Aggregate Select Results and convert Secs to Hours Mins.
- Jeff Moden wrote:
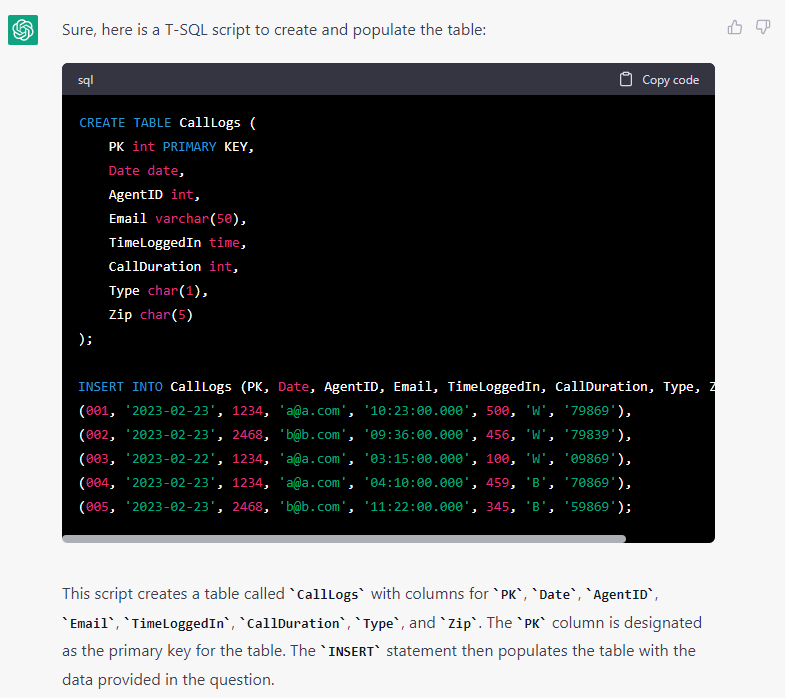
The OP explicitly included leading zeroes in the PK. Those are gone in the table because ChatGPT failed to recognize that as a string. It would have similar issues with zip codes and the like.
The column name "PK" is a strong indication that the column will be unique and also needs to be a constraint. In a lot of cases, that will also be the key for the Clustered Index and, in a phone system it would actually be a character based "Call ID". As Scott Pletcher would suggest, that's probably not the best use of the Clustered Index for this table but that's the way it's frequently designed in Phone Systems.
I edited the question and added a ZIP to the data and ask it to create it with a pk:

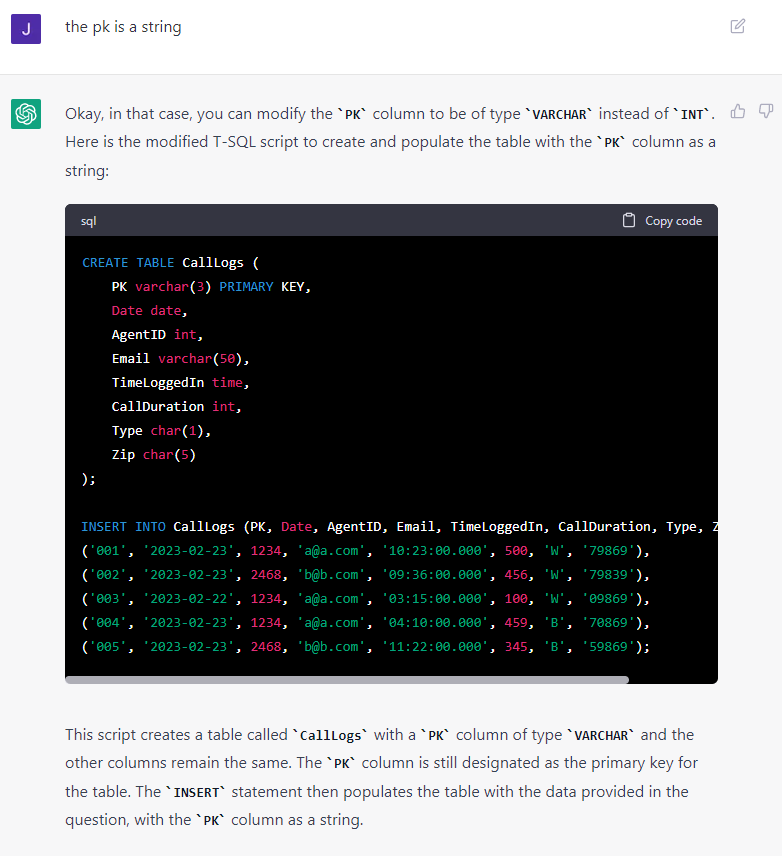
The zip was created as a char(5) but it still made the pk an int, so I told it the pk is a string:
CREATE TABLE CallLogs (
PK varchar(3) PRIMARY KEY,
Date date,
AgentID int,
Email varchar(50),
TimeLoggedIn time,
CallDuration int,
Type char(1),
Zip char(5)
);
INSERT INTO CallLogs (PK, Date, AgentID, Email, TimeLoggedIn, CallDuration, Type, Zip) VALUES
('001', '2023-02-23', 1234, 'a@a.com', '10:23:00.000', 500, 'W', '79869'),
('002', '2023-02-23', 2468, 'b@b.com', '09:36:00.000', 456, 'W', '79839'),
('003', '2023-02-22', 1234, 'a@a.com', '03:15:00.000', 100, 'W', '09869'),
('004', '2023-02-23', 1234, 'a@a.com', '04:10:00.000', 459, 'B', '70869'),
('005', '2023-02-23', 2468, 'b@b.com', '11:22:00.000', 345, 'B', '59869'); -
Thanks for taking the time to do these experiments, Jonathan.
