

By Steve Bolton
…………The last installment of this amateur series of self-tutorials was the beginning of a short detour into using SQL Server to perform goodness-of-fit testing on regression lines, rather than on probability distributions. These are actually quite simple concepts; any college freshman ought to be able to grasp the idea of a single regression line, since all they do is graph the values of one variable as it changes in tandem with another, whereas distributions merely summarize the distinct counts for each value of a variable, as the famous bell curve does. In the first case we’re dealing with how well a regression line models the relationship between two variables – assuming one exists – and in the second, we’re assessing whether the distribution of a single variable matches one of many distributions that constantly recur in nature, like the Gaussian “normal” distribution, or other common ones like the Poisson, binomial, uniform and exponential distributions.
…………These topics can of course become quite complex rather quickly once we factor in modifications like multivariate cases, but I’ll avoid these topics for the sake of simplicity, plus the fact that there are an endless number of variants of them that could keep us busy to the end of time. I really can’t end this segment though without addressing a particular variant, since logistic regression is a widely used algorithm that addresses a distinctive set of use cases. There is likewise an endless array of alternative takes on the basic logistic regression algorithm, such as adaptations for multinomial cases, but I’ll stick to the old maxim, KISS: Keep It Simple, Stupid. The Hosmer-Lemeshow Test that is commonly used for fitness testing on logistic regression may not be applicable in some of these more advanced cases, but it is indispensable for the bare bones version of the algorithm.
Adapting Regression Lines to Use the Logistic Function
This regression algorithm is a topic I became somewhat familiar with while writing A Rickety Stairway to SQL Server Data Mining, Algorithm 4: Logistic Regression a while back, in a different tutorial series. Suffice it to say that the algorithm is ideal for situations in which you need to place bounds on the outputs that a regression line can generate; most commonly this is a Boolean yes-no choice that ranges between 0 and 1, but it can be adapted to other scales, such as 0 to 100. A linear regression line would produce nonsensical values in these instances, since the values would be free to go off the charts, but a logistic regression is guaranteed to stay within its assigned bounds. This is accomplished by using the logistic function, which is really not much more difficult to implement than linear regression (with one critical limitation). The formula is widely available on the Internet, so when writing the code for this article I retrieved it from the most convenient source as usual: Wikipedia.[1]
…………In many ways, the logistic function behaves like the cumulative distribution functions (CDFs) I mentioned in Goodness-of-Fit Testing with SQL Server, Part 2: Implementing Probability Plots in Reporting Services, in that the probabilities assigned to the lowest value begin at 0 and accumulate up to 1 by the time we reach the final value in an ordered dataset. It also behaves in many ways like a weighted function, in that the pressure on it to conform to the bounds increases as it nears them; I think of it in terms of the way quarks are inextricably bound together by the strong force within hadrons, which increases as they come closer to breaking free. In between the upper and lower bounds the regression takes on the appearance of an S-curve rather than the lines seen in normal regression.
…………Another easily readable and insightful commentary on logistic regression can be found at University of Toronto Prof. Saed Sayad’s website[2], in which he provides a succinct explanation of the logistic function equation and some alternative measures for the accuracy of the mining models it generates. Three of these are subspecies of the R2 measure we discussed last week in connection with linear regression, which are discussed together under the rubric of Pseudo R2. Fitness testing of this kind is as necessary on regression lines as it is for distribution matching, because they rarely model the relationships between variables perfectly; as statistician George Box (one of the pioneers of Time Series) once put it so colorfully, “All models are wrong, but some are useful.”[3] Sayad also mentions alternative methods like Likelihood Ratio tests and the Wald Test. The measure of fit I’ve seen mentioned most often in connection with logistic regression goes by the memorable moniker of the Hosmer-Lemeshow Test. It apparently has its limitations, as we shall see, but it is not terribly difficult to implement – with some important caveats.
Banding Issues with Coding the Hosmer-Lemeshow Test
In fact, the first three steps in the dynamic SQL in Figure 1 are almost identical to those used to calculate regression lines in last week’s article and a tutorial from a different series, Outlier Detection with SQL Server Part 7: Cook’s Distance, which I won’t waste time recapping here.[4] The fourth step just applies the logistic function to the results, in a single, simple line of T-SQL. After this, I simply insert the logistic regression values into a table variable for later retrieval, including returning it to the user towards the end of the procedure; there’s really no reason not to return the correlation, covariance, slope, intercept and standard deviations for both variables as well, given that we’ve already calculated them. Step 5 is where the meat and potatoes of the Hosmer-Lemeshow Test can be found. Its strategy is essentially to divide the values into bands, which are often referred to as “deciles of risk” when the test is employed in one of its most common applications, risk analysis.[5] The bands are then compared to the values we’d expect for them based on probabilistic calculations and the gap between them is quantified and summarized.
