

The two latest trends in emerging data platform architectures are the Data Lakehouse (the subject of my last blog Data Lakehouse defined), and the Data Mesh, the subject of this blog.
Data Mesh was first introduced by ThoughtWorks via the blog How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. From that blog is the graphic (Data mesh architecture from 30,000 foot view):

The data mesh is a exciting new approach to designing and developing data architectures. Unlike a centralized and monolithic architecture based on a data warehouse and/or a data lake, a data mesh is a highly decentralized data architecture.
Data mesh tries to solve three challenges with a centralized data lake/warehouse:
- Lack of ownership: who owns the data – the data source team or the infrastructure team?
- Lack of quality: the infrastructure team is responsible for quality but does not know the data well
- Organizational scaling: the central team becomes the bottleneck, such as with an enterprise data lake/warehouse
Its goal is to treat data as a product, with each source having its own data product manager/owner (who are part of a cross-functional team of data engineers) and being its own clearly-focused domain that has an autonomous offering, becoming the fundamental building blocks of a mesh, leading to a domain-driven distributed architecture. Note that for performance reasons, you could have a domain that aggregates data from multiple sources. Each domain should be discoverable, addressable, self-describing, secure (governed by global access control), trustworthy, and interoperable (governed by an open standard). Each domain will store its data in a data lake and in many cases will also have a copy of some of the data in a relational database (see Data Lakehouse defined for why you still want a relational database in most cases).
Another component in a data mesh is data infrastructure as a platform, which provides storage, pipeline, data catalog, and access control to the domains. The main idea is to avoid duplicating effort. This will allow each data product team to build its data products quickly. Note this data infrastructure platform should not become a data platform (it stays domain agnostic).
It’s a mindset shift where you go from:
- Centralized ownership to decentralized ownership
- Pipelines as first-class concern to domain data as first-class concern
- Data as a by-product to data as a product
- A siloed data engineering team to cross-functional domain-data teams
- A centralized data lake/warehouse to an ecosystem of data products
As for my opinion on Data Mesh (to clarify, this is my opinion and not that of Microsoft), it’s something that sounds great in theory but I’m really interested to see how companies are going to solve it technically. It would seem to require a full proprietary virtualization software and doing data virtualization has many issues (I already blogged about those at Data Virtualization vs Data Warehouse and Data Virtualization vs. Data Movement). There is also a large gap in open-source or commercial tooling to accelerate implementation of a data mesh (for example, implementation of a universal access model to time-based polyglot data). And you also have the challenge of Master Data Management (MDM) and Conformed dimensions. However, I think technology is on the way to solve this.
I am seeing some exciting attempts from Microsoft customers at building a data mesh. An excellent slide by John Mallinder from Microsoft (click to expand) for a customer building a data mesh, it which he uses the name “Harmonized Mesh”:
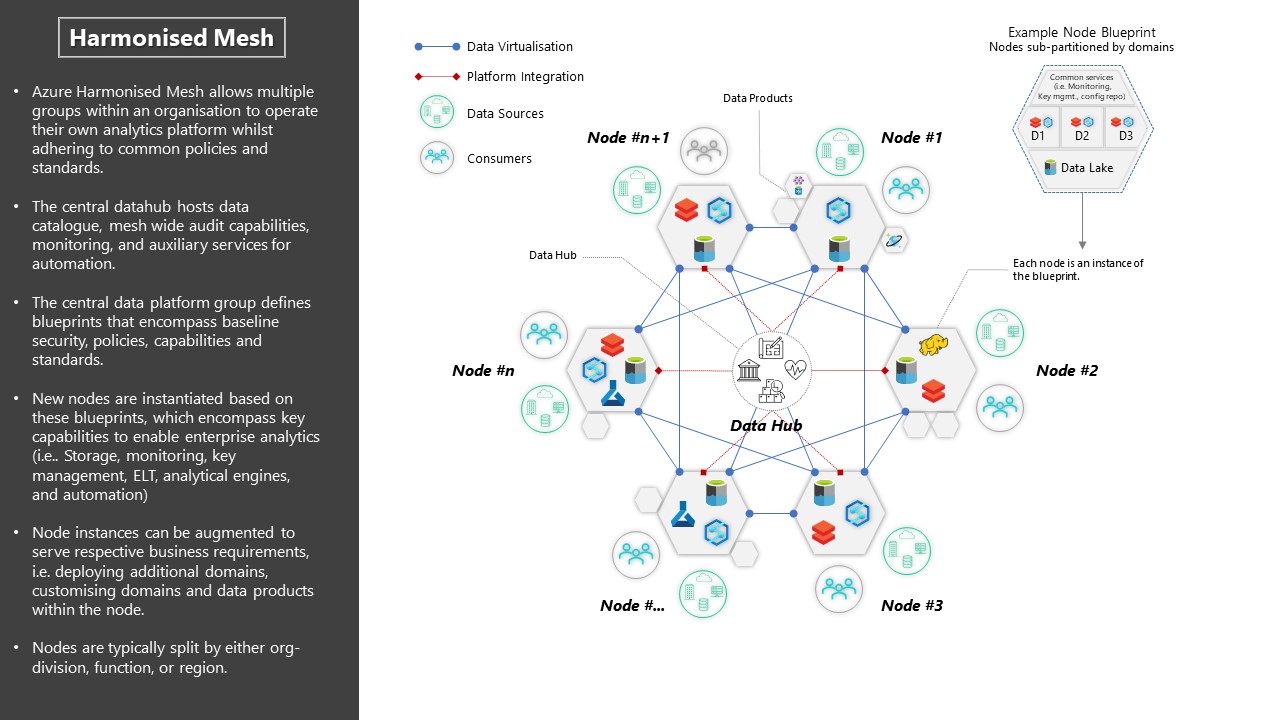
Creating this in the Azure world, Azure Purview would be your starting point for discovering data. If you need to do cross-domain queries, also called federated queries, you would use Synapse serverless with Azure virtual network peering if querying data from storage accounts (by linking the storage accounts in each Synapse workspace). If querying data from Synapse relational dedicated pools, that would currently require extra work, such as using Synapse Spark notebooks, Databricks, Power BI, or Azure Data Factory data flows to call multiple databases hosted in separate dedicated pools (but there are easier solutions on the way).
Keep in mind a data mesh only makes sense for companies with many large domains of data, and where there might be a lot of political infighting over who controls the data and/or data sovereignty is needed. So typically a data mesh is only for the largest companies as it can be difficult and time consuming to setup this environment. I am aware of a number of companies who have been building a data mesh – please comment below if you have a data mesh in production!
More info:
Data Mesh in Practice: How Europe’s Leading Online Platform for Fashion Goes Beyond the Data Lake
The Data Mesh – The New Kid On The Data Architecture Block
The Distributed Data Mesh as a Solution to Centralized Data Monoliths
Video Keynote – Data Mesh by Zhamak Dehghani
Data Mesh Paradigm Shift in Data Platform Architecture
The Data Mesh: Re-Thinking Data Integration
What is a Data Mesh — and How Not to Mesh it Up
Video Introduction to Data Mesh: A Paradigm Shift in Analytical Data Management (Part I)
Video How to Build a Foundation for Data Mesh: A Principled Approach (Part II)
Retrospective: My Experience Writing Data Management at Scale
Data Mesh: Design, Benefits, Hype, and Reality
Will the Data Mesh save organizations from the Data Mess?
Video How to Make a Data Mesh; Not Data Mess. MIT CDOIQ 2021
The post Data Mesh defined first appeared on James Serra's Blog.