The reason it got the Zip right is because it's in quotes. You also had to realize its mistakes on the PK and then tell it of those mistakes. When it produced the new output, you had to code-review everything again to make sure that it didn't introduce additional errors.
It would have been faster to make the changes yourself, would it not?
And, yes... I totally agree. Most human would include a Zip in a Values Table Constructor in single quotes but not everything that I receive is in such good shape. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
And, in the process of making the primary key, it made yet another mistake (at least according to my personal standards). If it's a #TempTable, then never name the PK Constraint. Let the system do it because constraints must be uniquely named in the database.
For permanent tables, it MUST be a named constraint and it must be named in the pattern of PK_tablename.
I also just noticed that it used the 1 part naming convention in the CREATE statement.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Thanks for taking the time to do these experiments, Jonathan.
The reason it got the Zip right is because it's in quotes. You also had to realize its mistakes on the PK and then tell it of those mistakes. When it produced the new output, you had to code-review everything again to make sure that it didn't introduce additional errors.
It would have been faster to make the changes yourself, would it not?
And, yes... I totally agree. Most human would include a Zip in a Values Table Constructor in single quotes but not everything that I receive is in such good shape. 😀
Zip wasn't in quotes in the input I provided. It put the quotes around the values in the insert statement by itself.
- Jonathan AC Roberts wrote:Jeff Moden wrote:
Thanks for taking the time to do these experiments, Jonathan.
The reason it got the Zip right is because it's in quotes. You also had to realize its mistakes on the PK and then tell it of those mistakes. When it produced the new output, you had to code-review everything again to make sure that it didn't introduce additional errors.
It would have been faster to make the changes yourself, would it not?
And, yes... I totally agree. Most human would include a Zip in a Values Table Constructor in single quotes but not everything that I receive is in such good shape. 😀
Zip wasn't in quotes in the input I provided. It put the quotes around the values in the insert statement by itself.
I DID miss that. Thanks for the correction and, yes... I'm a bit more impressed now.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
And, in the process of making the primary key, it made yet another mistake (at least according to my personal standards). If it's a #TempTable, then never name the PK Constraint. Let the system do it because constraints must be uniquely named in the database.
For permanent tables, it MUST be a named constraint and it must be named in the pattern of PK_tablename.
I also just noticed that it used the 1 part naming convention in the CREATE statement.
Next time I'll ask it to create the table to the Jeff Moden standards - lol
-
Heh... I did that with the count 1 to a million thing. IIRC, I posted that little gem that said the rCTE that it created (which I also told it to avoid) was how Jeff Moden would do it and almost nothing could have been further from the truth. I also asked it how Itzik Ben-Gan would have done it and it avoided the rCTE but based it on too small a table and, IIRC, used ROW_NUMBER() OVER in the WHERE clause.
I'll take a human programmer any-day, even if I have to train them.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
BTW and just to clarify, I'm damned impressed with what they've been able to get ChatGPT to do. The technology behind all of that is mind boggling . My biggest peeve (and I realize that I'm repeating myself, but it's important, IMHO) is that the user agreement warns that it's just a machine that just does "AI" and the creators cannot guarantee that it's actually going to come up with the correct answer on anything.
And, yet, they programmed it so that it returns information in such a cock sure manner that folks in need of an answer (and most of the rest of the planet) are inherently wanting to believe it to begin with. It even stated that an incorrect answer is how Jeff Moden and Itzik Ben-Gan would do it along with stating that the code is "efficient". That's a deadly combination of misinformation to the point where I'll call it "slanderous lying" that could put users of ChatGPT in a whole 'nuther world o' hurt..