…………It is now time for my usual disclaimer: I am writing this series in order to familiarize myself with these data mining tools, not because I have expertise in using them, so it would be wise to check my code thoroughly before putting it to use (or even, God forbid, a production environment). Normally I check my code against the examples provided in various sources, especially the original academic papers whenever possible. In this case, however, I couldn’t find any at a juncture where they would have come in handy, given that I am not quite certain that I am splitting the data into bands on the right axis. I am still learning how to decipher the equations that underpin algorithms of this kind and some of them differ significantly in notation and nomenclature, so it may be that I ought to be counting the observed and expected values differently, which affects how they are split; from the wording in a book inventors David W. Hosmer Jr. and Stanley Lemeshow wrote on Applied Logistic Regression, it seems that the counts between the bands are supposed to vary much more significantly[6] than they do in my version, which could be a side effect of incorrect banding. There are apparently many different ways of doing banding[7], however, including my method below, in which the @BandCount parameter is plugged into the NTILE windowing function in Step 1.
…………I’ve seen two general rules of thumb mentioned in the literature for setting the @BandCount to an optimal level: using groups of fewer than five members leads to incorrect results, while using fewer than six groups “almost always” leads to passing the fitness test.[8] Averages for both the X and Y axes are calculated for each band, then the regression line is derived through the usual methods in Steps 3 through 5, with one crucial difference: some of the aggregates have to be derived from the bands rather than the original table, otherwise we’d end up with an apples vs. oranges comparison. This is one of several points where the procedure can go wrong, since the banding obscures the detail of the original table and can lead to a substantially different regression line. Keep in mind though that the literature mentions several alternative methods of banding, so there may be better ways of accomplishing this.
Figure 1: T-SQL Code for the Hosmer–Lemeshow Test Procedure
CREATE PROCEDURE [Calculations].[GoodnessOfFitLogisticRegressionHosmerLemsehowTestSP]
@DatabaseName as nvarchar(128) = NULL, @SchemaName as nvarchar(128), @TableName as nvarchar(128),@ColumnName1 AS nvarchar(128),@ColumnName2 AS nvarchar(128), @BandCount As bigint
AS
DECLARE @SchemaAndTableName nvarchar(400),@SQLString nvarchar(max)
SET @SchemaAndTableName = @DatabaseName + ‘.’ + @SchemaName + ‘.’ + @TableName
SET @SQLString = ‘DECLARE @MeanX float,@MeanY float, @StDevX float, @StDevY float,
@Count float, @Correlation float, @Covariance float, @Slope float, @Intercept float,
@ValueRange float, @HosmerLemeshowTest float
— STEP #1 — GET THE RANGE OF VALUES FOR THE Y COLUMN
SELECT @ValueRange = CASE WHEN RecordCount % 2 = 0 THEN ValueRange + 1 ELSE ValueRange END
FROM (SELECT Max(‘ + @ColumnName2 + ‘) – Min(‘ + @ColumnName2 + ‘) AS ValueRange, Count(*) AS RecordCount
FROM ‘ + @SchemaAndTableName + ‘
WHERE ‘ + @ColumnName2 + ‘ IS NOT NULL) AS T1
— STEP #2 — CREATE THE BANDS
DECLARE @LogisticRegressionTable table
(ID bigint, — ID is the decile identifier
CountForGroup bigint,
AverageX float,
AverageY float,
RescaledY float,
LogisticResult float
)
INSERT INTO @LogisticRegressionTable
(ID, CountForGroup, AverageX, AverageY)
SELECT DISTINCT DecileNumber, COUNT(*) OVER (PARTITION BY DecileNumber) AS CountForGroup , Avg(CAST(‘ + @ColumnName1 + ‘ AS float)) OVER
(PARTITION BY DecileNumber ORDER BY DecileNumber) AS AverageX, Avg(CAST(‘ + @ColumnName2 + ‘ AS float)) OVER (PARTITION BY DecileNumber
ORDER BY DecileNumber) AS AverageY
FROM (SELECT ‘ + @ColumnName1 + ‘, ‘ + @ColumnName2 + ‘, NTILE(‘ + CAST(@BandCount AS nvarchar(128)) + ‘) OVER (ORDER BY ‘ + @ColumnName1 + ‘) AS DecileNumber
FROM ‘ + @SchemaAndTableName + ‘) AS T1
UPDATE @LogisticRegressionTable — this could be done in one step, but Im leaving it this way for legibility purposes
SET RescaledY = AverageY / @ValueRange
