

Whenever the subject of compliance comes up, the first thing that comes to mind is auditing. What does an audit consist of? Let us look at what auditing means and then concentrate on one small part of auditing in this article.
Auditing in the real world is used to ascertain the validity of the information. It is also used to provide an assessment of our systems internal control. So what does audit mean for the IT department? Well, it assures the stakeholders that all the information that we provide is valid.
What should we audit?
In the perfect world, we would audit everything. But unfortunately we live in an imperfect world, and what we can audit is security, software, and data. In this article we will be discussing one of the new techniques available for data auditing.
Data auditing techniques.
Data auditing is the process of doing a profile check and assessing the quality of data, to find how accurate it is. This can be achieved by keeping track of all the data changes.
Let us look at some of the different auditing techniques that are available for SQL Server very briefly and then concentrate on one of the techniques available in SQL Server 2008.
Solutions available in all versions of SQL Server.
Some of the common options we have for auditing data involve developing an in-house solution or relying on third party tools. We will look at couple of in-house solutions. One of the solutions is to use triggers, though this has its pros and cons:
Pros:
- Everyone knows how to write triggers (or they think they do).
- Supported in all versions of SQL Server.
- Triggers can be very flexible.
- Possible to catch all data changes.
Cons:
- Possibility of introducing bugs.
- Performance issues.
- Possible table structure changes.
- Cause sleepless nights.
The second in house solution is by means of stored procedures. All data changes should be done using stored procedures. These stored procedures could write the changes to audit table. Let us go through the pros and cons for this method.
Pros:
- Everyone knows how to write stored procedures.
- You can create your logic on how you want to handle every change.
- Supported in all versions of SQL Server.
Cons:
- Cannot track changes made outside of the stored procedures.
- Maintenance headache.
- Possible data structure changes.
- Possibility of introducing bugs.
- Could introduce performance issues
There were a couple of tools provided by Microsoft, before SQL Server 2008 was released, designed to help with data auditing. They are C2 Audit and SQL-Trace, and although they will show who changed the data, it is a hassle to find out the actual data that was changed.
Auditing with SQL Server 2008.
When auditing became one of the requirement for compliance, Microsoft decided to add some new techniques to SQL Server 2008 to help with this.
The new techniques that were introduced are:
- Change Tracking (CT)
- Change Data Capture (CDC)
- SQL Audit
In this article, we will just be looking at change tracking.
Change Tracking.
What can change tracking provide for you? Change tracking will tell you which rows changed and what the current value is, however it cannot show you how the data was changed. For example if the data changed from 1 to 4 to 6 to 12, you will see only 12 and not the intermediate changes.
Change tracking is immediate. In fact, change tracking is part of the transaction and part of your execution plan. It is pretty simple to set it up- just a couple of T-SQL commands and you are done. To get the list of changes made, you will have to do a select from the table and do a cross apply with one of the functions available for change tracking. Let us give it a try.
For our test, we will create a test database.
IF EXISTS (SELECT * FROM sys.databases WHERE name = 'TestCT')
DROP DATABASE TestCT;
go
CREATE DATABASE TestCT;
Go
ALTER DATABASE TestCT SET ALLOW_SNAPSHOT_ISOLATION ON
GO
--Snapshot isolation is neede for change tracking !
USE TestCT;
go
CREATE TABLE dbo.SomeTable (
ID INT NOT NULL IDENTITY(1, 1) CONSTRAINT PK_SampleTable PRIMARY KEY
, SomeColumn VARCHAR(255) NOT NULL
)
GOThis will create a database with default values and tables. Now we have a test database to play with, the first thing to do is to set change tracking to true on the database level. This does not mean that all the objects in the database are going to be tracked. We have to enable it for each and every object you want to be tracked.
ALTER DATABASE TestCT
SET
CHANGE_TRACKING = ON
(
CHANGE_RETENTION = 2 DAYS,
AUTO_CLEANUP = ON
)
goThe CHANGE_RETENTION option lets you specify how many days of changes it should keep. AUTO_CLEANUP allows you to tell SQL SERVER to take care of purging old data. Since we want to see if it will start working by simply setting the database to track changes, we will insert a row into the SomeTable.
INSERT INTO dbo.SomeTable (SomeColumn)
VALUES ('John'), ('Brown')
goLet us see if we can see if the changes are being tracked now. To do that you can run this query.
SELECT t.*
, ct.*
FROM dbo.SomeTable t
CROSS APPLY CHANGETABLE(VERSION dbo.SomeTable, (ID), (t. ID)) AS ct
GoThis will throw the following error..

