

Introduction
Situations arise where logical data generation becomes a requirement. By 'Logical Data Generation', I mean generating additional data based on a logic being applied to already existing data. There are multiple ways of doing this, and in this article, I would like to demonstrate how it is conventionally done using cursors and how it can be done much more efficiently using CTE's. The concept is being brought out using a simple example.
The Problem
In order to explain the problem, let me first create two tables: dbo.abc and dbo.def. Once we get familiarity with the data, it will be easier to explain the problem. The table dbo.abc has four columns: SeqNo, Date_Field, Month_Count, and Payment. Let's create and populate it by executing the code below:
--If the table exists, drop it.
if exists (select * from sys.tables
where name = 'abc'
and Schema_Name(schema_id) = 'dbo'
and [type] = 'U')
drop table dbo.abc
go
--Create the source table, dbo.abc.
create table dbo.abc
(SeqNo smallint
,Date_Field smalldatetime
,Month_Count tinyint
,Payment decimal(10,2))
go
--Populate the source table, dbo.abc
insert into dbo.abc (SeqNo, Date_Field, Month_Count, Payment)
values (1, '20090101', 10, 100)
,(2, '20100101', 7, 200)
,(3, '20110101', 5, 300)
go
--If exists, drop the destination table dbo.def
if exists (select * from sys.tables
where name = 'def'
and Schema_NAME(schema_id) = 'dbo'
and [type] = 'U')
drop table dbo.def
go
--Create the destination table, dbo.def
create table dbo.def
(SeqNo smallint
,Date_Field smalldatetime
,Payment decimal(10,2))
goPlease execute the code below to view the data in the source table, dbo.abc:
select * from dbo.abc
You should see results like those shown below:
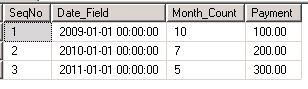
The source data being clear, now let's define the problem. Each row in the table, dbo.abc has to be duplicated as many times as the value of Month_Count in that row. Currently the Date_Field has a value that represents the first day of a year. While duplicating the data, we need to ensure that each new row has its Date_Field value incremented by one month. We need to stop the duplication as soon as we reach the month value in the column Month_Count for that row.
The values for the columns SeqNo and Payment should remain as they are in the original row. This process needs to be performed for all rows in the source table, dbo.abc. Finally we need to display all the original and duplicated rows. So effectively, we need to populate the columns SeqNo, Date_Field and Payment into the destination table, dbo.def with the data generated as described above. Let me expalin th problem for the row with SeqNo value of 1 in the source table, dbo.abc. For this row, the program should bring the destination table dbo.def to the following state:
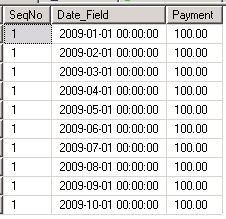
So effectively, we want data from January to October for SEqNo 1 as the corresponding value of the column, dbo.abc.Month_Count is 10.
Conventional solution
Now let us write a conventional SQL Server 2000 type program. Since I have to loop through the data in each row, I am ending up using a CURSOR and two WHILE loops. The T-SQL program is given below:
declare @l_SeqNo int
,@l_date_field datetime
,@l_Month_Count smallint
,@l_Payment decimal(10, 2)
,@l_counter smallint
select @l_counter = 0
set nocount on;
declare i_Cursor insensitive cursor
for
select SeqNo, Date_Field, Month_Count, Payment from dbo.abc
open i_Cursor
fetch next from i_Cursor into
@l_SeqNo
,@l_date_field
,@l_Month_Count
,@l_Payment
while @@fetch_status = 0
begin
select @l_counter = 0
while (@l_counter < @l_Month_Count)
begin
insert into dbo.def (SeqNo, Date_Field, Payment)
select @l_SeqNo, dateadd(mm, @l_counter, @l_date_field), @l_Payment
select @l_counter = @l_counter + 1
end
fetch next from i_Cursor into
@l_SeqNo
,@l_date_field
,@l_Month_Count
,@l_Payment
end
close i_Cursor
deallocate i_Cursor
set nocount off;
go
T-SQL code like the code above is very common. I select all the fields from the source table, dbo.abc, into a CURSOR. In the outer WHILE loop, I select one row of data from the source table, dbo.abc. Then within each iteration of the inner WHILE loop, I add an extra month to the original Date_Field value based on a counter defined by the variable @l_counter. In the first iteration of the inner WHILE loop, I insert the original row from dbo.abc into the destination table, dbo.def. This continues incrementing until the value of the variable @l_counter reaches the value of Month_Count. Then the control goes to the outer WHILE loop and the next row is fetched from the table dbo.abc. Then again the inner WHILE loop gets operational by re-setting the value of the variable @l_Counter to 0, inserting the row as is and then incrementing the value of @l_counter by 1 through each iteration of the inner WHILE loop and inserting the data into table dbo.def with the incremented value of month for the Date_Field column in the table dbo.def.
