day/week than the “NoDefrag” line, which makes its own critical free space and then uses it to the maximum extent (no pun intended) possible.
Further proof is in the pudding in the “Low ThresholdRebuild” line charts because they clearly show weeks-long periods of zero pagesplits (and, therefore, zero logical fragmentation) because the rebuilds add critical space above the Fill Factor, which Reorganize does not.
You say that my 146GB table would cause a world of hurt if I did a Rebuild on it because of all the log file activity due to the copy of the index being made and the old index not being dropped until it wascommitted. Assuming that I left things in the Full Recovery model because of the requirements for “a sync AG/mirror”,I agree... there would indeed be a problem.
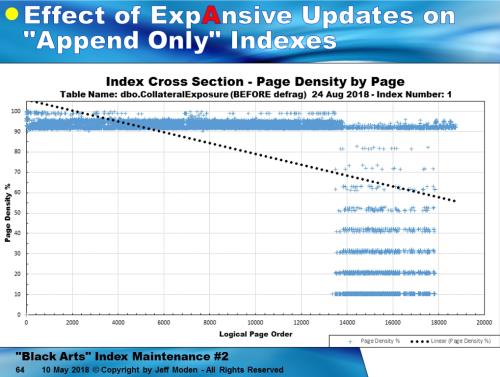
But let’s see what Reorganize does in the same scenario. This is the sp_IndexDNA plot of that real 146GB Clustered Index before the Reorganize. It’s setup to be an “Append Only” index but “ExpAnsive” updates absolute trash that idea. There’s an average of only 9 rows per page and that’s where the 9 fragmentation stripes come in. And, yeah… this is that “skewed” page split stuff and the effect those page splits have on log files that you talk about in one of your great articles. In fact, this is visual proof of what you say can and does happen.
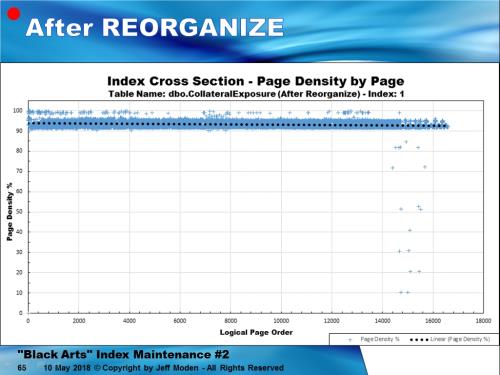
And here’s the same index after the Reorganize.
Looks like Reorganize worked a treat. When I started, the Logical Fragmentation was only 12% and that’s well within the boundary of the 10 to 30% "Best Practice" rule for Reorganize. But, when we check on the run stats, Reorganize turns out to be much worse than a Rebuild.
Time to complete: 1 hour 20 minutes and 45 seconds.
Log File Exploded: Grew from 37GB to 227GB during a quiet time when the Log file was mostly empty. That’s a lot more than a Rebuild.The rebuild only took 45 minutes in the Full Recovery Model. As a bit of a side bar, I do use the CREATE WITH DROP EXISTING trick to move the CI to another file group and then drop the old file group so that I don’t end up with 146GB (+ about 20%) offree space that I won’t be using for a while in my MDF/NDF files. You certainly don't need to do such a thing if you have the space on the disk you Primary FG lives on and you don't mind having that amount of extra space in the MDF file. A 1 TB index would be a bit different and you'd need to do the trick I cited.
Getting back to the reorganize, I’m thinking that Reorganize lost bigtime there and that my recommendation to never use Reorganize isn’t such a bad one. 😀 If you don't have the MDF/NDF space to do the Rebuild like I did, then I still wouldn't Reorganize the index. It just costs way too much to do so, even on much smaller indexes.
Shifting gears a bit, the database this table lives in has gone over 1TB. We anticipated that and so we don’t use the likes of AG/Mirror. Instead, the passive node of our clustered is kept up to date (almost instantly even for such a large transaction) by our SANs. We also have a passive off-site node about 80 miles away that’s kept up to date the same way. It takes a little longer because of the trip across the dedicated VPN (slower thanSAN to SAN comms) but it keeps up with our rebuilds because those comms are not destroyed by making a trip to the BULK LOGGED Recovery Model like AG/Mirror might (is). Because the index Rebuild is minimally logged when we do this for real, it only takes about 25minutes to do the rebuild and the log file never grows past 37GB.
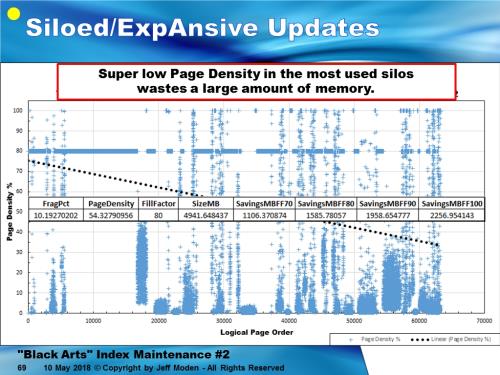
Shifting gears again, check this out. More proof of what you say about skewed pagesplits and what you say in Books Online about Logical Fragmentation NOT being the only reason to do index maintenance. Imagine just how low the memory usage is within some of the “silos” that are formed. This particular index was the first one I ever ran sp_IndexDNA on except I didn’t originally call it that. I changed it to that name because this chart almost looks like a DNA “smear” chart.
