A single query to display the result of multiple date selection in month columns
-
Hi,
If I run the following query it gives me a column with the customer prefix and a column with the count of all the unique widget types sold for a particular month (in this case January 2019).
SELECT
customer.prefix,
Count(z.id) as 'Jan19'
FROM
(SELECT
ID,
customer
FROM
dbo.widgets
WHERE
timestamp> '2019-01-01 00:00:01' AND
timestamp< '2019-01-31 23:59:59'
GROUP BY id, customer) z
FULL OUTER JOIN customer
ON z.customer = customer.id
WHERE
prefix is not null
GROUP BY
customer.prefix
ORDER BY
customer.prefix
This would result in
PREFIX JAN19
AAA 210
BBB 311
CCC 96
etc, etc....
How would i modify the query to show date ranges for each month required and display in separate columns so that for example I can get the totals for Feb19 and Mar19 too resulting in something like this ?
PREFIX JAN19 Feb19 Mar19
AAA 210 128 187
BBB 311 350 340
CCC 96 98 102
Thanks in advance.
-
Maybe this article will help.
Cross Tabs and Pivots, Part 1 – Converting Rows to Columns
-
Thanks for that.
It's given me some ideas but I've still hit a bit of a brick wall as all these CASE solutions involve a SUM.
The value i'm returning with the COUNT(z.id) is the total number of unique part codes for a given month so a SUM won't help, in fact i'll get a conversion failure as it's not a number.
Any other solutions?
-
Which aggregate you use is up to you. You need count - use COUNT. You can also use SUM to count things in CASE. Other than that follow the technique in article pietlinden posted. Basically, you'd remove timestamp condition from WHERE clause and instead use it in CASE. So, instead of
Count(z.id) as 'Jan19'
you'll have
SUM(CASE WHEN timestamp >= '2019-01-01' AND timestamp < '2019-02-01' THEN 1 ELSE 0 END AS [Jan19]
SUM(CASE WHEN timestamp >= '2019-02-01' AND timestamp < '2019-03-01' THEN 1 ELSE 0 END AS [Feb19]
SUM(CASE WHEN timestamp >= '2019-03-01' AND timestamp < '2019-04-01' THEN 1 ELSE 0 END AS [Mar19]
--etc..--Vadim R.
-
In the future, would you mind following the basic netiquette that has been in effect for over 30 years on SQL forums? You’ve made an incredible number of common errors as well as violating basic netiquette. The first thing is that we don’t post DML, without posting the DDL that it depends on.
I will give you the benefit of the doubt that “Widgets” Is a standard term in your industry, so it makes sense to table name. We have no idea what the key for this table is because you didn’t post any DDL. However, we do know that looking any further that “Customer” Is never a valid table name; a table models a set of entities, so unless you have just one customer, this cannot be a valid table name. The rest of your column names are in violation of ISO 11179 naming rules and virtually any book on data modeling you want to read. For example, there is no such thing as a generic, universal, Kabbalah number thing called “id”; it has to be the identifier of something in particular. I think it’s supposed to be a customer_id, but you use both “customer” and “id” separately as the name of the same data element. We don’t give a data elements multiple names in RDBMS. TIMESTAMP is a data type in ANSI/ISO standard SQL, so can never be a column name. Prefix is also not a data element name; It has to be some kind of prefix.
Here’s my guess at what you should have posted.
CREATE TABLE Customers
(customer_id CHAR(5) NOT NULL PRIMARY KEY,
…);
CREATE TABLE Widgets
(purchase_date DATE NOT NULL DEFAULT CURRENT_TIMESTAMP,
customer_id CHAR(5) NOT NULL
REFERENCES Customers(customer_id)
ON DELETE CASCADE,
foobar_prefix CHAR(3) NOT NULL
CHECK ( foobar_prefix IN ( ‘AAA’, ‘BBB’, ‘CCC’, ..)),
..);
Please notice the use of the DATE data type, Check constraints and a references clause. The are in RDBMS stands for relationships never enforced by references and other things. In fact, after doing this for 30 years I’ve come to the conclusion that 85 to 95% of the real work in SQL is done in the DDL.
Finally, what you requested is not a query at all! It is a report that could be done with reporting tool. Cross tabs, pivots or whatever are what you want. SQL is based on a tiered architecture, and the database tier should only work with queries, get a result set together and then toss it over to a reporting tier. This is not just in SQL concept as a basis of all modern client/server computing.
Finally, SQL is designed to work with tables not computations. A useful idiom is a report period calendar. It gives a name to a range of dates. The worst way would be to use temporal math; it tells the world you do not think in sets or understand declarative programming yet. Here is a skeleton:
CREATE TABLE Report_Periods
(report_name CHAR(10) NOT NULL PRIMARY KEY,
report_start_date DATE NOT NULL,
report_end_date DATE NOT NULL,
CONSTRAINT date_ordering
CHECK (report_start_date <= report_end_date),
ordinal_period INTEGER NOT NULL UNIQUE
CHECK(ordinal_period > 0)
etc);
These report periods can overlap; a fiscal quarter will be contained in the range of its fiscal year. I like the MySQL convention of using double zeroes for months and years, That is 'yyyy-mm-00' for a month within a year and 'yyyy-00-00' for the whole year. The advantage is that it will sort with the ISO-8601 data format required by Standard SQL. Remember that when you design report name column.
