

Introduction
Typically we use the same column name across different tables (and views) to denote the same item of data. For example, you would expect a column called ‘DomainId’ to have the same meaning and same datatype in all the tables it is part of.
However, databases often contain columns with the same name that have been defined with different datatypes. These mismatched columns can cause problems.
Columns with the same name, in different tables, are typically used to link tables together (as key/foreign keys). If the datatypes are not the same, the optimiser has to do additional work to make the columns comparable. SQL Server will silently convert one of the datatypes. This additional work is an unnecessary overhead. In some cases it can also mean an otherwise useful index is not used, resulting in a further decrease in performance.
An incorrectly defined column has implication for data integrity, potentially invalidating both the underlying table and any client applications i.e. the data may be inconsistent, and be a source of application errors. For example, if a column should have been defined as datatype int, but has been defined as a tinyint, a large value will cause an overflow error.
Having different datatypes for the same column has implications for maintainability. Client applications (e.g. stored procedures or ADO.NET clients) often need to define the types, if the column has mismatched datatypes, which column’s datatype should the client use without extending the problem into the client arena?
Column Mismatch Utility
The SQL used in this utility is given in Listing 1.
To determine if a column has been defined with different datatypes across tables, in a given database, we need to look at the INFORMATIONAL_SCHEMA.COLUMNS view. This view has everything we need to determine if a column has mismatched datatypes, namely the column name, schema, table, and datatype.
In the utility, we identify mismatched columns by joining the INFORMATIONAL_SCHEMA.COLUMNS view to itself, based on the column name, but where the datatypes are not the same.
To further refine the utility, we also compare the maximum character length (CHARACTER_MAXIMUM_LENGTH) and the numeric precision and scale attributes (NUMERIC_PRECISION and NUMERIC_SCALE). This will identify columns that have been defined with the same name and datatype but have different sizes.
To sort the results by some kind of importance weighting, the density of the column name within all the column names is first calculated, and the results joined to the previously defined two INFORMATIONAL_SCHEMA.COLUMNS view join. The final dataset is sorted by column density (shown as % in the output).
Note that the INFORMATIONAL_SCHEMA views are database specific, thus you need to run the utility inside each database you are interesting in.
Running the utility in a database in my SQL Server gives the results given in Figure 1.
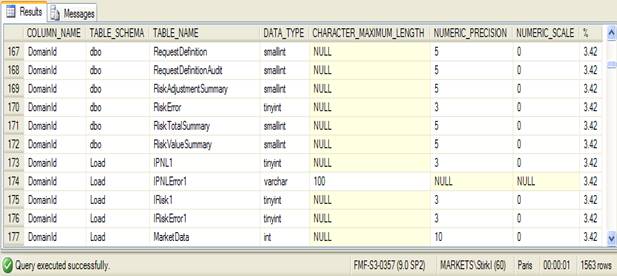
Figure 1 Output from the Mismatched Columns utility.
The results show how the datatype for the same named column varies across tables. Here you can see the column DomainId has been defined variously as a tinyint, smallint, int, and varchar.
Discussion
Some columns will be identified as having mismatched datatypes but they are really columns having the same name that describe different things, in this case it is better to give them different names e.g the column IsYearEnd might be a bit in one table and a varchar(3) in another table, the latter should be renamed IsYearEndChar.
Some of the columns identified might be due to a view’s definition being out of date. In this case, using sp_refreshview will correct this.
The identified mismatched columns will need to be corrected. It should be a simple matter to identify the correct datatype for a given column, it might take longer to correct any clients applications that use the column.
On a pre-emptive note, this utility can be used as part of a QA process to ensure any columns in new or amended tables are defined consistently across different tables, before being migrated to a production environment.
The utility described in this article allows you to quickly identify which columns have mismatched datatypes across tables in a database. Recognising and correcting these columns will improve performance, data integrity, and maintainability.
Further work
It should be possible to extend this utility to identify any mismatched columns across all the databases on a given server, perhaps leading to a basic Data Dictionary.
Currently the utility will output datatype mismatches for both tables and views, it is possible to filter the output so that only tables or only view is displayed by joining to INFORMATION_SCHEMA.TABLES or INFORMATION_SCHEMA.VIEWS respectively.
Ideally it would be useful to be able to map a stored procedure’s parameter datatypes to the underlying table columns to determine if these too are correctly defined.
Column name density is used to sort the results, giving them some kind of importance weighting. It might be better to combine this with some other measure, e.g. the number of rows in the table, or column usage (e.g. by stored procedures), to give a better metric of a column’s importance.
It may be possible to create a more granular utility by examining other fields in the INFORMATION_SCHEMA.COLUMNS view including: COLUMN_DEFAULT and IS_NULLABLE.
It might also be worthwhile investigating the use of ‘types’ to provide a consistent column definition.
Conclusion
The utility described in this article will allow you to quickly identify which columns have mismatched datatypes across tables in a database, and should prove valuable in the everyday work of the SQL Server DBA/developer.
Credits
Ian Stirk has been working in IT as a developer, designer, and architect since 1987. He holds the following qualifications: M.Sc., MCSD.NET, MCDBA, and SCJP. He is a freelance consultant working with Microsoft technologies in London England. He can be contacted at Ian_Stirk@yahoo.com.
Code
This code is also available for download in the Resource section below.
/*---------------------------------------------------------------------- Purpose: Identify columns having different datatypes, for the same column name. Sorted by the prevalence of the mismatched column. ------------------------------------------------------------------------ Revision History: 06/01/2008 Ian_Stirk@yahoo.com Initial version. -----------------------------------------------------------------------*/ -- Do not lock anything, and do not get held up by any locks. SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED -- Calculate prevalence of column name SELECT COLUMN_NAME ,[%] = CONVERT(DECIMAL(12,2),COUNT(COLUMN_NAME)* 100.0 / COUNT(*)OVER()) INTO #Prevalence FROM INFORMATION_SCHEMA.COLUMNS GROUP BY COLUMN_NAME -- Do the columns differ on datatype across the schemas and tables? SELECT DISTINCT C1.COLUMN_NAME , C1.TABLE_SCHEMA , C1.TABLE_NAME , C1.DATA_TYPE , C1.CHARACTER_MAXIMUM_LENGTH , C1.NUMERIC_PRECISION , C1.NUMERIC_SCALE , [%] FROM INFORMATION_SCHEMA.COLUMNS C1 INNER JOIN INFORMATION_SCHEMA.COLUMNS C2 ON C1.COLUMN_NAME = C2.COLUMN_NAME INNER JOIN #Prevalence p ON p.COLUMN_NAME = C1.COLUMN_NAME WHERE ((C1.DATA_TYPE != C2.DATA_TYPE) OR (C1.CHARACTER_MAXIMUM_LENGTH != C2.CHARACTER_MAXIMUM_LENGTH) OR (C1.NUMERIC_PRECISION != C2.NUMERIC_PRECISION) OR (C1.NUMERIC_SCALE != C2.NUMERIC_SCALE)) ORDER BY [%] DESC, C1.COLUMN_NAME, C1.TABLE_SCHEMA, C1.TABLE_NAME -- Tidy up. DROP TABLE #Prevalence
Listing 1 shows the code for the Mismatched Columns database utility