Intro
I’m working on a solution where warehouse uses string codes as the keys for dimensions. Therefore the fact table is a multi-column table which contains strings (nvarchar(30)) in most of the columns. We have around a billion records and we would like to extend our solution. However, we have an issue with memory during the processing. One of the reasons could be just the fact we use nvarchar strings, as data needs to be uncompressed for some time in memory. At least in the size of two segments as one is in compressing and one is in reading queue. The questions which I would like to test:
- Is there a difference in speed and memory consumption when we use varchar instead of nvarchar?
- What is the difference in memory, duration and size of the model, when we re-code dimensions and use surrogate integer key?
For the test I’ve created artificial data with value distribution described below. The test is a bit extreme but it’s on purpose to clearly see the potential difference.
Test Description:
- Three tables (clustered column store compressed in DB), 50 columns, 100k different values in each column randomly generated strings (length 30 characters), 12 200 000 rows.
- Table1 – all columns nvarchar
- Table 2 – all columns varchar
- Table 3 – all columns integers + 50 satellite tables with two columns – ID + Nvarchar30
- SSAS Tabular Segment size 3mio.
- VertiPaq paging disabled.
- SSAS – No Partitions
- Processing Strategy – Fact Full process one batch then Full process of all Satellites in one batch.
- All tests repeated several times to confirm results.
Test Result:
Let’s start with Database storage:
| Table Data Type | Data GB | Satellite GB | Total GB |
| Nvarchar | 3.20 | 0.00 | 3.20 |
| Varchar | 1.97 | 0.00 | 1.97 |
| INT + Satellite | 0.47 | 0.38 | 0.85 |
Statistics by Vertipaq Analyzer in Bytes
| Data Type | Data Size | Dictionary Size | Relationships Size | 50 Satellite Size | Total Size |
| Nvarchar | 300,048,000 | 460,223,792 | 760,271,792 | ||
| Varchar | 294,992,800 | 460,223,792 | 755,216,592 | ||
| INT | 305,129,600 | 6,120 | 13,334,000 | 474,700,272 | 793,169,992 |
Processing statistics – Memory
Fact Memory (GB) | Satellite Memory (GB) | Model Memory (GB) | |||||||||
| Scenario | Start Mem | Max Mem | End Mem | Delta Begin – End | Max Delta | Start Mem | Max Mem | End Mem | Max delta | Mem after restart | Model Size |
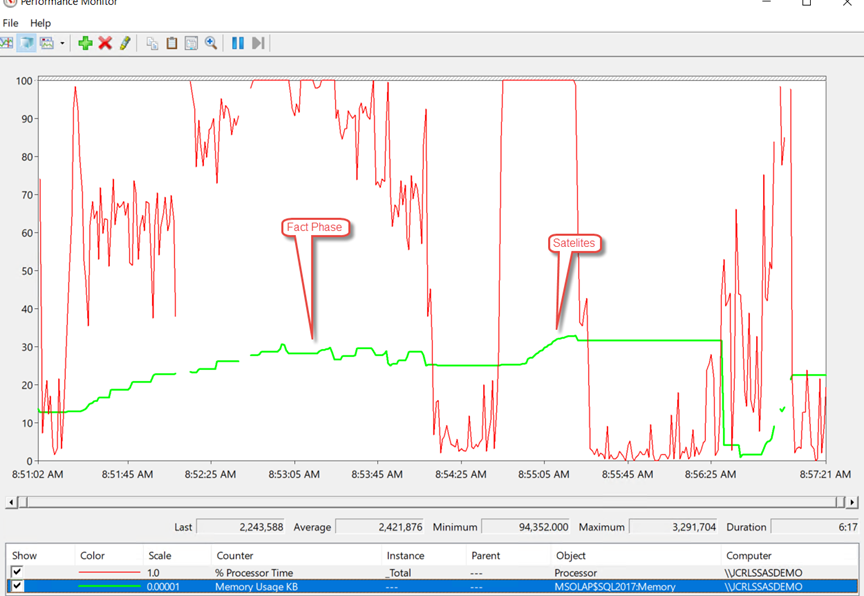
| Nvarchar | 1.45 | 3.06 | 2.57 | 1.12 | 1.61 | 1.88 | 0.43 | ||||
| Varchar | 1.35 | 3.27 | 2.64 | 1.29 | 1.92 | 1.82 | 0.47 | ||||
| INT + Satellite fact first | 1.70 | 3.60 | 2.75 | 1.05 | 1.90 | 2.75 | 3.34 | 3.1 | 0.59 | 2.25 | 0.55 |
| INT + Satellite dim first | 1.88 | 3.75 | 3.60 | 1.72 | 1.87 | 1.32 | 2.05 | 1.88 | 0.73 | 2.21 | 0.89 |
Processing Statistics – Duration
Duration (min) | ||
| Scenario | Fact | Satellite |
| Nvarchar | 12:05 | |
| Varchar | 14:47 | |
| INT + Satellite fact first | 2.49 | 0:43 |
| INT + Satellite dim first | 3:13 | 0:55 |
Key Takeaways:
- There is not much of a difference between Nvarchar and Varchar – this is basically expected as SSAS Tabular do not at the end have Varchar Type and internally handles everything as nvarchar.
