A Version Control Strategy for Branch-based Database Development
-
Comments posted to this topic are about the item A Version Control Strategy for Branch-based Database Development
Cheers, Tonie
See you at Sea(QL) this year?
https://seaql.nl -
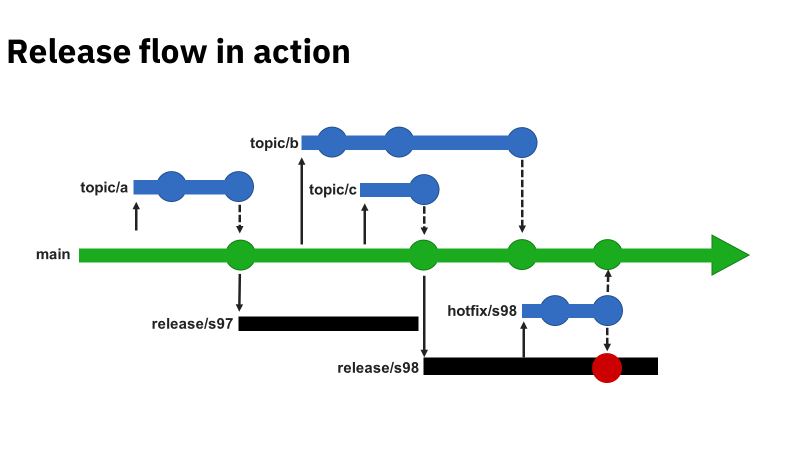
I have admittedly not studied the entire article (yet). One of the things that caught my eye was your "movie" about the "Release Flow in Action". Watching that, it would appear that "Topic C" wasn't considered during the overarching "Topic B" and it looks like when "Topic B" was released to the Main, it could have repressively overwritten what was done by "Topic C". One has to wonder if that was the reason for "Hot Fix".
Again, I'm probably missing something because I've not studied the article but a quick search in the article mentions topic/a but nothing about topic/b or topic/c.
If that's actually covered in the article, no need for an explanation here. If it's not, then how was topic/c actually handled in regards to topic/b being released later?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Despite that you haven't studied the article yet, this is an interesting question Jeff.
And no, this was not covered in the article in-depth, because it involves the basics of git in combination with any branching strategy (in this case release flow). Which makes the question not only interesting but also a fair question!

Although topic B and C have the same starting point (commit), topic B is not yet merged back in main at the point of creating release/s98. No overwriting is happening there and the hotfix in this example is about something else.
However with topic B merging back into main an overwrite (merge conflict) could arise. But only if the topics (B/C) touch the same files, in all other cases git takes care of the merge without any user interference.
The same applies on merging/cherry-picking the hotfix back to main, after Topic B merged back into it.
A little summary what is in the article about merging:
These merge conflicts are solved in the pull request, before the merge is done. And because of the configured PR workflow, a pre-merging build (with the code from topic B and main) must be build and tested as prerequisite before the completion of the PR.
This all to comply to the rule of "the main branch is always in a releasable state."
Cheers, Tonie
See you at Sea(QL) this year?
https://seaql.nl -
A very nice and well-written article. The one thing that is, to me, the difference in creating a DTQP promotion process for software and one for databases, is the fact that an existing database contains information. So either you must never have a destructive change, or you must always do this in very small incremental steps. I wondered how you dealt with this situation - or do you just leave it to tools like the Redgate comparison tool? Because the latter makes this process very database-vendor dependent.
-
In a DTQP setup it is key to work as closely with production-(alike)-data as possible. This can be achieved with clones (or containers), there are several vendor but also community solutions for that.
When you work with a lot of data, the quality of the change you develop / test will evolve, destructive changes will be visible very early and this will also force you to work in (feasible) incremental steps (migrations).
But making perfect migrations is a whole other topic 😉 And yes for this a Redgate tool is used, Flyway Desktop Enterprise (which is using in the background Redgate SQL (data) Compare).
Cheers, Tonie
See you at Sea(QL) this year?
https://seaql.nl
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply