

What is an Index?
We often hear indexes explained using the analogy of an index in the back of a book. You want to find the information about “rabbits” for instance – and so you look that up in the back and find the list of pages that talk about rabbits.
That’s kind of a handy description but I find it’s not the best for understanding what’s really going on. I often describe an index as a subset or different representation of the data in your table, ordered to be of particular benefit to querying the data in a certain way. Maybe you want to query the data by Created Date – let’s have an index then in the order of that date to make it easy to find stuff.
But important to understand is…
Your table is itself an index
At least I hope so. When you create a table, hopefully you define a primary key. When you do so SQL Server will automatically define what’s called a Clustered Index based on whatever you’ve specified as the primary key. The Clustered Index (and you can only have one on a table for obvious reasons) defines the order that the data in the table will be stored on disk. The data itself is stored in a structure that is the same as any other index you define on the table (we call these non-clustered indexes) just with a few differences in exactly what is stored.
So there is no separate “table” stored on the disk in some manner, there are just indexes – the Clustered one and any non-Clustered indexes you create.
I say I hope though – because you might have decided – or have neglected – to define a primary key. Or you might have deliberately stopped SQL from creating a Clustered index. Then you are saying you don’t want to specify in what order the data is stored – “Just chuck it down there, I don’t care!” and then you have what is known as a Heap. A Heap is just a pile of data in no specified order, and whenever you want to read from it you’re going to have to scan the whole thing to find whatever you want.
We don’t like Heaps!
You might think “well, that sounds like a quick way of writing data to disk, and I’m hardly ever going to read the data from this table but I write to it a lot, so a heap sounds great”.
True, there are some edge cases where a heap is appropriate, but they really are edge cases. If you ever think a heap is the way to go, then set up a scalability test to prove it achieves what you want.
In general when you’re creating a new table, you want to think carefully about what the primary key and clustered index should be (maybe they should, but maybe they shouldn’t be the same), based on how the data is going to be written and read.
What does an index look like?
So you’ve got a table, and its physical representation on disk is as a clustered index, the picture below shows how that actually looks in logical terms:
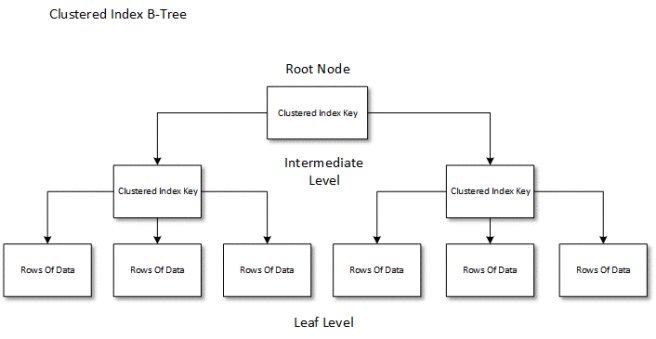
This something called a B-tree, the B is generally agreed to stand for “balanced”, the idea being that you have to traverse the same amount of steps to find any piece of data. I don’t want to go into process this in ultimate depth, but let’s cover what’s useful.
We have a Root Node and an Intermediate Level – these (like all data in SQL Server) are made up of 8KB pages. At the root and intermediate level these just contain the Clustered Key ranges (as noted above this defaults to the Primary Key you defined) and pointers where to find those Key values on the next level down. Then we have the leaf level which contains the data itself, 8KB pages containing the complete rows of data. So if we’re looking for a particular record e.g. Id = 12, we can route quickly through the top levels to find exactly the page we want. This is much quicker than having to scan all the Leaf pages.
A non-clustered index is basically the same structure:
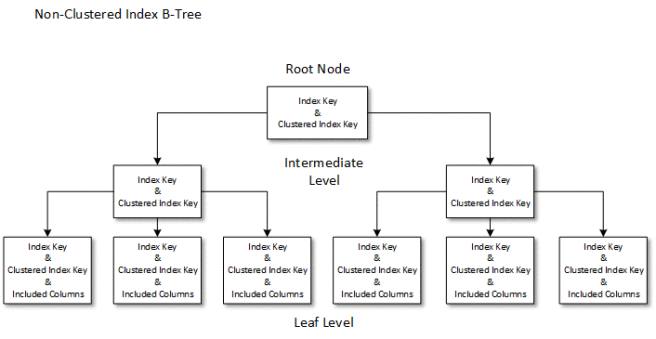
You’ll see that the Root and Intermediate levels contain both the Index Key and the Clustered key. The Index key is whatever you decided to define an index on – in the above example this might be Created Date, and assuming we’re searching based on that SQL will use this index to quickly find the leaf page containing the data we want.
The main difference is at the leaf level. Here we don’t hold the complete row of data. We hold the Index key and the clustered key. If your query just wants to grab the clustered key value (often the Id) then that is fine. If it wants additional data then it can use that key value to look up the data you require in the Clustered Index. So effectively your query uses this index to gather the Clustered Index value (or values) for the rows it wants and then uses the Clustered index to get any extra data it wants.
You’ll see that can mean that we’re actually using two indexes to satisfy a query. That’s why we also have at the leaf level what you’ll see referred to as “Included Columns”. When you define an index you can choose extra columns to be stored in the leaf level pages (using the INCLUDE statement). Let’s say I’m looking at a table called Users and I want to be able to grab the email address for a user called “mcgiffen”. I can create an non-clustered index on Username and tell SQL to include the column EmailAddress. Then the query will find all the data it needs in the non-clustered index and doesn’t need to refer back to the clustered one.
When we create a non-clustered index that will serve all the needs of a particular query in this way (or set of queries) we call that a covering index for that query. A query is always going to be faster if it has a covering index.
But doesn’t that mean I’m writing the same data in multiple places?
You’ll see from the above why I refer to an index as a subset/different representation of the table itself (which hopefully is also an index). And yes – that does mean that when you’re writing to a table with multiple indexes you are actually writing some of the same data to multiple separate structures. I know… that sounds horribly inefficient.
Let’s think about a table with 100,000 rows containing information about people. Let’s say I sometimes access the data by Id value and that is the primary and clustered key. But I also access it based on the person’s name and that’s equally often so I’ve created an index on their name.
I also read from the table a lot more than I write to it, I want to access the data about a person far more often than I want to change it. Sure, when I write to it, I have to write some of the data twice, but if I didn’t have that extra index on their name, then every time I wanted to query by a person’s name I’d have to read all 100,000 rows. So I have to do one more write, but I save all those reads. That’s a pretty good trade off.
It does mean though that you want to be effective with your indexing, you don’t just want to throw every index you can think of at a table and you want to try and make indexes that can satisfy the needs of multiple queries.
From SQL Server 2008 you can have up to a thousand indexes on a table. Generally though, up to 4 seems reasonable – and if you’ve got more than 15 then that’s raising a red flag.
However there’s no hard and fast answer about how many indexes you should have, it depends on the balance of reads and writes, and it depends on the different types of access you have to the table. In general, it is good to have an index on any column that acts as a Foreign Key, and columns that will be used as the main predicates when querying a table are also good candidates to be indexed.
But be careful when adding a new index and monitor to make sure it hasn’t actually slowed things down – not just the query you’re working on but any other existing queries that use the same table as your index may change the way they work too.

![]()