Now we will enable track changes for that table.
ALTER TABLE dbo.SomeTable ENABLE CHANGE_TRACKING go
Now the table is being tracked. If we run the same query we ran before to find the changes made, it should not throw any error.
SELECT t.*
, ct.*
FROM dbo.SomeTable t
CROSS APPLY CHANGETABLE(VERSION dbo.SomeTable, (ID), (t. ID)) AS ct; 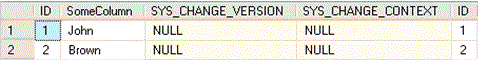
When you executed the query, the result set contains three additional columns. They are SYS_CHANGE_VERSION, SYS_CHANGE_CONTEXT and the PK column of the table once again. As you can see, the SYS columns are NULL. That is because we started tracking after the first two rows were inserted. Now let us try to insert a row and then update that row.
INSERT INTO dbo.SomeTable (SomeColumn)
VALUES ('New York')
go
UPDATE dbo.SomeTable SET
SomeColumn = 'New York City'
WHERE SomeColumn = 'New York'
GO
SELECT t.*
, ct.*
FROM dbo.SomeTable t
CROSS APPLY CHANGETABLE(VERSION dbo.SomeTable, ( ID), ( t.ID)) AS ct ; 
Now we have two changes after change tracking was enabled. If we run the same Select query once again, you will see that there is one more row in the result set. You might notice that the column SYS_CHANGE_VERSION has a value of two. This means that there were two changes after change tracking was enabled. One problem is that you do not know what the two changes were. You only know that the record with ID had a change. Let us continue with inserting another row.
INSERT INTO dbo.SomeTable (SomeColumn) SELECT (SELECT TOP 1 Name FROM sys.objects ORDER BY NEWID()) go
When we executed the select query previously, you saw three rows and the version number was two. From now on, you only want to see what records were changed. For that we will execute a slightly different query.
DECLARE @version BIGINT = 2;
SELECT t.*
, ct.*
FROM CHANGETABLE (CHANGES dbo.SomeTable, @version) AS ct
INNER JOIN dbo.SomeTable t ON t. ID = ct. ID
Go 
When you execute the above query, you might have noticed that the result set is slightly different. It has more information. The value in the SYS_CHANGE_OPERATION shows the mode of operation (Insert, Update or Delete).
Until now we have seen how change tracking works to find which record was modified. With change tracking we can also find out which of the columns was changed. In order to do this, when you enable change tracking for the table, you will have to specify that the columns need to be tracked as well. Let us see how to do that.
IF EXISTS (SELECT * FROM sys.tables WHERE name = 'NewTable')
DROP TABLE dbo.newTable;
go
CREATE TABLE dbo.NewTable (
ID INT NOT NULL IDENTITY(1, 1) CONSTRAINT PK_NewTable PRIMARY KEY
, BigColumn VARCHAR(255) NOT NULL
, AnotherBigColumn VARCHAR(255) NOT NULL
)
GO
--Now enable change tracking to this table.
ALTER TABLE dbo.NewTable
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON);
goBy specifying “WITH (TRACK_COLUMNS_UPDATED = ON)” it will start tracking which column was modified on a DML Operation. Let us insert some rows into this new table.
INSERT INTO dbo.NewTable (BigColumn, AnotherBigColumn) SELECT 'Some data', 'Some more data' go
To find out what is the current change tracking version, just execute the query
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CHANGE_TRACKING_CURRENT_VERSION
Now let us try to find out what columns were changed when this Insert was executed. For that we have to run a slightly different query than what we tried out previously.
DECLARE @version BIGINT;
-- determine previous version
select @version = CHANGE_TRACKING_CURRENT_VERSION() - 1
SELECT t.*
, ct.*
, CHANGE_TRACKING_IS_COLUMN_IN_MASK (COLUMNPROPERTY(OBJECT_ID('dbo.BigTable'), 'BigColumn', 'ColumnId'),CT.SYS_CHANGE_COLUMNS) AS BigColumn_CHANGED
, CHANGE_TRACKING_IS_COLUMN_IN_MASK (COLUMNPROPERTY(OBJECT_ID('dbo.BigTable'), 'AnotherBigColumn', 'ColumnId'),CT.SYS_CHANGE_COLUMNS) AS AnotherBigColumn_CHANGED
FROM CHANGETABLE (CHANGES dbo.NewTable, @version) AS ct
INNER JOIN dbo.NewTable t ON t. ID = ct. ID
goWhen you execute this, it will show what columns were changed. Since in this case the DML statement was an insert, it will show all columns as changed. If it had been an update on one column, it would have shown which column was changed.

So, we have now seen what change tracking is. In a nutshell:
- It will tell you which row changed.
- It will tell you which column was changed.
- It will integrate into the SQL Storage Engine.
- It is available in all edition of SQL Server 2008.
- It populates change table during the transaction.
Why would you use it?
Change Tracking is more suitable if you only need to know which rows have changed and don't need the historical information. It has less overhead because of the lack of data history. (btw: The historical part is what CDC focuses on) A couple of real world uses for CT are:
- Disconnected cache update
- ETL update
Effect of enabling Change Tracking.
For every new technology introduced, there will always be some draw back connected to it. Let us see what could be the issues that you might face.
- Execution Plan.
If you look at the execution plan, you will notice one additional node. That node is the insert into the change tracking table. That means there is more IO and resource usage.
- The data change path.
If the data in a table changed multiple times since the last time you checked, you will not see the intermediate data. You will only be able to see the final value.
- Space used.
When a table is added for change tracking, it creates a hidden column and a change tracking table. The hidden column will take around 8 bytes per row. Then there is the new change tracking table. It uses roughly 64 bytes per change.
- Who changed the data?
Unfortunately change tracking will not give you this information. You could say that change tracking does not help in auditing.
Conclusion
Change tracking is first step towards data auditing. When change tracking is enabled it gives us the ability to find out which data was changed and what the change were. Since it is part of the transaction, the changes are tracked immediatly.
You can find in-depth details of functions for CT here.
http://msdn.microsoft.com/en-us/library/cc280462.aspx
http://technet.microsoft.com/en-us/library/cc280358.aspx
Acknowledgements
I would like to thank two people who provided materials for this article unknowingly. The first person I would like to thank is Adam Machanic (@AdamMachanic). I went to his Pass Summit Session. His presentation style and flow made it easy for me to write. The second person is Claude Harvey. He gave a presentation on change tracking and change data capture for our user group. This helped refresh my memory and in a way I did not have to reinvent the wheel and do lots of research. I just needed to test my scripts.
I would also like to thank Johan Bijnens (@alzdba) and Jason Brimhall (@SQLrnnr) for helping to edit this article.
Come see me next time when we hear Dr Bob say:”CDC, What’s that for?” (From The Muppet show – Pigs in Space)