If I run the following query it gives me a column with the customer prefix and a column with the count of all the unique widget types sold for a particular month (in this case January 2019).
SELECT Customers.foobar_prefix, COUNT(*) AS widget_cnt
FROM Customers AS C
LEFT OUTER JOIN
(SELECT W.customer_id, W,foobar_prefix, R.report_name
FROM Widgets AS W
INNER JOIN
Report_Periods AS R
ON W.purchase BETWEEN R.report_start_date AND R.report_end_date)
ON C.customer_id = W.customer_id
GROUP BY Customers.foobar_prefix;
Please post DDL and follow ANSI/ISO standards when asking for help.
-
These report periods can overlap; a fiscal quarter will be contained in the range of its fiscal year. I like the MySQL convention of using double zeroes for months and years, That is ‘yyyy-mm-00’ for a month within a year and ‘yyyy-00-00’ for the whole year. The advantage is that it will sort with the ISO-8601 data format required by Standard SQL.
Heh... ironically, the YYYY-MM-OO and YYYY-OO-OO formats violate the very standard that you've cited.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
If you really want to use
COUNTinstead ofSUMyou could do:COuNT(CASE WHEN DateColumn >= '20190101' AND DateColumn < '20190201' THEN 1 END) AS Jan19
As there is no
ELSEthenNULLwill be returned, and aggregate functions ignoreNULLvalues.Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
Hi all, thanks for the replies so far and apologies for not posting the DDL.
This is some crap i've inherited and just have deal with.
Here are the 2 tables i'm interested in:
CREATE TABLE [dbo].[customer](
[id] [int] NULL,
[name] [nchar](50) NULL,
[aliases] [nchar](120) NULL,
[prefix] [nchar](3) NULL,
[active] [int] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[widgets](
[id] [nvarchar](50) NOT NULL,
[customer] [int] NOT NULL,
[name] [nvarchar](120) NOT NULL,
[timestamp] [datetime] NOT NULL,
[attributes] [nvarchar](120) NULL
) ON [PRIMARY]
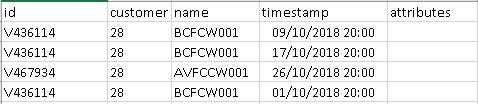
GOA sample of the widget table data for "customer 28" for the month of October might look like this:

A sample of the customer table data for "customer 28" might look like this:
Running my original query will show that for "prefix" ICU (amongst all the other prefixes) we had 4 rows of data that contained 2 unique "widgets" in October
SELECT
customer.prefix,
Count(z.id) as 'Oct 2018'
FROM
(SELECT
ID,
customer
FROM
dbo.vm
WHERE
timestamp>= '2018-10-01' AND
timestamp< '2018-11-01'
GROUP BY id, customer) z
FULL OUTER JOIN customer
ON z.customer = customer.id
WHERE prefix is not null
GROUP BY customer.prefix
ORDER BY customer.prefix;Each month will contain a different amount of unique "widgets" and I would like to for example pull a years worth of data out with a column for each month.
If I use SUM CASE as has been suggested in previous posts it counts the number of entries for the time period (4) rather than giving me the count of unique widget IDs (2).
Any further ideas on how best to approach this?
Example of what I hope the output would look like:
Thanks!
-
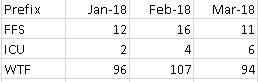
Same technique as before. For the first 3 months of 2018 it'll look like this:
SELECT
C.prefix
,[Jan-18] = COUNT(CASE WHEN CONVERT(CHAR(6), W.[timestamp], 112) = '201801' THEN 1 END)
,[Feb-18] = COUNT(CASE WHEN CONVERT(CHAR(6), W.[timestamp], 112) = '201802' THEN 1 END)
,[Mar-18] = COUNT(CASE WHEN CONVERT(CHAR(6), W.[timestamp], 112) = '201803' THEN 1 END)
FROM #customer AS C
INNER JOIN #widgets AS W
ON C.id = W.customer
GROUP BY C.prefix
ORDER BY C.prefixOf course if you need it for variable number of months/years you'll have to construct that statement dynamically:
DECLARE @FromMonth DATE = '20180101';
DECLARE @ThruMonth DATE = '20181201';
DECLARE @CurrMonth DATE = @FromMonth;
DECLARE @SQL VARCHAR(8000) = 'SELECT C.prefix'
WHILE @CurrMonth <= @ThruMonth
BEGIN
SET @SQL = @SQL + ', ['
+ LEFT(DATENAME(mm, @CurrMonth), 3)
+ '-' + DATENAME(yy, @CurrMonth)
+ '] = COUNT(CASE WHEN CONVERT(CHAR(6), W.[timestamp], 112) = '''
+ CONVERT(CHAR(6), @CurrMonth, 112) + ''' THEN 1 END) ';
SET @CurrMonth = DATEADD(MONTH, 1, @CurrMonth);
END;
SET @SQL = @SQL +
'FROM #customer AS C
INNER JOIN #widgets AS W
ON C.id = W.customer
GROUP BY C.prefix
ORDER BY C.prefix'
--PRINT @SQL
EXEC (@SQL)I've used these tables/data:
CREATE TABLE #customer(
[id] [int] NULL,
[name] [nchar](50) NULL,
[aliases] [nchar](120) NULL,
[prefix] [nchar](3) NULL,
[active] [int] NULL
)
CREATE TABLE #widgets(
[id] [nvarchar](50) NOT NULL,
[customer] [int] NOT NULL,
[name] [nvarchar](120) NOT NULL,
[timestamp] [datetime] NOT NULL,
[attributes] [nvarchar](120) NULL
)
INSERT INTO #customer (id,name,aliases,prefix,active)
VALUES (28,N'Inner Ciry Unit',N'ICU',N'ICU',1)
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181009' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181017' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V467934' ,28 ,N'AVFCCW001', '20181026' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181001' ,N'')
SELECT * FROM #customer
SELECT * FROM #widgets--Vadim R.