— STEP #3 – RETRIEVE THE GLOBAL AGGREGATES NEEDED FOR
OTHER CALCULATIONS
— note that we cant operate on the original table here, otherwise the stats would be different from those of the bands
SELECT @MeanX = Avg(CAST(X AS float)), @MeanY = Avg(CAST(Y AS float)), @StDevX = StDev(CAST(X AS float)), @StDevY = StDev(CAST(Y AS float))
FROM (SELECT ‘ + @ColumnName1 + ‘ AS X, ‘ + @ColumnName2 + ‘ AS Y
FROM ‘ + @SchemaAndTableName + ‘
WHERE ‘ + @ColumnName1 + ‘ IS NOT NULL AND ‘ + @ColumnName2 + ‘ IS NOT NULL) AS T1
— STEP #4 – CALCULATE THE CORRELATION (BY FIRST GETTING THE COVARIANCE)
SELECT @Covariance = SUM((AverageX – @MeanX) * (AverageY – @MeanY)) / (‘ + CAST(@BandCount AS nvarchar(128)) + ‘ – 1)
FROM @LogisticRegressionTable
SELECT @Correlation = @Covariance / (@StDevX * @StDevY)
— STEP #5 – CALCULATE THE SLOPE AND INTERCEPT
SELECT @Slope = @Correlation * (@StDevY / @StDevX)
SELECT @Intercept = @MeanY – (@Slope * @MeanX)
— STEP #6 – CALCULATE THE LOGISTIC FUNCTION
UPDATE T1
SET LogisticResult = 1 / (1 + EXP(-1 * (@Intercept + (@Slope * AverageX))))
FROM @LogisticRegressionTable AS T1
— RETURN THE RESULTS
SELECT @HosmerLemeshowTest = SUM(Power((RescaledY – LogisticResult), 2) / (CountForGroup * LogisticResult * (1- LogisticResult)))
FROM @LogisticRegressionTable AS T1
SELECT * FROM @LogisticRegressionTable
SELECT @HosmerLemeshowTest AS HosmerLemeshowTest, @Covariance AS Covariance, @Correlation AS Correlation, @MeanX As MeanX, @MeanY As MeanY, @StDevX as StDevX, @StDevY AS StDevY, @Intercept AS Intercept, @Slope AS Slope‘
–SELECT @SQLString — uncomment this to debug dynamic SQL errors
EXEC (@SQLString)
…………Another potential problem arises when we derive the expected values of column Y for each band, using the logistic function in Step 6.[9] This is one of those maddening scaling issues that continually seem to arise whenever these older statistical tests are applied to Big Data-sized recordsets. This very simple and well-known function is implemented in the formula 1 / (1 + EXP(-1 * (@Intercept + (@Slope * AverageX)))), but when the result of the exponent operation is an infinitesimally small value, it gets truncated when adding the 1. This often occurs when the values for the @Intercept are high, particularly above 100. When 1 is divided by the resulting 1, the logistic function result is 1, which leads to division by zero errors when calculating the test statistic in the last SELECT assignment. There might be a way for a more mathematically adept programmer to rescale the @Intercept, @Slope and other variables so that this truncation doesn’t occur, but I’m not going to attempt to implement a workaround unless I’m sure it won’t lead to incorrect results in some unforeseen way.
…………Yet another issue is that my implementation allows the second column to be Continuous rather than the usual Boolean either-or choice seen in simple logistic regression. That requires rescaling to the range of permissible values, but the way I’ve implemented it through the RescaledY table variable column and @ValueRange variable may be incorrect. The SELECT that assigns the value to @HosmerLemeshowTest can also probably be done a little more concisely in fewer steps, but I want to highlight the internal logic so that it is easier to follow and debug. The rest of the code follows much the same format as usual, in which null handling, SQL injection protection, bracket handling and validation code are all omitted for the sake of legibility and simplicity. Most of the parameters are designed to allow the user to perform the regression on any two columns in the same table or view, in any database they have sufficient access to. The next-to-last line allows programmers to debug the dynamic SQL, which will probably be necessary before putting this procedure to professional use. In the last two statements I return all of the bands in the regression table plus the regression stats, since the costs of calculating them have already been incurred. It would be child’s play for us to also calculate the Mean Squared Error from these figures with virtually no computational cost, but I’m not yet sure if it enjoys the same validity and significance with logistic regression as it does with linear.