For each iteration of the outer WHILE loop, I fetch the next row from the source table, dbo.abc. During each successive iteration through the inner WHILE loop, a row of data with the Date_Filed incremenetd by a month is getting inserted into the destination table, dbo.def. This goes on till all rows in the table dbo.abc have been processed by the cursor. Then I close and deallocate the cursor.
After executing the above program, let us check the destination table, dbo.def by executing the following query:
select * from dbo.def
We see these results:
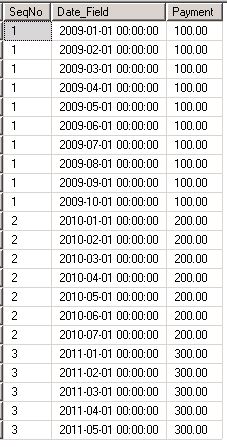
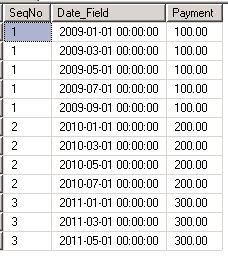
It may be noted in the result set above that the row with SeqNo 1 has been duplicated 10 times, 10 being the value of the Month_Count field in source table dbo.abc. Also Date_Field is successively incremented by a month until it reaches the number of months in the field dbo.abc.Month_Count. Similarly, the row with SeqNo 2 has been duplicated 7 times, 7 being the value of the Month_Count field in table dbo.abc. Finally the row with SeqNo 3 in the table dbo.abc has been duplicated 5 times, 5 being the value of the Month_Count field in table dbo.abc. We have kept the values of SeqNo and Payment columns intact through this duplication exercise while incremenging the value of Date_Filed column by a month in each successive record for a given SeqNo value.
The problem has been solved. Now let us solve the same problem in a different way using Recursive CTE in SQL Server 2005/2008/2012 style of coding.
Contemporary Solution
A Recursive Common Table Expression simplifies and speeds up the solution with less code and less scans of the source table, dbo.abc. First let us clean up the destination table by executing the following TSQL code:
truncate table dbo.def
The destination table, dbo.def, is now empty. Let us look at the alternative solution code below using recursive CTE:
;with CTE_Base (SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency) as (select SeqNo, Date_Field, Month_Count, Payment, Date_Field, dateadd(mm, Month_Count-1, Date_Field), 1 from dbo.abc union all select SeqNo, dateadd(mm, Frequency, Date_Field), Month_Count, Payment, Begin_Date, End_Date, Frequency from CTE_Base where dateadd(mm, Frequency, Date_Field) between Begin_Date and End_Date) insert into dbo.def (SeqNo, Date_Field, Payment) select SeqNo, Date_Field, Payment from CTE_Base where Date_Field between Begin_Date and End_Date order by SeqNo, Date_Field go
In the first SELECT statement inside the CTE called CTE_Base, I select all the fields from the source table, dbo.abc, as well as calculating the first (Begin_Date) and last dates (End_Date) inside which the Date_Field value should fall for a given SeqNo value.
The SELECT statement after the UNION ALL clause is used for recursively reading the values that are already part of CTE_Base and incrementing the value of Date_Filed by a month in each recursion. The WHERE condition in this SELECT statement ensures that for a given SeqNo in the source table dbo.abc, recursion stops as soon as all calculated Date_Field values have been retrieved so that they fall between the Begin_Date and End_Date.
A Frequency value of 1 in the code means that Date_Field needs to be incremented by month.
Let us execute the code above and then see the contents of the destination table, dbo.def:
select * from dbo.def
Here is the result set:
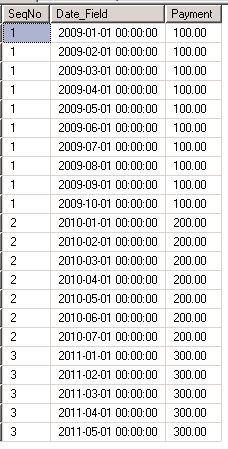
In the result set above, the row with SeqNo 1 has been duplicated 10 times, 10 being the value of the Month_Count field in source table dbo.abc. Also the Date_Field is successively getting incremented by a month till the number of months in the field dbo.abc.Month_Count. Similarly, the row with SeqNo 2 has been duplicated 7 times, 7 being the value of the Month_Count field in table dbo.abc. Finally the row with SeqNo 3 in the table dbo.abc has been duplicated 5 times, 5 being the value of the Month_Count field in table dbo.abc. We have kept the values of SeqNo and Payment columns intact throughout this duplication exercise while incremenging the value of Date_Filed column by a month in each successive inserted record for a given SeqNo value.
The results in both the methods match. The recursive CTE has eliminated the usage of Cursor and nested WHILE loops in the original conventional code.
Now the question is "Why is the recursive CTE based approach better than the CUROSR based approach?" It is better in the following ways:
- The code for recursive CTE is much shorter than for the CURSOR.
