

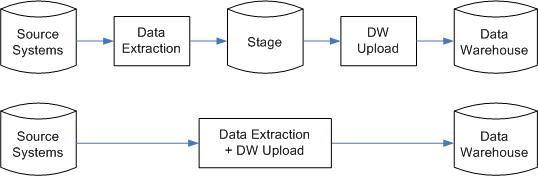
When loading data from source system into data warehouse, we can "dump"
the data as quickly as we can into stage as is, for later processing; or we
can transform the data on the fly and populate the data warehouse directly from
the source system. Both approaches have their own advantages and disadvantages, so let us look
at them.
First of all, if we transform and process the data on the fly, the data extraction
process would take longer. Especially if we are doing upsert, e.g. update or
insert depending whether the record already exists or not in the data warehouse.
The time window on the source system may not allow us the leisure that we desire.
For example, the source system could be doing a nightly batch from 8 pm to midnight,
followed by backup process from midnight to 3 am, and the time slot allocated
for the data warehouse to extract data from this source system is 4-5 am in
the morning. Hence we want to connect, extract as quickly as possible then disconnect.
In some data warehouse implementations, we extract data from the source systems
at certain intervals continuously throughout the day, for example: every hour.
An example of this implementation is a order processing warehouse system for
a multinational company to enable corporate customers to analyse their orders
using a web application. The source systems are 8 different ERP systems throughout
the globe and we want to minimise the burden to the source systems. Therefore
the same principles apply: we want to connect, extract as quickly as possible,
then disconnect from the source systems.
So that is the first reason why we want to stage the data: time. The second
reason, which could be more important, is the robustness, or reliability of
the data warehouse system. If the download process failed, we would like to
be able to recover and start again. Consider these 2 scenarios. Scenario 1,
using SSIS we download from a DB2 on a mainframe, transform the data (key maintenance,
etc) and upsert into a star-schema data warehouse. Scenario 2, an RPG program
extracts the DB2 data into flat files, then we use SSIS to upload the data into
our data warehouse. Which of these 2 scenarios are more reliable, e.g. if in
the middle of the process a) we lost network connection to the mainframe, or
b) there was a power cut. Which scenario has higher chance of recovering and
continue the process again when the network or electricity is up and running
again?
The source data is web of inter-related files or tables. For example, we may
have order file, product file, customer file, etc. In scenario 1, we may be
download+upsert orders when network connection to the mainframe breaks. At this
time, there could be orphanage in the data warehouse, e.g. order records without
corresponding customer or product records. In scenario 2, we may be downloading
orders from source system into flat files when network connection to the mainframe
breaks. And the data integrity of our data warehouse is intact because those
new orders are not in the data warehouse yet. Suppose in scenario 2 the power
cut happens when all new order, customer and product records have been extracted
into stage. When we upload those 3 entity into our data warehouse, the power
cut happens. If we wrap the upsert process in a transaction, no problem! The
data integrity of our data warehouse is still intact. Because it is a transaction,
it's either all or nothing.
The third reason of staging the data is to decouple the source data extraction
process and the data warehouse update process. For example, the data extraction
process could be happening every hour and it takes 2-3 minutes every time. Whilst
the data warehouse update (including the cube update) could be taking place
4 times a day: at 7 am, at 12 noon, at 4 pm and at 8 pm, taking 1 hour each.
(The data warehouse downtime is not 1 hour, but minimised to 1 minute because
we update is a copy of the warehouse DB, then when it's finished we rename
the database). As we can see in this example, the advantage of decoupling
the 2 processes is that they can be set to execute at different intervals.
The source systems data extraction process itself could be happening at different
intervals. Some data entities such as orders could be happening every hour,
some entities such as delivery vehicles and currency rates could be happening
only once a day and some entities such as performance targets could be happening
only once a month. It all depends on the nature of the data: some data changes
every hour of the day including week ends but some data is only updated once
a month! If we don't stage the data, how could we cope with this nature, different
data coming at different intervals? Yes there is a work around, but it would
be easier if we stage the data.
The fourth reason - easier development. If you would like to outsource the
development of your data warehouse (to India for example), you could either:
a) allow the outsource company to connect to your source system (and it could
your main ERP system we are talking about here), or b) give them DVDs (or LTO
tapes) containing stage files (or database). In scenario a, you will want to
give them access to your development ERP system. Believe me, you wouldn't
want to give them access to your production system. There are a long list of
reasons for this, among other things are: 1) risk of main ERP system downtime
because of 'slightly incorrect query' being put by them, resulting in Cartesian
explosion, 2) at 11:05 am 30 ERP users could be phoning helpdesk because of
'slow response time' - you found out later that they were testing an SSIS package
which uploads last 3 months orders into data warehouse - this package finishes
running at 11:17 and those users say that the system is 'quick and responsive'
again.
In scenario a, your network colleague may be saying "err - it is against
our company security policy to allow a 3rd party to VPN into our network",
or similar. Or even worse: "Allow TCP port 3389 in the firewall? Are you
joking? Haven't you heard about denial of service because of remote desktop protocol?
I'm sorry this request is absolutely out of question (in the name of security)".
All I'm trying to say here is: if you don't stage your data, you are in scenario
a. You need to allow the outsource company to connect to your source system,
with all the issues. Usually you will end up with scenario c: bring the outsource
company into your building. In other words, find a local data warehousing company.
If, on the other hand you stage your data, then you are in scenario b (the DVD
or LTO tapes scenario), have them to sign confidentiality agreement, and ...
your data warehouse project is up and running!
So far it's all about advantages of having a stage. What are the advantages
of not having a stage? Well, one of them is simplicity. Within a single SSIS
package you move the data from source straight to warehouse, with the key maintenance
and all. Secondly, the overall processing time is shorter.
Just a very brief note on what and where a stage is: the stage could be a file
system, or it could be a database. It could be on the source system RDBMS database
format, or it could be on the data warehouse RDBMS database format. For example,
if your source system is running on Informix on Unix platform and your data
warehouse is on Microsoft SQL Server, you have 4 choices about where to create
the stage, each with their own advantages: 1) On Informix as a database, 2)
as flat file system on Unix, 3) on Windows server as text files, or 4) as a
database on SQL Server. Generally speaking, the closer the stage to the source,
the shorter the extraction time. For a full discussion on this topic (advantages
and disadvantages of each of the 4 options), I will have to write a separate
article. It's not the kind of thing you can explain in a paragraph, unfortunately.
There is a 5th choice for the above scenario (it's uncommon, and has its own
disadvantages, but it is possible): the stage could be in memory (RAM).
Vincent Rainardi
6th March 2006
