

Continuous Integration testing relies on a structured workflow that moves code from development to source control, which is “pulled,” built, tested, and ultimately promoted to production. Unfortunately, achieving a reliable CI process with relational databases is not as simple. Database upgrade and rollback scripts are readily managed with source control, but the size of production databases limit their use in Continuous Integration. The lack of a secure, writable, easily consumable production database results in use of outdated or smaller test databases for Continuous Integration. Databases that differ significantly from production result in increased release risk.
SQL Server containers and database cloning, however, create the opportunity to work securely with clones of production databases in a practical manner. Use of database clones with a new approach to Git (or other source control systems), supports the use of production databases throughout a CI process.
Database clones with Git
Database clones are writeable copies of the source database built with Windows Virtual Hard Drives (VHDs) or enterprise storage arrays that deliver databases in seconds with minimal storage consumption. Windows VHDs support practical delivery of environments up to 3 TB, and storage arrays support environments up to 30 TB or more. Conventional CI pipelines build a new image following each source repo update. The “build for each change” isn’t needed or practical with databases as changes to the repo are usually limited to upgrade and rollback scripts.
Combining production database clones with upgrade and/or rollback scripts that are optionally applied on demand, yields an efficient SQL Server CI pipeline.
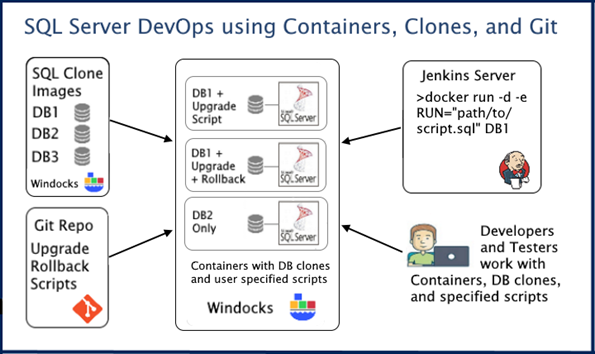
SQL Server DevOps with production databases and Git
The relational database CI workflow includes:
- projects (Releases, hot-fixes, micro service updates, etc)
- database images,
- database clones,
- SQL Server containers, and
- scripts pulled from the source repo.
Images are associated with projects, and user-defined stages (Dev, Test, UAT, etc.). A DBA (or image administrator) creates a database image and tags the image to identify the database(s) (e.g. Databases: Microservice A). The image is based on a dockerfile (below), that uses a backup, and pulls scripts from the Git repo into each container at run time. The image is built with a standard Docker client or web UI, using
>docker build –t imagename path/to/dockerfile
The contents of the dockerfile would be something like:
FROM mssql-2016
SETUPCLONING dbName path/to/backup/of/production/database
ENV USE_DOCKER_FILE_TO_CREATE_CONTAINER=1
RUN /path/to/git.exe clone path/to/scripts/repo
This creates an image for delivery of a writable cloned database and identifies the source repo that will be “pulled” for each container as it is created. The image stage is automatically set to "Database Ready”. If upgrade scripts are needed for the CI pipeline, the script developer sets the stage to “Development”. The developer develops and commits scripts to the Git repo, and creates new containers following each commit. Containers are created with a Docker command that specifies the scripts to be applied to the database.
>docker create –e RUN=“path/in/container/to/upgrade-script.sql” imagename
Once the upgrade script is completed work begins on the rollback script. The rollback script is committed to the Git repo, and new containers are created, with both upgrade and rollback scripts applied. Once the rollback script is complete, the developer updates the stage for the image as “Testing” and the test team begins their work. The command below creates a container with a terabyte database and with upgrade and rollback scripts applied, and is complete in 30 seconds.
>docker create -e RUN=”path/in/container/to/upgrade-script.sql, path/in/container/to/rollback-script.sql” imagename
A tester can now create three containers, one with just the production database clone, one with the upgrade script, and a third with the upgrade and rollback script applied. Each container is assigned either Pass or Fail after testing, and work continues until all containers Pass, and the image is set to “Stage: Database and Scripts Ready”.
The CI pipeline orchestrator (Jenkins, Azure DevOps, etc) can now create database environments with upgrade and/or rollback scripts applied during pipeline builds. Once a release is completed and the upgrade/rollback scripts are applied to the production database, the image can be marked as inactive.
Secure use of containers and production data
Continuous Integration with production databases must include built-in security. In addition to secure Windows based deployments Windocks is also used to bring SQL Server to Linux platforms such as OpenShift and Pivotal PKS.
Windocks SQL Server containers are delivered by cloning a locally installed SQL Server instance, and are delivered as conventional SQL Server named instances. This approach ensures compatibility with Windows Authentication and Active Directory, and supports the proven security of SQL Server namespace instances. As a result, Windocks containers do not face the security concerns of Docker containers that rely on public image repos, which can be a source of security vulnerabilities. User/group role based access controls ensure only authorized users’ access images and containers. Windocks also includes encrypted secrets to protect sensitive credentials.
The National Institute of Standards and Technology (NIST) has published a guide to Container Security (NIST SP 800-190), and a complete review of Windocks security provisions is available at: https://windocks.com/files/SQL-Server-Container-Security-NIST-SP-800-190.pdf
SQL Server database clones support a full range of SQL Server database protections, with SQL scripts applied during image build and at run-time to address database encryption, External Key Managers (EKM), data masking, and other security needs. The combination of SQL Server containers and database cloning reduces the overall attack surface within the enterprise, with fewer hosts used. Data sprawl in the form of backup copies is curtailed, as data images become a secure, authoritative SQL Server data catalog.
Windows SQL Server containers for DevOps
This new approach makes it practical to “develop on production,” with an approach that can be implemented on a single server, with data security built-in from end to end. This approach also holds appeal as it enables existing SQL Server based projects to modernize, as Microsoft continues to emphasis use of SQL Server Linux containers for SQL Server 2017 and 2019.
Get started today by downloading the Windocks Community Edition, available at https://windocks.com/community-docker-windows