I’ve never done a Reorganize on that one but you can see how badly it’s physically fragmented (54% page density) at only 10% logical fragmentation. I’ll do a rebuild on it and then wait for it to get back to 10% fragmentation a snap another sp_IndexDNA picture of it for everyone after I do a Reorganize.
Have I missed any of the questions you’ve asked?
And shifting gears one final time, thank you for what you, Kimberly, and the rest of your team does. I especially thank the two of you for all the work you’ve done over themany years that have been included in your blog and for“documenting” great but undocumented tools like DBCC IND and DBCC Page as well as what your team did for our PASS Chapter group. There needs to be more people like you.
p.s. This work also proves that NOT defragging isn’t the way to go for everything, especially when page densities get down below 70% on 5GB indexes like the one immediately above. It does show, however, that the people touting the fully “No Defrag” methods (I'm only partially there now because there are places where it has merit) are right about one thing for sure…index maintenance can be a pretty bad waste of time if you don’t design your indexes correctly or can’t avoid “ExpAnsive” updates. If such things can’t be avoided, I just do a Rebuild when the page density gets below my threshold of pain. I use a“numbering trick” with the Fill Factor to identify such indexes so that I don’t actually have to keep track of them and other more well behaved indexes in a separate table. For “auto-classification”of indexes, I may end up having to do that, though. Still working on that.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Ah crud. Somehow, I left out a couple of sections above and forgot to attach the index DNA proc and spreadsheet (now attached).
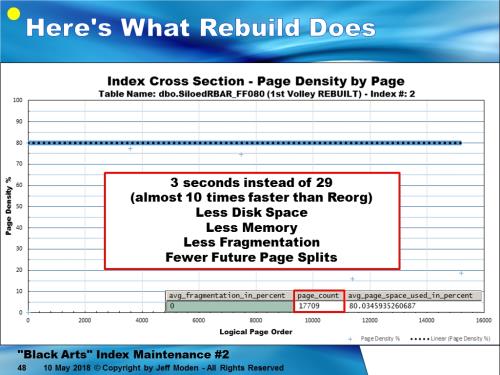
First, here's what "Low Threshold Rebuilds" do to the GUID test at an 80% Fill Factor. It's a whole lot better than what Reorganize does and actually takes less disk space because if doesn't leave a lot of junk below the Fill Factor like Reorganize does.
Also, here's a really clear example of how ineffective Reorganize is... it's an "out of order" single silo and it's pretty bad within the silo...
Here's what it looks like right after a Reorganize... a lot of stuff moved up to the Fill Factor. That also means they're going to split again sooner because Reorganize didn't make any extra room above the Fill Factor..
And here's what happens if you do a Rebuild, instead. And, it did it in a final page count less than what Reorganize did even though there's now extra space above the Fill Factor and pages below the Fill Factor have all been "combined" to hit the Fill Factor. I didn't check on this one but, considering what we saw on the 146MB index in the previous post, I'd have to say it used less log file, as well.The sp_IndexDNA proc is fairly well documented. The IndexDNA spreadsheet isn't very sophisticated. You need to copy the return from the sp_IndexDNA proc (Grid mode) to the areas identified in the chart. If you have the columns names enabled as part of the return, then paste in the appropriate Blue cell. If not, paste in the cell below the appropriate Blue cell. I am working on this to make it a "refreshable spreadsheet" instead of having to run sp_IndexDNA separately.
Note that the proc does sometimes have a problem with producing a return because DBCC IND depends on other things. Small indexes should just take a minute or two but can get stuck when it tries to enumerate the proper logical page order using a recursive CTE when DBCC IND leaves out a page. If you do a statistics update with a full scan on the index, that will fix this problem.
Thanks for giving me the opportunity to explain all of this.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks for posting all this detail. It certainly looks like for this index, reorganize doesn't give you any gain, but I'm not seeing the proof of your generalization to never use it, and to rebuild at 1% fragmentation instead. I guess we'll agree to disagree.
Paul Randal
CEO, SQLskills.com: Check out SQLskills online training!
Blog:www.SQLskills.com/blogs/paul Twitter: @PaulRandal
SQL MVP, Microsoft RD, Contributing Editor of TechNet Magazine
Author of DBCC CHECKDB/repair (and other Storage Engine) code of SQL Server 2005 -
Thanks for the feedback, Paul. I've admittedly got an environment that's quite a bit different than a synchronous AG/mirror environment and simply don't have access to such an environment. Do you have a measured test that demonstrates how Reorganize beats Rebuild on a large index for such an environment? I already know there's the disadvantage of Rebuild causing unwanted growth of an MDF file when done in place so you don't need to include that. I'm more concerned about the duration and the effect on the log file that you were kind enough to point out.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
We did a bunch of testing back in 1999 when the code was originally written, but I haven't done any large-scale empirical testing since then. Duration is a red herring - it might take twice as long but not do any data movement - that doesn't mean it's bad - it just means it took twice as long to work through the pages and decide what to do.
Paul Randal
CEO, SQLskills.com: Check out SQLskills online training!
Blog:www.SQLskills.com/blogs/paul Twitter: @PaulRandal
SQL MVP, Microsoft RD, Contributing Editor of TechNet Magazine
Author of DBCC CHECKDB/repair (and other Storage Engine) code of SQL Server 2005 - Paul Randal - Thursday, October 11, 2018 10:00 PM
K. Thanks.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)



Viewing 12 posts - 61 through 72 (of 72 total)
You must be logged in to reply to this topic. Login to reply