A varchar(MAX) STRING_SPLIT function for SQL 2012 and above
-
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION [ibb].[StringToTableStrings]
(
@cadena NVARCHAR(MAX),
@separador NVARCHAR(MAX) = ',',
@eliminarNulos BIT = 1,
@trim BIT = 1
) RETURNS @tabla TABLE
(
id INT IDENTITY (1, 1) NOT NULL PRIMARY KEY CLUSTERED WITH (FILLFACTOR = 80, PAD_INDEX = ON, IGNORE_DUP_KEY = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON "default",
cadena1 NVARCHAR(MAX) NULL
)
--WITH SCHEMABINDING
AS BEGIN
WITH lista(val) AS (
SELECT @cadena val
UNION ALL
SELECT SUBSTRING(val, CHARINDEX(@separador, val ) + LEN(@separador), LEN(val)) AS val
FROM lista
WHERE CHARINDEX(@separador, val) > 0
), pares AS (
SELECT par
FROM
(SELECT SUBSTRING(val, 1, IIF(CHARINDEX(@separador, val) = 0, LEN(val), CHARINDEX(@separador, val) - 1)) AS par
FROM lista) AS valores
WHERE ISNULL(@eliminarNulos, 0) != 1 OR (par IS NOT NULL AND RTRIM(LTRIM(par)) <> '')
)
INSERT @tabla
SELECT IIF(ISNULL(@trim, 0) != 1, par, LTRIM(RTRIM(par))) AS cadena1
FROM pares
OPTION (OPTIMIZE FOR UNKNOWN, MAXRECURSION 0)
RETURN
END
GO -
You should actually have 2 different versions of this, one for
nvarcharand another forvarchar. Avarcharover the length of 1billion~ characters would be truncated when it is implicitly cast to annvarcharin the parameter. Also, having something that has avarcharpassed to it that returns annvarcharcould be very bad for SARGability, if the column being compared afterwards is avarchartoo (as the Column would be implicitly converted, meaning any indexes are effectively useless).Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
I am intelligent and I have no varchar of 1 billion characters.
Also, in my designs, there is usually no place for varchar. In that case, I would use text strings where the fields are of fixed length, and not variable.
Excuse my bad english. The culprit is google translate.
-
Sorry, I was wrong in my explanation. I don't use varchar because in my work there are data in several languages, and I use nvarchar, not varchar.
- fgrodriguez wrote:
I am intelligent and I have no varchar of 1 billion characters.
Also, in my designs, there is usually no place for varchar. In that case, I would use text strings where the fields are of fixed length, and not variable.
So you mean you use a
charinstead of avarchar(orncharinstead ofnvarcahr)? I honestly find it hard to believe that none of your columns, in your entire database, have a variable length strings being stored. That could be something as simple as a Username, or Person's name.Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
I apologize again. He was indeed in the clouds and did not think what he wrote.
I don't usually use char or nchar except in some very specific cases.
- Thom A wrote:fgrodriguez wrote:
I am intelligent and I have no varchar of 1 billion characters.
Also, in my designs, there is usually no place for varchar. In that case, I would use text strings where the fields are of fixed length, and not variable.
So you mean you use a
charinstead of avarchar(orncharinstead ofnvarcahr)? I honestly find it hard to believe that none of your columns, in your entire database, have a variable length strings being stored. That could be something as simple as a Username, or Person's name.I'm not sure where this is all coming from. The discussion is supposed to be about the script :
https://www.sqlservercentral.com/scripts/string_split-function-for-sql-2012-and-above
- Jonathan AC Roberts wrote:
I'm not sure where this is all coming from. The discussion is supposed to be about the script :
https://www.sqlservercentral.com/scripts/string_split-function-for-sql-2012-and-above
Likely because I mentioned you should have a
varcharandnvarcharversion, Jonathan, for the reasons mentioned. Unless you disagree?Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk - Thom A wrote:Jonathan AC Roberts wrote:
I'm not sure where this is all coming from. The discussion is supposed to be about the script :
https://www.sqlservercentral.com/scripts/string_split-function-for-sql-2012-and-above
Likely because I mentioned you should have a
varcharandnvarcharversion, Jonathan, for the reasons mentioned. Unless you disagree?Ok I see, it's just that for some strange reason the first comment was just some code, in a foreign language, pasted by fgrodriguez with no explanation or even comments of what it was, (it doesn't even seem to work). I have no idea why she/he did that!