- Regarding memory consumption there is not much of a difference between INT and NVARCHAR. This was a surprise for me as I would expect uncompressed segments having in memory would fit byte-based calculation so nvarchar should have much higher consumption. Any thoughts on this?
- Speed of processing is much faster for INT based fact table. – The magnitude of the difference surprised me. But further investigation confirmed it’s just about the speed of data load on my virtual machine. When tested on our prod-like environment with wider table we had 10% difference only from data load speed perspective int vs nvarchar.
- Dictionary size can differ per processing. – Once 300MB and once 450MB not sure about exact reason for seeing this. I wouldn’t be surprised when data size would differ with each processing because of choosing different sort order. But why dictionary size?
- There is not much of a difference in model size between INT and Nvarchar – on the other hand as encoding of fact key column is value based = near zero size dictionary (Need to be set by hint (SSAS2017 only), otherwise you will get hash encoding despite of INT datatype). Effect would be more visible with bigger fact table. So, INT based model should ultimately be smaller.
- There is significant saving in DB storage when using smaller datatypes. No surprise here.
- It seems order matters – Processing first facts and then satellite tables is slightly faster (tested several times)
- Processing process is not willing to give up all memory after processing finishes. (this was the reason I did a restart after each test and measured the difference of memory before processing start and after restart – assuming delta is real model size in memory.
Next time I’ll try to compare Query duration between Nvarchar and INT based model to see the potential impact on queries. Feel free to leave a comment or contact me if you have any input or experience with this topic.
Appendix for those curious:
Varchar Memory/CPU behavior during processing
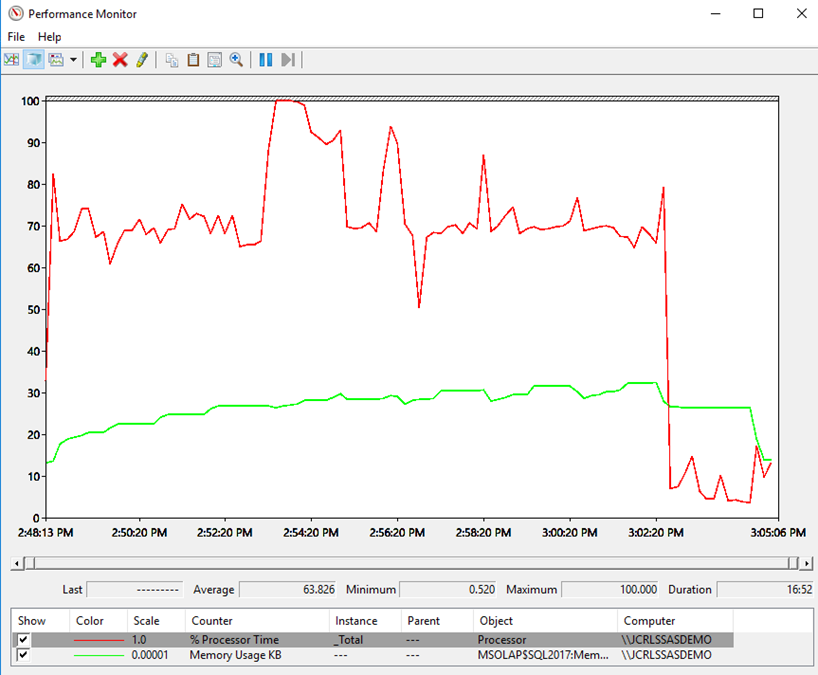
Nvarchar Memory/CPU behavior during processing
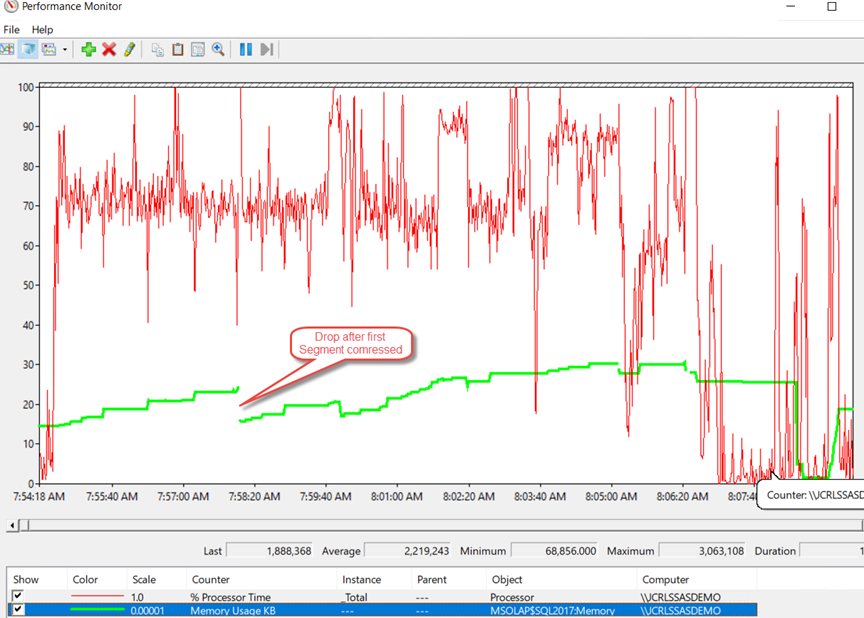
Int Memory/CPU behavior during processing (fact first)
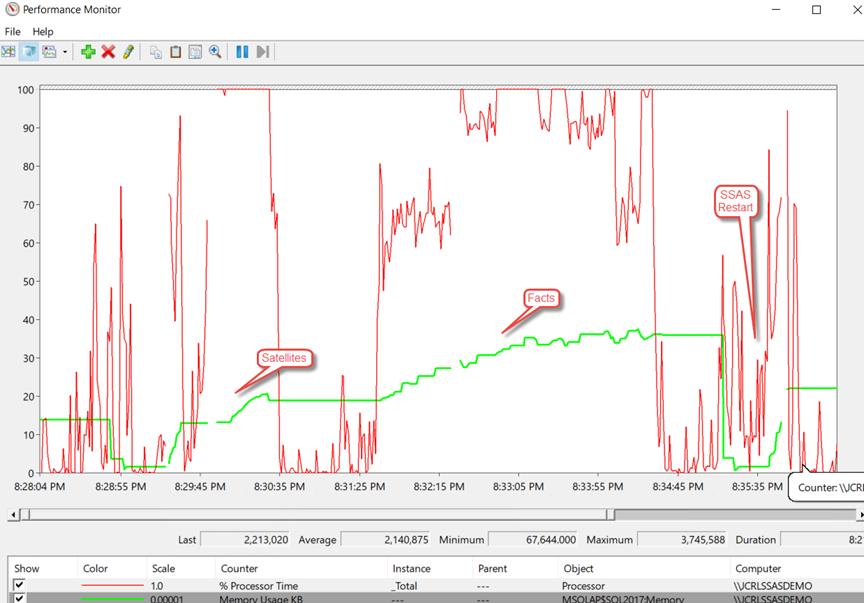
Int Memory/CPU behavior during processing (dimension first)