Figure 2: Sample Results from Duchennes and Higgs Boson Datasets
EXEC Calculations.GoodnessOfFitLogisticRegressionHosmerLemsehowTestSP
@DatabaseName = N’DataMiningProjects’,
@SchemaName = N’Physics’,
@TableName = N’HiggsBosonTable’,
@ColumnName1 = N’Column1′,
@ColumnName2 = N’Column2′,
@BandCount = 12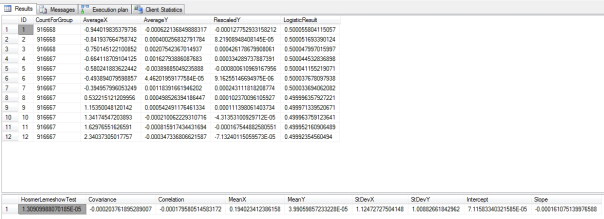
…………I’ve tested most of the procedures for the last two tutorial series against a 9-kilobyte dataset on the Duchennes form of muscular dystrophy, which is made publicly available by Vanderbilt University’s Department of Biostatistics. For this week’s article, however, the intercepts were too high for most combinations of comparisons between the PyruvateKinase, CreatineKinase, LactateDehydrogenase and Hemopexin columns, resulting in the aforementioned divide-by-zero errors. For the few combinations that worked, the test statistic was ridiculously inflated; for other databases I’m familiar with, it returned results in the single and double digits (which is apparently permissible, since I’ve seen professionals post Hosmer-Lemeshow results online that fall in that range) but for whatever reason, this was not the case with Duchennes dataset.
…………That is why I derived the sample results in Figure 2 from the first two float columns of the Higgs Boson Dataset I downloaded from University of California at Irvine’s Machine Learning Repository, which I normally use for stress-testing because its 11 million rows occupy nearly 6 gigabytes in the SQL Server table I converted it into. Given that the first column is obviously abnormal and the second clearly follows a bell curve, I expected the results to indicate a serious lack of fit, but the test statistic was only a minuscule 1.30909988070185E-05. In fact, the values seem to shrink in tandem with the record count, which makes me wonder if another, more familiar scaling issue is operative here. As we’ve seen through the last two tutorial series, many common statistical measures were not designed with today’s Big Data table sizes in mind and thus end up distorted when we try to cram too much data into them. Given that there are so many other issues with my implementation, it is hard to tell if that is an additional problem or some inaccuracy in my code. Substituting the AverageY value for the RescaledY I used in the test statistic only seems to introduce new problems, without solving this one.
The Case Against Hosmer-Lemeshow
…………Regardless of the quality of my implementation, the usefulness of the Hosmer-Lemeshow Test is apparently still questionable, given that even professionals publish articles with inspiring titles like “Why I Don’t Trust the Hosmer-Lemeshow Test for Logistic Regression.”[10] University of Pennsylvania Sociology Prof. Paul Allison lists several drawbacks to the test even when it is correctly implemented, including the most common one mentioned on the Internet, the weaknesses inherent in dividing the dataset into groups. This can even lead to significantly different results when different stats software is run against the same data.[11] Hosmer and Lemeshow themselves point out that the choice of boundaries (“cut points”) for the groups can lead to significantly different results.[12] Furthermore, as Frank Harrell puts it in a thread in the CrossValidated forum, “The Hosmer-Lemeshow test is to some extent obsolete because it requires arbitrary binning of predicted probabilities and does not possess excellent power to detect lack of calibration. It also does not fully penalize for extreme overfitting of the model. …More importantly, this kind of assessment just addresses overall model calibration (agreement between predicted and observed) and does not address lack of fit such as improperly transforming a predictor.”[13] He recommends alternatives like a “generalized R2,” while Allison gets into “daunting” alternatives like “standardized Pearson, unweighted sum of squared residuals, Stukel’s test, and the information matrix test.”[14]
…………Nevertheless, despite these well-known shortcomings, the Hosmer-Lemeshow Test remains perhaps the best-known goodness-of-fit measure for logistic regression. Fitness tests seem to have well-defined use cases in comparison to the outlier detection methods we covered in my last tutorial series, with the Hosmer-Lemeshow among those that occupy a very distinct niche. The other methods mentioned by these authors seem to be more advanced and less well-known, so I thought it still worthwhile to post the code, even if there are certain to be problems with it. On the other hand, it is not worth it at this point to optimize the procedures much until the accuracy issues can either be fixed or debunked. It performed well in comparison to other procedures in this series anyways, with a time of 3:08 for the trial run in Figure 2. Only 1 of the 8 queries accounted for 89 percent of the cost of the whole execution plan, and that one contained two expensive Nested Loops operators, which might mean there’s room for further optimization if and when the accuracy can be verified.