You have a valid point but I've never had a string even close to 1 billion characters, I've never heard of anyone else who has either, but maybe there are people that do store that sort of information in SQL Server and also want to split it?
If you join the results to another table on a varchar column there might be a degradation in performance, but I think you can just cast the value column from the output of the splitter to be a varchar, in which case it would be still be SARGable, but to all intents and purposes the code works with both varchar and nvarchar, it's a fast MAX string splitter. Also, the code is easy enough for almost anyone to change nvarchar to varchar. So I don't think it would have been helpful to provide two scripts when one does the job and is easy for someone to amend if needed.
-
I'm not sure who or what marked the post by fgrodriguez as spam but I'm reposting it here so that the de-spaminator doesn't delete it.
I'll also state I'm a bit concerned about the possible performance of the code because it's an mTVF rather than an iTVF. That's part of the reason why I wanted to make sure the marked post didn't disappear. It deserves to be tested.
fgrodriguez wrote:SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION [ibb].[StringToTableStrings]
(
@cadena NVARCHAR(MAX),
@separador NVARCHAR(MAX) = ',',
@eliminarNulos BIT = 1,
@trim BIT = 1
) RETURNS @tabla TABLE
(
id INT IDENTITY (1, 1) NOT NULL PRIMARY KEY CLUSTERED WITH (FILLFACTOR = 80, PAD_INDEX = ON, IGNORE_DUP_KEY = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON "default",
cadena1 NVARCHAR(MAX) NULL
)
--WITH SCHEMABINDING
AS BEGIN
WITH lista(val) AS (
SELECT @cadena val
UNION ALL
SELECT SUBSTRING(val, CHARINDEX(@separador, val ) + LEN(@separador), LEN(val)) AS val
FROM lista
WHERE CHARINDEX(@separador, val) > 0
), pares AS (
SELECT par
FROM
(SELECT SUBSTRING(val, 1, IIF(CHARINDEX(@separador, val) = 0, LEN(val), CHARINDEX(@separador, val) - 1)) AS par
FROM lista) AS valores
WHERE ISNULL(@eliminarNulos, 0) != 1 OR (par IS NOT NULL AND RTRIM(LTRIM(par)) <> '')
)
INSERT @tabla
SELECT IIF(ISNULL(@trim, 0) != 1, par, LTRIM(RTRIM(par))) AS cadena1
FROM pares
OPTION (OPTIMIZE FOR UNKNOWN, MAXRECURSION 0)
RETURN
END
GO
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
I'm not sure who or what marked the post by fgrodriguez as spam but I'm reposting it here so that the de-spaminator doesn't delete it.
I'll also state I'm a bit concerned about the possible performance of the code because it's an mTVF rather than an iTVF. That's part of the reason why I wanted to make sure the marked post didn't disappear. It deserves to be tested.
fgrodriguez wrote:SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION [ibb].[StringToTableStrings]
(
@cadena NVARCHAR(MAX),
@separador NVARCHAR(MAX) = ',',
@eliminarNulos BIT = 1,
@trim BIT = 1
) RETURNS @tabla TABLE
(
id INT IDENTITY (1, 1) NOT NULL PRIMARY KEY CLUSTERED WITH (FILLFACTOR = 80, PAD_INDEX = ON, IGNORE_DUP_KEY = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON "default",
cadena1 NVARCHAR(MAX) NULL
)
--WITH SCHEMABINDING
AS BEGIN
WITH lista(val) AS (
SELECT @cadena val
UNION ALL
SELECT SUBSTRING(val, CHARINDEX(@separador, val ) + LEN(@separador), LEN(val)) AS val
FROM lista
WHERE CHARINDEX(@separador, val) > 0
), pares AS (
SELECT par
FROM
(SELECT SUBSTRING(val, 1, IIF(CHARINDEX(@separador, val) = 0, LEN(val), CHARINDEX(@separador, val) - 1)) AS par
FROM lista) AS valores
WHERE ISNULL(@eliminarNulos, 0) != 1 OR (par IS NOT NULL AND RTRIM(LTRIM(par)) <> '')
)
INSERT @tabla
SELECT IIF(ISNULL(@trim, 0) != 1, par, LTRIM(RTRIM(par))) AS cadena1
FROM pares
OPTION (OPTIMIZE FOR UNKNOWN, MAXRECURSION 0)
RETURN
END
GOI reported it for inappropriate content, if fgrodriguez wants to submit a script there are ways of doing it other than just pasting raw code with no comments into someone else's script discussion. I did try the code it but it just made my machine hang in an infinite loop:
DECLARE @string nvarchar(MAX)
SELECT @string='Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.'
