

Many companies have very strong requirements for auditing data changes. Companies that use
audited data often display the audit data via a front end or generate business reports from it. In my
article about audit trails I described one of the solutions for an audit trail and provided the example of a code generator for my solution. I recommend that you read the article in the link before continuing to read. Let me remind you of some necessary rules for my audit solution.
Each table should have a unique row identifier based on one column row_id. Column row_id will be an identity column in tables where there is no identity column or if table already has an identity column row_id will be a computed column with value equal the identity column value. It may sound strange but, the processes require an easy and unique way to identify the row if primary key consists of few columns.
The audit table keeps the changed row, not the old row. This was done to increase performance of the reports and eliminate the necessity of audit and audited table joint to get the old and current values. Each history table has modif_id field to show all the rows that are changed in one modification.
So, why did I return back to the same topic? There are two additional requirements or tasks that I would like to cover in this article. First, the amount of standard columns that support auditing is growing and sometimes, based on application requirements, is different. Before, in addition to the data changes, this was the rule related to many companies, only 4 pieces of information were required
to satisfy an audit: user, date, machine, and change type (insert, update, delete).
In the new world of WEB applications, shared modules, shared screens, advanced security, and so on, additional auditing data is very important. For example, IP address, URL, application or module or screen code, user type and etc. As you can see, some type of information may be considered by some companies as not exactly an audit, but some companies require this info to be as part of an audit
solution.
It is not practical to store this information in columns in each table as it was described in my previous article because number of standard columns for audit can vary from application to application. The new idea for implementation is to use standard XML column to store complete information in XML format.
<row>
<user>12</user>
<module>mymodule</module>
<ip>123.12.12.12</ip>
<url>myurl.com</url>
</row>
This XML column will hold all the necessary data. It is very important to notice that for one transaction all the pieces of information to support the audit are the same. This means that XML column that has to be in each data table can be only in one centralized modification table and not in each audit table. If for whatever reason in your case this information can be different for each modified row in transaction, then you need keep XML column in each audit table. However, this is an unlikely case for most applications.
When I was implementing this solution I decided to keep a few columns that are most likely will be used for future needs outside of XML. In my case it was date, modification id, and modification type.
My second task was the
simple question – which product is changed and who did the changes? This
question may be posted by destination databases when the current one is the
source and destination database has to keep only active records. For example,
the database is keeping client’s product data or demographic data or some
other type of data. Data is changing daily. To propagate data with differential
ETL process I don’t need to know what pieces of information are changed. All I
need to know is which products are changed. Let’s say the database keeps
1,000,000 products and about 1% of them are changing daily. Also assume that
data about the product is stored in 50-60 tables.
As you can see, the second task is not required to have full data audit but audit solution can help easily answer second question as well as provide an audit. In reality, the solution can be built in a way that will allow you to have just a full audit, or an answer to the question which product was changed, or both, or none.
Now let’s see the implementation of this solution based on one table product.
Create table product (
product_id int primary key
, product_name varchar(50)
, rowstatus char(1)
, row_id int identity(1,1)
, audit_xml XML
, modif_id uniqueidentifier
)
Create table product_property (
property_id int identity(1,1) primary key
, property_desc varchar(50)
, value varchar(10)
, rowstatus char(1)
, row_id as property_id
, audit_xml XML
, modif_id uniqueidentifier
)
The general table Modification will hold the main record of modification. This record holds all the same pieces of information for one transaction.
CREATE TABLE [Modification]( [Modification_ID] [int] IDENTITY(1,1) NOT NULL, [Modif_ID] [uniqueidentifier] NOT NULL, [Database_NM] [varchar](30) NOT NULL, [Table_NM] [varchar](100) NOT NULL, [Action_CD] [char](1) NOT NULL, [TotNumModifRows] [int] NOT NULL, [CreateDate] [datetime] NOT NULL, [CreateSource] [varchar](128) NOT NULL, [UserMachine] [varchar](128) NULL, [UserName] [varchar](128) NULL, [Audit_XML] [xml] NOT NULL)
The next table will capture only information about rows that were changed in transaction. As you noticed, each base table has field rowstatus. This field will have 3 values: A – active, S – soft delete, H – hard delete.
This means that you have flexibility to delete records logically or physically. As you will see later, physical deletion will be established by a trigger or prohibited by the trigger. This allows the DBA to establish the process of database cleanup
and for example, run it once a month (or year) while keeping physically deleted
records in database. E.g. in my case, the application will never delete rows by
delete statement but simply update rows with rowstatus = ‘D’. Table RowAudit
will record every changed row in every table and the status changes.