…………Given the number of issues with my code as well as the inherent issues with the test itself, it might be fitting to write a rebuttal to my mistutorial titled titled like Allison article, such as “Why I Don’t Trust Steve Bolton’s Version of the Hosmer-Lemeshow Test for Logistic Regression.” It may still be useful in the absence of any other measures, but I’d assign it a lot less trust than some of the other code I’ve posted in the last two series. On the other hand, this also gives me an opportunity to jump into my usual spiel about my own lack of trust in hypothesis testing methods. I have a lack of confidence in confidence intervals and the like, at least as far as our use cases go, for multiple reasons. First and foremost, plugging test statistics into distributions just to derive a simple Boolean pass/fail measure sharply reduces the information content. Another critical problem is that most of the lookup tables for the tests and distributions they’re plugged into stop at just a few hundred values and are often full of gaps; furthermore, calculating the missing values yourself for millions of degrees of freedom can be prohibitively expensive. Once again, these measures were designed long before Big Data became a buzz word, in an era when most statistical tests were done against a few dozen or few hundred records at best. For that reason I have often omitted the hypothesis testing stage that accompanies many of the goodness-of-fit measures in this series, including the Hosmer-Lemeshow Test, which is normally plugged into a Chi-Squared distribution.[15] On the other hand, we can make use of the separate Chi-Squared goodness-of-fit measure, which as we shall see next week, is a versatile metric that can be adapted to assess the fit of a wide variety of probability distributions – with a much higher degree of confidence than we can assign to the Hosmer-Lemeshow Test results on logistic regression.
[1] See the Wikipedia article “Logistic Regression” at http://en.wikipedia.org/wiki/Logistic_regression
[2] See Sayad, Saed, 2014, “Logistic Regression,” published at the SaedSayad.com web address http://www.saedsayad.com/logistic_regression.htm
[3] See the undated publication “Goodness of Fit in Linear Regression” retrieved from Lawrence Joseph’s course notes on Bayesian Statistics on Oct. 30, 2014, which are published at the website of the McGill University Faculty of Medicine. Available at the web address http://www.medicine.mcgill.ca/epidemiology/joseph/courses/EPIB-621/fit.pdf. No author is listed but I presume that Prof. Joseph wrote it.
[4] I derived some of the code for regular linear regression routine long ago from the Dummies.com webpage “How to Calculate a Regression Line” at http://www.dummies.com/how-to/content/how-to-calculate-a-regression-line.html
[5] See the Wikipedia article Hosmer-Lemeshow Test at the web address http://en.wikipedia.org/wiki/Hosmer%E2%80%93Lemeshow_test
[6] p. 160, Hosmer Jr., David W.; Lemeshow, Stanley and Sturdivan, Rodney X., 2013, Applied Logistic Regression. John Wiley & Sons: Hoboken, New Jersey.
[7] IBID., pp. 160-163.
[8] IBID., p. 161 for the second comment.
[9] I was initially confused about the assignment of the expected values (as well as the use of mean scores), but they are definitely derived from the logistic function, according to p. 2 of the undated manuscript, “Logistic Regression,” published at the Portland State University web address http://www.upa.pdx.edu/IOA/newsom/da2/ho_logistic.pdf . It is part of the instructional materials for one of Prof. Jason Newsom’s classes so I assume he wrote it, but cannot be sure.
[10] Allison, Paul, 2013, “Why I Don’t Trust the Hosmer-Lemeshow Test for Logistic Regression,” published March 5, 2013 at the Statistical Horizons web address http://www.statisticalhorizons.com/hosmer-lemeshow
[11] Allison, Paul, 2014, untitled article published in March, 2014 at the Statistical Horizons web address http://www.statisticalhorizons.com/2014/04
[12] pp. 965-966, 968, Hosmer, D.W.; T. Hosmer; Le Cessie, S. and Lemeshow, S., 1997, “A Comparison of Goodness-of-Fit Tests for the Logistic Regression Model,” pp. 965-980 in Statistics in Medicine. Vol. 16.
[13] Harrell, Frank, 2011, “Hosmer-Lemeshow vs AIC for Logistic Regression,” published Nov. 22, 2011 at the CrossValidated web address http://stats.stackexchange.com/questions/18750/hosmer-lemeshow-vs-aic-for-logistic-regression
[14] See Allison, 2014.
[15] For more on the usual implementation involving the Chi-Squared distribution, see p. 977. Hosmer et al., 1997 and p. 158, Hosmer et al. 2013.

![]()