SELECT @string FullText,
Sentence.cadena1 Sentence,
PartSentence.cadena1 PartSentence,
Word.cadena1 Word
FROM dbo.[StringToTableStrings](@string, '.',default,default) Sentence
CROSS APPLY dbo.[StringToTableStrings](Sentence.cadena1, ',',default,default) PartSentence
CROSS APPLY dbo.[StringToTableStrings](PartSentence.cadena1, ' ',default,default) Word -
Effectively. The usefulness of this function is not that of rapid execution, but the utility of the result. That is why there is a key that lists the results and an index.
In addition, it allows to eliminate or not the nulls and / or to make or not a trim of the results with the third and fourth parameters respectively.
I have also tried the query, and I also have infinite loops. I think the solution is to make subquerys. But I can't try it until next Tuesday. I'm sorry.
Thank Jonathan AC Roberts
- fgrodriguez wrote:
Effectively. The usefulness of this function is not that of rapid execution, but the utility of the result. That is why there is a key that lists the results and an index.
In addition, it allows to eliminate or not the nulls and / or to make or not a trim of the results with the third and fourth parameters respectively.
I have also tried the query, and I also have infinite loops. I think the solution is to make subquerys. But I can't try it until next Tuesday. I'm sorry.
Thank Jonathan AC Roberts
Have you tried using it to split words in a sentence (based on a space delimiter)?:
SELECT cadena1
FROM dbo.[StringToTableStrings]('Lorem ipsum dolor sit amet.',' ',default,default); - Thom A wrote:
having something that has a
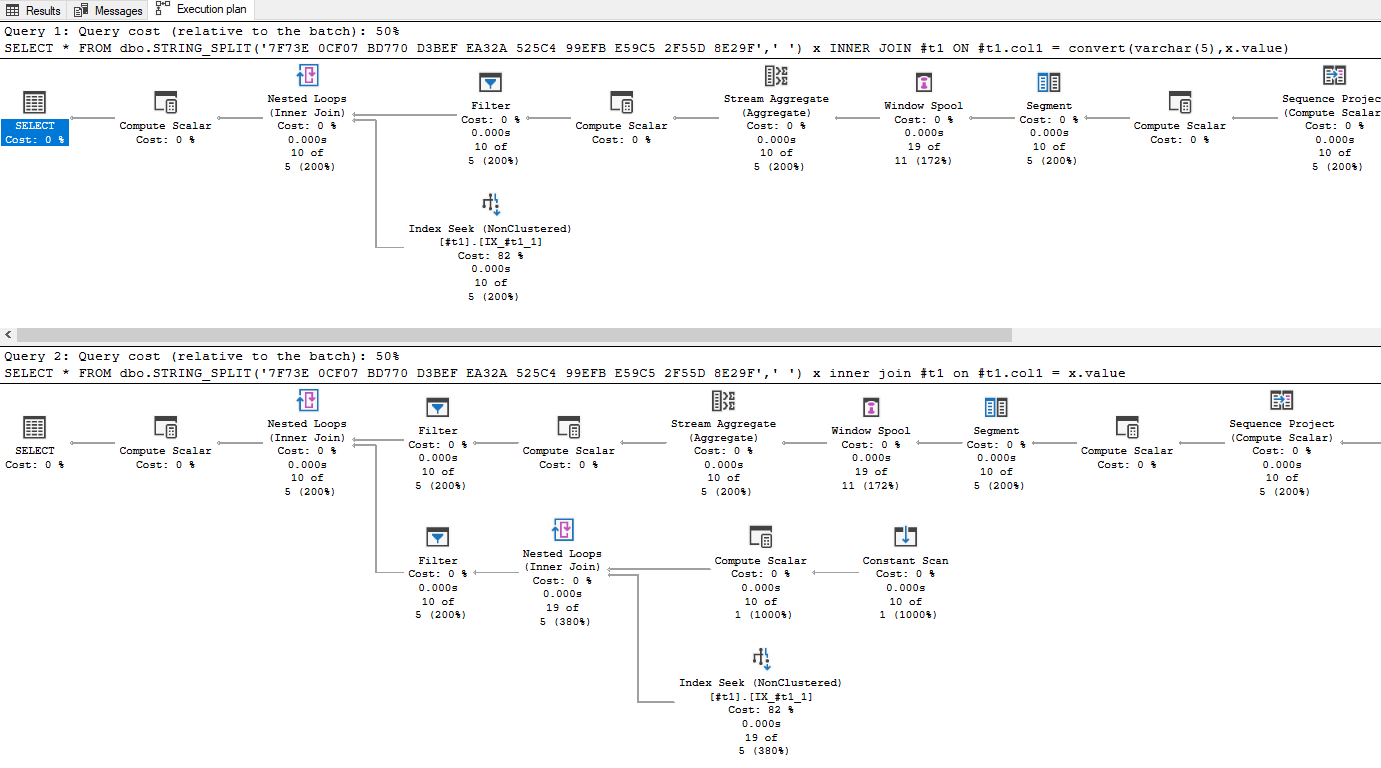
varcharpassed to it that returns annvarcharcould be very bad for SARGability, if the column being compared afterwards is avarchartoo (as the Column would be implicitly converted, meaning any indexes are effectively useless).I've just run a test and not converting the results of the dbo_STRING_SPLIT function and joining the results to a varchar still does an index seek on the table.