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@Wecks ...
Getting back to the subject and with the understanding that I try to anticipate the proverbial "next question" from my users, here's what I'd do along with some documentation as to why I'm doing it in such a fashion.
--=====================================================================================================================
-- Create the "report". Remember that formatting things like time should be done in the presentation layer.
-- Of course, sometimes the output of the query is necessarily the "presentation layer".
-- In such cases, I try to keep the two layers separate. This frequently allows for better performance (doubtful,
-- in this case) but it also allows for easier "maintenance" in the future as well as allowing separate testing
-- of "logic" and "presentation" woes.
-- Plan on it... for phone system reporting, many shoes will drop in the future. ;-)
--=====================================================================================================================
WITH ctePreAgg AS
(--==== Data Layer (and applies the "DRY" principle)
SELECT AgentID
,[Date]
,[Type]
,TotalDur = SUM(CallDuration) --This is where we'd add clasic "Whole Minute per Call" rounding (up)
--,RptGrp = GROUPING_ID(AgentID,Date,Type) --Support future need for multiple subtotals
FROM #CDR --This is what I named the temp table to hold your test data. Change it as needed.
GROUP BY AgentID,Date,Type --WITH CUBE -- Support future need for multiple subtotals
)--==== Presentation Layer
-- The "crazy" calculation for the duration is to accomodate durations > 23:59 (HH:MM).
-- It's not so important for By Agent, By Day, but it'll become important on possible next
-- requests like By Agent for a given time frame and group totals.
-- There are other possibilites, as well but don't even thing about using the FORMAT function.
-- It'll make everthing 22 times slower.
-- The trick with RIGHT and SPACE is because everyone will evenually ask if you can "Line up the colons".
SELECT AgentID,[Date],[Type]
,[TotalDuration (*H:MI)] = RIGHT(CONCAT(SPACE(13),TotalDur/3600,':',RIGHT(TotalDur%3600/60+100,2)),13)
--,RptGrp -- Support future need for multiple subtotals.
FROM ctePreAgg
--WHERE put the date range criteria here and uncomment it.
ORDER BY AgentID, Date, Type
--ORDER BY RptGrp&4,AgentID,RptGrp&2,Date,RptGrp&1,Type -- Support future need for multiple subtotals
;In the future, it would be helpful to us and you if you'd post your example data in a "Readily Consumable format". Jonathan did such a thing in his first post. See the first link in my signature line below for a slightly different method and an explanation of why we like to get data in such a format and why you should, too.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks for your feedback guys, i am glad i stimulated some conversation.
The actual data i am querying is abundant and the data I gave a a very simple example of was simply a way to ask a question is such a way as to gauge an approach maybe to visualise a solution, having posted only a handful of times i didn't think anyone would take the time to take the data and create a working model, in future should i have another development question i will endeavour to supply what i can in a consumable format.
I will review the posts from yesterday and see if i can apply some of the suggestions.
- Jeff Moden wrote:
BTW and just to clarify, I'm damned impressed with what they've been able to get ChatGPT to do. The technology behind all of that is mind boggling . My biggest peeve (and I realize that I'm repeating myself, but it's important, IMHO) is that the user agreement warns that it's just a machine that just does "AI" and the creators cannot guarantee that it's actually going to come up with the correct answer on anything.
And, yet, they programmed it so that it returns information in such a cock sure manner that folks in need of an answer (and most of the rest of the planet) are inherently wanting to believe it to begin with. It even stated that an incorrect answer is how Jeff Moden and Itzik Ben-Gan would do it along with stating that the code is "efficient". That's a deadly combination of misinformation to the point where I'll call it "slanderous lying" that could put users of ChatGPT in a whole 'nuther world o' hurt..
Ha who or what comes with a guarantee? Arrogant new programmers being wrong and strong is nothing new. Still the questions being asked are sort of simple. What happens if you give ChatGPT a past SSC question (a good one with sample data and expected results) for which there's an accepted answer? For my part I'm really curious to try it out. Imo the very last thing the AI's will surpass humans in is data modelling and relational logic. Could a language model really come up with a complicated (and correct) FROM clause? In time it's certain, no? In chess it's game over the software has won. No person can beat Mittens. My first programming challenge for ChatGPT is unit testing and creating mocks in C#. If it works I'll be beyond happy 🙂
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können

Viewing 11 posts - 16 through 26 (of 26 total)
You must be logged in to reply to this topic. Login to reply