

Intro
AlwaysOn availability groups are a powerful enhancement to SQLServer HA, and offer many improvements over older database synchronization techniques like mirroring and log shipping. However, there is also additional complexity involved in implementing this technology, and one of the stickiest areas for database administrators is having to deal with non-contained objects, or objects that exist at the instance level, but not the database level (logins vs users, as an example).
For new development, contained vs. uncontained objects can be accounted for and considered during application design. But what about those existing mission critical legacy applications that we want to benefit from AlwaysOn? Those are, undoubtedly, the instances that would benefit from automated failover and read / write workload balancing the most! Well, fortunately these older implementations can be modified to work seamlessly with AlwaysOn, but the instances they run on will most likely need some intelligent customization. Here’s one situation you might encounter: legacy applications using SQL Agent jobs to update data on a schedule.
Overview
In SQL Server AlwaysOn, all system level objects are non-synchronized, including SQL Agent. The assumption is that all applications need only database level objects to function, and that system level objects are only required for maintenance and administration of the instance. I had a client with a legacy mission critical application that they wanted to implement with AlwaysOn. This application relied and several SQL agent jobs to update data on a scheduled basis in order to maintain application integrity. Less then optimal, I know, but that’s what you get with legacy. The blocker with this implementation is that the jobs would fail if executed on a secondary replica, because the primary is the only write enabled replica.
So, how do we customize AlwaysOn replicas to ensure that these agent jobs are always and only running on the primary replica?
Solution
The solution I implemented is composed of four parts: A system function, a user stored procedure, a SQL Agent job, and a SQL Agent alert. The key to this implementation is ensuring that all of the jobs you need to manage are maintained in their own user defined category(s).
System Function
Microsoft provides us with a handy-dandy little system function: sys.fn_hadr_is_primary_replica. This function accepts one parameter, @dbname sysname, the name of a synchronized database, and “returns 1 if the current instance is primary replica; otherwise returns 0.” This is what we’ll use in our procedure to determine whether to enable or disable the read/write SQL Agent jobs.
Stored Procedure
We can now create a stored procedure to enable / disable SQL Agent jobs in a user defined category based on, coincidentally, the same bit value that sys.fn_hadr_is_primary_replica returns:
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
/* =============================================
-- Author:Jared Zagelbaum, jaredzagelbaum.wordpress.com
-- Follow me on twitter: @JaredZagelbaum
-- Create date: 4/23/2015
-- Description:Enables Read / Write jobs on primary replica after failover
-- Can be executed from failover alert and / or recurring schedule
-- =============================================
*/CREATE PROCEDURE [dbo].[JobChange_AGFailover]
(
@databasename sysname
,@jobcategory sysname
)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @jobID UNIQUEIDENTIFIER --variable for job_id
DECLARE @AG_enable tinyint
select @AG_enable = sys.fn_hadr_is_primary_replica (@databasename)
DECLARE jobidCursor CURSOR FOR --used for cursor allocation
SELECT j.job_id
FROM msdb.dbo.sysjobs j
INNER JOIN msdb.dbo.syscategories c
ON j.category_id = c.category_id
where c.name = @jobcategory
--update jobs
OPEN jobidCursor
FETCH NEXT FROM jobidCursor INTO @jobID
WHILE @@Fetch_Status = 0
BEGIN
EXEC msdb.dbo.sp_update_job @job_id=@jobID, @enabled = @AG_enable
FETCH Next FROM jobidCursor INTO @jobID
END
CLOSE jobidCursor
DEALLOCATE jobidCursor
END
GO
SQL Agent Job
Having fun yet!? Now we can add this s proc to a job. Here’s a script that will create the job for you using the much preferred CmdExec method (assuming you create [dbo].[JobChange_AGFailover] in master). Make sure you update the supplied values where noted.
USE [msdb]
GO
/****** Object: Job [AG Failover Replica Changes] Script Date: 5/5/2015 2:17:49 PM ******/BEGIN TRANSACTION
DECLARE @ReturnCode INT
SELECT @ReturnCode = 0
IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1)
BEGIN
EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
END
DECLARE @jobId BINARY(16)
EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'AG Failover Replica Changes',
@enabled=1,
@notify_level_eventlog=2,
@notify_level_email=2,
@notify_level_netsend=0,
@notify_level_page=0,
@delete_level=0,
@description=N'Enables / Disables read-write jobs against replicas when failover role change occurs',
@category_name=N'[Uncategorized (Local)]',
@owner_login_name=N'sa',-- change if necessary per your environment
@notify_email_operator_name=N'DBAdmins',-- change to your default operator
@job_id = @jobId OUTPUT
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
/****** Object: Step [Exec JobChange_AGFailover] Script Date: 5/5/2015 2:17:49 PM ******/EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Exec JobChange_AGFailover',
@step_id=1,
@cmdexec_success_code=0,
@on_success_action=1,
@on_success_step_id=0,
@on_fail_action=2,
@on_fail_step_id=0,
@retry_attempts=0,
@retry_interval=0,
@os_run_priority=0, @subsystem=N'CmdExec',
@command=N'sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q "EXECUTE [dbo].[JobChange_AGFailover] @Databasename = ''Databasename'', @jobcategory = ''jobcategory'' " -b', --supply your own databasename and jobcategory parameter values
@output_file_name=N'$(ESCAPE_SQUOTE(SQLLOGDIR))\AGFailover_$(ESCAPE_SQUOTE(JOBID))_$(ESCAPE_SQUOTE(STEPID))_$(ESCAPE_SQUOTE(STRTDT))_$(ESCAPE_SQUOTE(STRTTM)).txt',
@flags=0
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)'
IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
COMMIT TRANSACTION
GOTO EndSave
QuitWithRollback:
IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION
EndSave:
GO
SQL Agent Alert
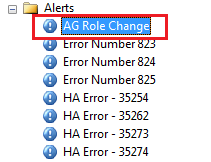
Finally, lets create an alert to trigger this job whenever a failover occurs. The alert should be raised based on Error number 1480. Here’s a script for it:
USE [msdb] GO EXEC msdb.dbo.sp_add_alert @name=N'AG Role Change', @message_id=1480, @severity=0, @enabled=1, @delay_between_responses=0, @include_event_description_in=1, @category_name=N'[Uncategorized]', @job_name=N'AG Failover Replica Changes' GO
Result
You should now have an instance of each of these objects on all of your replicas:
Stored Procedure:

SQL Agent Job:

SQL Agent Alert:
Alright, we now have an automated way of enabling and disabling read / write SQL Agent jobs based on whether the replica role is primary or secondary. The alert will be raised whenever a failover occurs. If, for some reason the alert does not trigger successfully (I’ve not encountered this), you can always start the job manually on the affected replica as well.
The final result that we want is that SQL jobs that edit data are disabled on secondary replicas and enabled only on the primary by job category. Multiple jobs and alerts can be added for different databases and/ or categories. You can view the enabled property value easily under Job Activity Monitor in SQL Server Agent.
Hope this helps!