CREATE TABLE [dbo].[RowAudit]( [RowAudit_ID] [int] IDENTITY(1,1) NOT NULL, [Modif_ID] [uniqueidentifier] NOT NULL, [ROW_ID] [int] NOT NULL, [Database_NM] [varchar](30) NOT NULL, [Table_NM] [varchar](100) NOT NULL, [ActionCD] [char](1) NOT NULL, [OLD_Status] [char] (1) NOT NULL, [New_Status] [char] (1) NOT NULL, [CreateDate] [datetime] NOT NULL)
I do expect a question, how to define what is the real row changes between one and another point in time based on the table RowAudit? Let say for example that the row was updated, then soft deleted, then updated back to active, then any other changes. There are multiple scenarious of changes. In reality, at the time the process which defines the state of a row only requires the start and end point of changes. The chart below explains all the different cases.
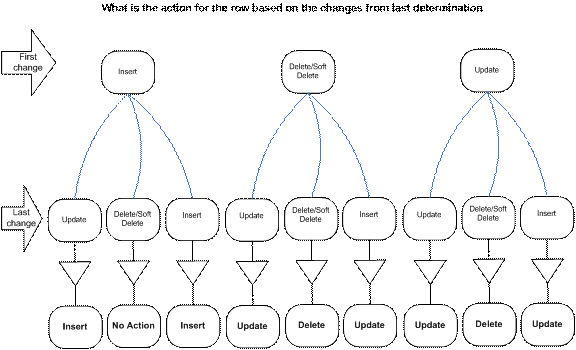
For example, if a row was inserted, then modified multiple times and at the end was
deleted, then there is no action for this row. However, if the last action shows
that row is deleted – then the row has to be deleted from destination databases regardless of all other changes.
Where an audit table can be created?Audit tables can be created in the same database or in a different one from the adited table database. It is make sense to create a separate database for audit tables because the size of the audit data can be significant. Separation between data in different databases will allow you to simplify maintenance and
data offload processes or cleanup in future. In my case I decided to create one database per SQL Server with schemas named as the audited database. For example, if audited database name is "products" then audit database will have all audit tables in the schema "products".
Create table products.a_product ( audit_id int identity(1,1) primary key, product_id int, product_name varchar(50), rowstatus char(1), row_id int, modif_id uniqueidentifier, createdate datetime, actioncd char(1)) Create table products.a_product_property ( audit_id int identity(1,1) primary key, property_id int , property_desc varchar(50), value varchar(10), rowstatus char(1), row_id as property_id, modif_id uniqueidentifier, , createdate datetime, actioncd char(1))
One additional consideration
can be adapted to the solution by the creation of control table which will keep
the flags and allow the trigger to make a decision of what would be recorded or
not to be recorded. The flag definition from the control table can be
implemented in the trigger as the very first statement. Also, the trigger will
decide the action based on the flag configuration. The
control table may look this:
CREATE TABLE [dbo].[ControlTable]( [ControlTable_ID] [int] identity(1,1) NOT NULL primary key , [Table_NM] [varchar](100) NOT NULL, [DataAudit_FLG] [char](1) NOT NULL, [RowAudit_FLG] [char](1) NOT NULL, [HardDelete_FLG] [char](1) NOT NULL )
When the trigger records the changes that are done for rows in table RowAudit, it is necessary to create a mechanism that will produce the answer to the question, "Which product is changed between last ETL and now?" This mechanism can be part of an ETL that is modifying data in destination database. The ETL process can be designed very simple way – the first step is deleting products completely from the destination database. The next step is to reinsert the product from the source database to the destination database.
There is an example of the trigger for a one table trigger for the ideas described in this article in the Resources section. Download OneTableTrigger.txt
This trigger has to be the last trigger for the table.
EXEC sp_settriggerorder @triggername=N'[dbo].[TR_UID_Product]', @order=N'Last', @stmttype=N'DELETE' EXEC sp_settriggerorder @triggername=N'[dbo].[TR_UID_Product]', @order=N'Last', @stmttype=N'INSERT' EXEC sp_settriggerorder @triggername=N'[dbo].[TR_UID_Product]', @order=N'Last', @stmttype=N'UPDATE'
This trigger is created for one table. You can easily adapt the code from my previous article (see link above) to create an audit generator which will generate audit tables and audit triggers for a complete database.
Conclusion
This article shows an
example of audit extension solutions with usage of XML data field if company
requires extend number of standard data elements that has to be recorded with
every record while table is in full audit. It shows how you can easily transform
audit into a mechanism that answers simple questions without running a full
scale audit. Different types of architecture for ETL tasks require different
solutions. This article shows only one of the many possible solutionss.