You will need a tally table with at least 1 million rows on to repeat:
Set the data up:
if object_id('tempdb..#t1','U') IS NOT NULL DROP TABLE #t1
select distinct convert(varchar(5),col1) col1
into #t1
from (select top(1000000)
convert(varchar(5),LEFT(newid(),5)) col1
from tally
union all
select convert(varchar(5),value)
from dbo.STRING_SPLIT( '7F73E 0CF07 BD770 D3BEF EA32A 525C4 99EFB E59C5 2F55D 8E29F',' ') x
) x
create unique index IX_#t1_1 on #t1(col1)
goRun two SQL statements, one with the compare to value, the other with compare to convert(varchar(5),value)
set statistics io, time on
SELECT *
FROM dbo.STRING_SPLIT('7F73E 0CF07 BD770 D3BEF EA32A 525C4 99EFB E59C5 2F55D 8E29F',' ') x
INNER JOIN #t1 ON #t1.col1 = convert(varchar(5),x.value)
SELECT *
FROM dbo.STRING_SPLIT('7F73E 0CF07 BD770 D3BEF EA32A 525C4 99EFB E59C5 2F55D 8E29F',' ') x
INNER JOIN #t1 ON #t1.col1 = x.value
Table '#t1_________________________________________________________________________________________________________________000000000034'. Scan count 0, logical reads 30, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 59 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 5 ms.
Table '#t1_________________________________________________________________________________________________________________000000000034'. Scan count 10, logical reads 30, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 156 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.It does a seek on both queries but the second query (without the convert varchar(5)) is a bit slower to execute
-
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION [dbo].[StringToTableStrings]
(
@cadena NVARCHAR(MAX),
@separador NVARCHAR(MAX) = N',',
@eliminarNulos BIT = 1,
@trim BIT = 1
) RETURNS TABLE WITH SCHEMABINDING
AS RETURN
WITH lista(val) AS (
SELECT @cadena val
UNION ALL
SELECT SUBSTRING(val, CHARINDEX(@separador, val) + DATALENGTH(@separador) / 2, DATALENGTH(val)/2) AS val
FROM lista
WHERE CHARINDEX(@separador, val) > 0
), pares AS (
SELECT par
FROM
(SELECT SUBSTRING(val, 1, IIF(CHARINDEX(@separador, val) = 0, DATALENGTH(val)/2, CHARINDEX(@separador, val) - 1)) AS par
FROM lista) AS valores
WHERE ISNULL(@eliminarNulos, 0) != 1 OR (par IS NOT NULL AND RTRIM(LTRIM(par)) <> N'')
)
SELECT IIF(ISNULL(@trim, 0) != 1, par, LTRIM(RTRIM(par))) AS cadena1
FROM pares
GOIndeed, I had not tried it using space as a separator. This is the new corrected version.
SELECT *
FROM dbo.[StringToTableStrings](' Lorem ipsum dolor sit amet.',' ',1,0)
OPTION(MAXRECURSION 0)I also know that recursion does not estimate well. And the function you wrote is more efficient.
https://www.sqlservercentral.com/articles/hidden-rbar-counting-with-recursive-ctes
Simply, in my developments, I needed to reuse the table returned by the operation and that's why I made an mTVF. And he also needed to eliminate empty chains and a trim of the results.
I appreciate your efforts to study the function.
Viewing 15 posts - 1 through 15 (of 40 total)
You must be logged in to reply to this topic. Login to reply