- The recursive CTE scans the source table dbo.abc exactly once no matter how many rows it contains where as the CURSOR based code goes through this table thrice i.e. as many times as the number of records in the table dbo.abc.
- The recursive CTE based code inserts 10 + 7 + 5 = 22 rows into the table dbo.def with one INSERT statement. The CURSOR based approach inserts one row at a time during each of its 22 iterations.
- If "Show Actual Execution Plan" is set prior to executing the code and then both the queries (the CURSOR based one and the recursive CTE based one) are executed, you will note that the query cost of the conventional CURSOR based approach to this problem's solution is around 91% where as it is around 9% with the recursive CTE based solution. That is almost a ten fold savings in resource utilization with the recursive CTE based solution.
- It may also be noted that the recursive CTE in this case does not use even a single variable unlike the CURSOR based methodology which used four variables.
- If we have a million rows in the source table dbo.abc, the outer while loop would iterate a million times in the CURSOR based approach. But with recursive CTE code, the table dbo.abc would still be referenced only once. So the benefits of this code would get realized as the number of rows to be processed increases.
- Again, if we have a million rows in the source table dbo.abc with each row having a value of 10 for the column, Month_Count then there would be a total of ten million individual one-row INSERTs into the destination table, dbo.def. But in the same scenario with recursive CTE, there would still be exactly one INSERT into the table dbo.def although this would insert 10 million rows in a set-based fashion. In an OLTP system, this means that the number of times locks would be held on the destination table dbo.def would be way less than in the CURSOR-based approach. So the recursive CTE based approach can reduce blocking compared to the CURSOR-based approach in an OLTP scenario.
Important points
A few important points related to table hints and usage of semicolon need to be considered while using CTE's and recursive CTE's.
- In conventional code as well as in CTE's that are non-recursive, table hints can be used inside the body of the CTE. For example, usage of dbo.abc with (nolock) inside the body of the CTE or CTE_Base with (nolock) outside the body of the CTE is valid. But in the case of recursive CTE's, table hints can not be used on the CTE itself inside the body of the recursive CTE. For example, usage of dbo.abc with (nolock) inside the body of the CTE is valid or CTE_Base with (nolock) outside the body of the CTE is valid. But usage of CTE_Base with (nolock) inside the body of the recursive CTE is invalid.
- Being a CTE, its code must be preceded by a semicolon. However when a CTE or a recursive CTE is used within the body of an Inline table-valued function, the usage of semicolon preceding the CTE is invalid and produces a syntax error. This paradox needs to be considered when writing TSQL code using CTE's.
Usage as a function
The CTE code above can be incorporated into a user defined inline table-valued function. Frequency can be passed as an input parameter to this function to get the same results that we onbtained earlier. The code of the UDF is following:
create function dbo.UDF_Inflate_Data (@i_Frequency tinyint) RETURNS TABLE as RETURN (with CTE_Base (SeqNo, Date_Field, Month_Count, Payment, Begin_Date, End_Date, Frequency) as (select SeqNo, Date_Field, Month_Count, Payment, Date_Field, dateadd(mm, Month_Count-1, Date_Field), @i_Frequency from dbo.abc union all select SeqNo, dateadd(mm, Frequency, Date_Field), Month_Count, Payment, Begin_Date, End_Date, Frequency from CTE_Base where dateadd(mm, Frequency, Date_Field) between Begin_Date and End_Date) select top 100 percent SeqNo, Date_Field, Payment from CTE_Base where Date_Field between Begin_Date and End_Date order by SeqNo, Date_Field ) go
Please note that I have used TOP 100 PERCENT in the SELECT statement in this function because I want to retain the ORDER BY clause, which is otherwise not allowed in InLine table-values functions.
Let us execute this function with an input parameter 1 for Frequency. In other words, the function needs to give results by incrementing the Date_Field by one month at a time.
select * from dbo.UDF_Inflate_Data (1) order by SeqNo
Here are the results, which are same as above:
The interesting thing about this function is that we can vary the Frequency to say 2 and get the results spaced two months apart for a given SeqNo value in the table dbo.abc. Let us execute the statement below:
select * from dbo.UDF_Inflate_Data (2) order by SeqNo
Here is the result set:
You may note that the values in Date_Field for subsequent rows for each SeqNo are two months apart in the above result set.
A function like this can be used for generating additional data based on logic applied to existing data. One use of a process of this kind is to inflate data in a database for stress testing. There could be other uses for such a function. I have just used this example to bring out one of its uses.
Conclusion
Recurive CTE's offer a simple, effective and better performing alternative to loops (CURSOR / WHILE, etc) in certain situations.
The problem I have used in this article is just to solve such a situation where new data is to be generated based on applying certain logic to existing data. In practice, there are and would be many more such scenarios where recursive CTE's can be put to good use for efficieny in execution and brevity of code.