-
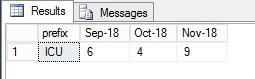
Hi, Thanks for that but it's still not delivering the correct answer.
It's counting the the amount of entries for the time period (4) and not the amount of unique widget codes (2).
In your data above there are 4 entries in the #widget table for October which have 2 widget codes (V436114 and V467934).
What i'm trying to do is return the count of unique codes for a given month. So it should return a value of 2 and not 4.
Here's some more test data to show what I mean :
CREATE TABLE #customer(
[id] [int] NULL,
[name] [nchar](50) NULL,
[aliases] [nchar](120) NULL,
[prefix] [nchar](3) NULL,
[active] [int] NULL
)
CREATE TABLE #widgets(
[id] [nvarchar](50) NOT NULL,
[customer] [int] NOT NULL,
[name] [nvarchar](120) NOT NULL,
[timestamp] [datetime] NOT NULL,
[attributes] [nvarchar](120) NULL
)
INSERT INTO #customer (id,name,aliases,prefix,active)
VALUES (28,N'Inner Ciry Unit',N'ICU',N'ICU',1)
/*** Sep 2018 ***/
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20180903' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20180908' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20180915' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20180921' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20180926' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20180929' ,N'')
/*** Oct 2018 ***/
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181009' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181017' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V467934' ,28 ,N'AVFCCW001', '20181026' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181001' ,N'')
/*** Nov 2018 ***/
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181101' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181113' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V467934' ,28 ,N'AVFCCW001', '20181126' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181119' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V467934' ,28 ,N'AVFCCW001', '20181122' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V436114' ,28 ,N'BCFCW001', '20181128' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V469691' ,28 ,N'SMFCW001', '20181108' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V469691' ,28 ,N'SMFCW001', '20181114' ,N'')
INSERT INTO #widgets (id,customer,name,[timestamp],attributes)
VALUES (N'V469691' ,28 ,N'SMFCW001', '20181128' ,N'')Running this code
SELECT
C.prefix
,[Sep-18] = COUNT(CASE WHEN CONVERT(CHAR(6), W.[timestamp], 112) = '201809' THEN 1 END)
,[Oct-18] = COUNT(CASE WHEN CONVERT(CHAR(6), W.[timestamp], 112) = '201810' THEN 1 END)
,[Nov-18] = COUNT(CASE WHEN CONVERT(CHAR(6), W.[timestamp], 112) = '201811' THEN 1 END)
FROM #customer AS C
INNER JOIN #widgets AS W
ON C.id = W.customer
GROUP BY C.prefix
ORDER BY C.prefixWould give the results :
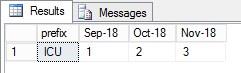
But this is counting the entries for the time period. I need it to count the amount of distinct widget codes, so for the above example the result should be:
Any ideas? Thanks!
-
Then change it to a
DISTINCTcount and return the value ofW.idinstead of1:SELECT C.prefix,
COUNT(DISTINCT CASE WHEN CONVERT(char(6), W.[timestamp], 112) = '201809' THEN W.id END) AS [Sep-18],
COUNT(DISTINCT CASE WHEN CONVERT(char(6), W.[timestamp], 112) = '201810' THEN W.id END) AS [Oct-18],
COUNT(DISTINCT CASE WHEN CONVERT(char(6), W.[timestamp], 112) = '201811' THEN W.id END) AS [Nov-18]
FROM #customer AS C
INNER JOIN #widgets AS W ON C.id = W.customer
GROUP BY C.prefix
ORDER BY C.prefix;Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
Hi Thom,
Sorry for the late reply. That was perfect. Thanks !
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply