

Based on my experience as an ETL developer, DefaultBufferMaxRows and DefaultBufferSize are perhaps the most underused Data Flow Task properties for optimizing data extractions. SSIS uses a buffer based architecture and has memory structures called buffers where the data extracted from the source is stored for performing data transformations before the data is sent to the necessary targets. The DefaultBufferMaxRows property suggests how many rows can be stored in these buffers while the DefaultBufferSize (in bytes) suggests the size of the buffer for temporarily holding the rows. These properties have default values assigned to them as shown below (Fig 1).
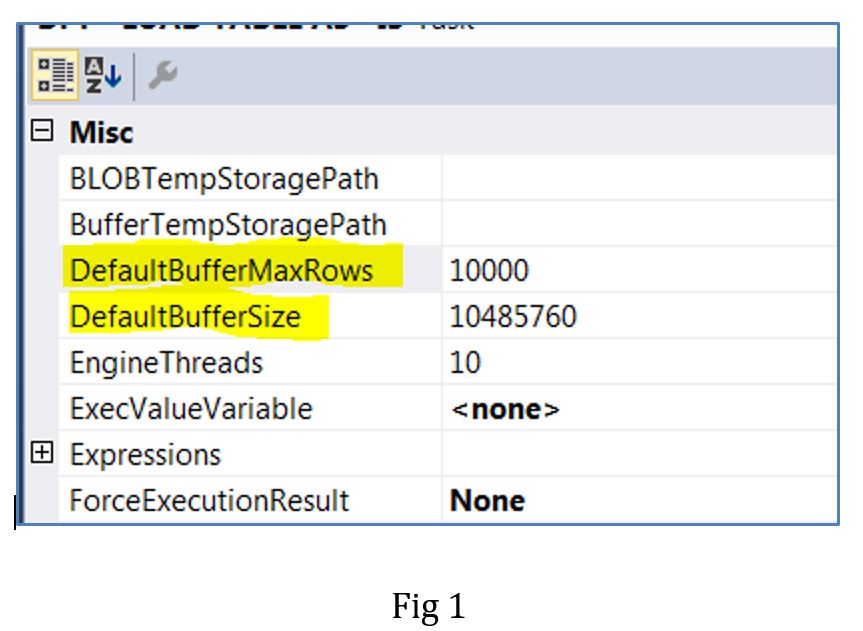
For smaller data volumes, there is no need to change these properties and the default values usually suffice. However for large data volumes the default values would not necessarily give you the best performance and hence a certain level of manipulation is required for improving the data flow performance. In order to manipulate these properties, we need to know the size per row to estimate how many rows the buffer can hold for a specific value of DefaultBufferSize or to estimate what is the upper limit for buffer size to accommodate a specific number of buffers rows.
For example, if the buffer size was limited to default value of 10MB and the size per row was calculated to be 100 bytes, the DefaultBufferMaxRows can be increased to accommodate 104K+ rows (ie 10485760 bytes/100 rows) or else the SSIS engine would continue to populate the data in batches of 10000 rows. Or if you wanted to limit the DefaultBufferMaxRows to 10000 and the size per row was 1700 bytes, then DefaultBufferSize would need to be increased to around 17 MB to accommodate the DefaultBufferMaxRows default value of 10000 rows or else the data would be populated in batches of around 6000 rows.
The DefaultBufferSize property values can range from 1 MB to 100MB. Higher buffer size translates to more rows in the buffers. However, this would also mean that commit frequency would be much lower as more numbers of rows would need to be populated in buffers before they are flushed out to the destination. Hence for optimal performance we need to maintain a balance between increasing the size of buffers to accommodate more rows and keeping a healthy commit rate. In this article, I will demonstrate that the data flow performance is improved by varying the DefaultBufferMaxRows and DefaultBufferSize properties, however after a certain threshold value for both properties, there is no significant improvement in performance.
In the test, I created a simple data flow task which extracts data from a source table to a target table. The source table has around 77 million rows. The row size based on the table properties, was calculated to be 40 bytes/row. This would imply that for a default value of DefaultBufferSize property, the buffer has a capacity to hold around 250K rows. I thus initially increased the DefaultBufferMaxRows value to 100000 by keeping the DefaultBufferSize constant, executed the package and noted down the time it took for the package to run successfully. Package was then executed every time when either the DefaultBufferSize or DefaultBufferMaxRows property was changed so that buffer could hold more rows.
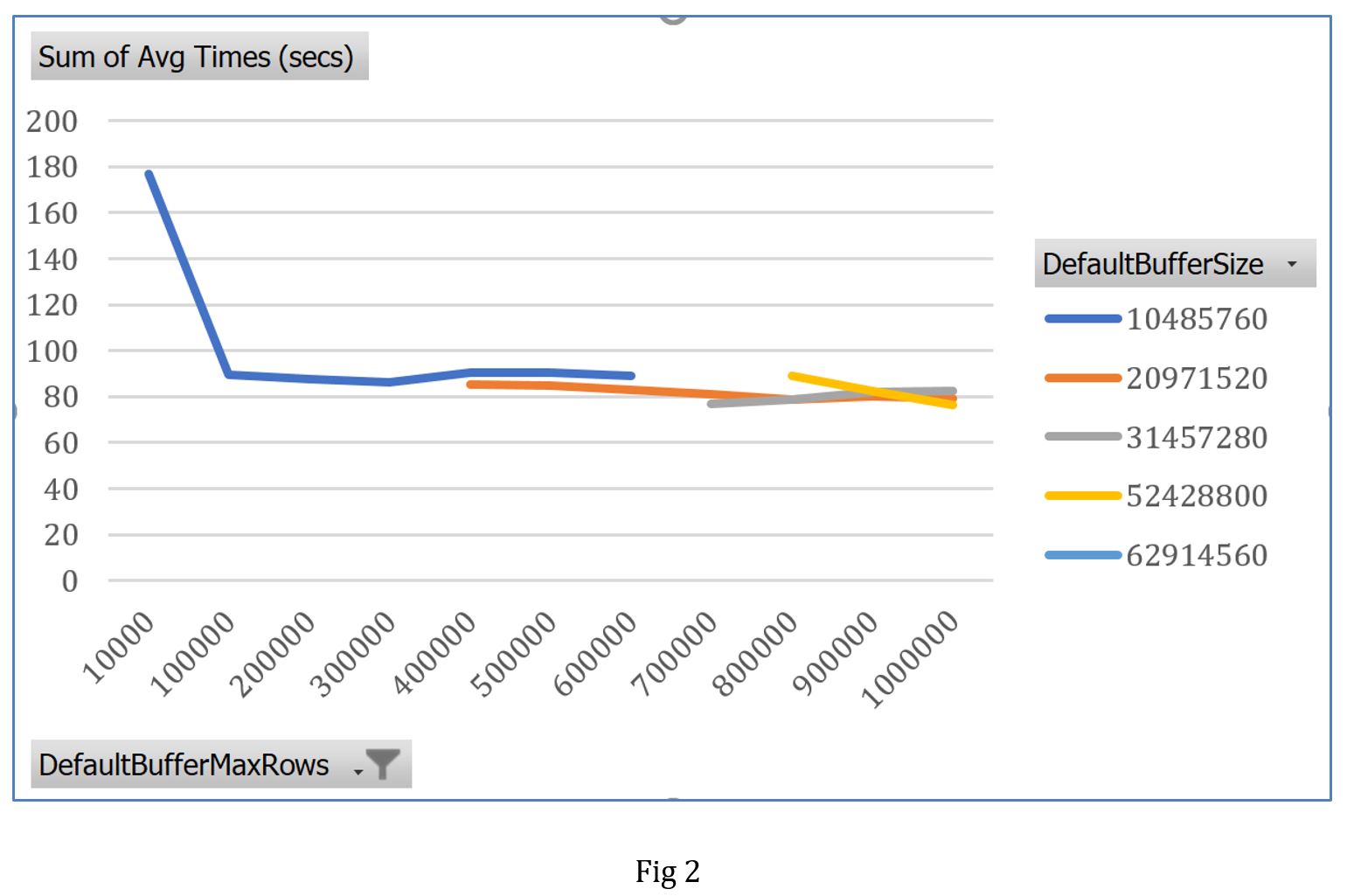
From the plot (Fig 2), you can clearly see that there was a sharp drop in processing time by changing the DefaultBufferMaxRows property from the default of 10,000 rows to 100,000 rows. But as I increased the value for DefaultBufferMaxRows there was no significant change in processing time. This is because the buffer could not hold the increasing number of rows and package continued to process the data at the maximum upper limit. By increasing the buffer size to twice the default value, there was slight improvement in performance as the buffer could hold more rows. However, as we kept on altering the DefaultBufferSize or DefaultBufferMaxRows values to hold more rows, there was minimum to no performance improvement as more time was required to fill the buffers.
Conclusion
It is thus recommended that we look at altering the DefaultBufferSize or DefaultBufferMaxRows properties so that we can achieve performance gains by allowing the package to process more data in the buffers. However, after a certain value of the two properties a saturation point is reached after which there is little to no performance improvement. Depending on the complexity of the package and environment constraints, the saturation point might be reached much sooner.
From SQL Server 2016, a new Data Flow Task property has been introduced called AutoAdjustBufferSize2, which when set to True, will adjust the buffer size automatically to accommodate the number of rows specified by the user. This allows us to change DefaultBufferMaxRows property without worrying about DefaultBufferSize.
References
1. http://www.sql-server-performance.com/2009/ssis-an-inside-view-part-3/?_sm_au_=iVVlsDDHW1fR7llM


