

Preface
It is beyond all dispute that most databases are used for searching purposes, and in many queries you have to search against a text field. If a text field has an index, most RDBMS are able to use that
index to speed up the search request, but there is an issue in using indexes. An index on a text field is useful only as long as the search criteria is SARGABALE (i.e. it does not begin with SQL search wildcards).
Things can get more complicated if you need to search an expression in the middle or at the end of a rich text field; the index on text field simply will be ignored by the relational database engine. So what should you do if you have a large table and most of your queries require searching in the middle or at the end of the text field? The answer to this question is Microsoft full-text Index. It is a great tool that allows fast and flexible indexing for keyword-based query of text data, stored in Microsoft SQL server database.
In contrast to the LIKE predicate, which only works on patterns, full-text queries perform linguistic searches against this data, by operating on words and phrases based on rules of a particular language. The types of queries supported include searching for:
- Words or phrases
- Words in close proximity to each other
- Inflectional forms of words
However using full-text search has some limitations that cause me to disregard it in many situations. The full-text catalogs and indexes are not stored in a SQL server databases, which means if you restore the database on another server you have to do a lot of effort to build that index again. Also you have to set up a job to maintains the changes to full-text index that means your index is not up to date, more over you have to start a service called Microsoft Full-Text Engine (MSFTE SQL).
Because of the limitations of this service, it is not suitable for all projects. In this article I
have decided to explain a bit more about the features. We will first begin looking at noise words.
What are noise words?
Assume that you are searching for a big house; what is the difference between a very big house and a big house? "Very" in this example is noise; therefore, the words that do not help the search are called noise words. For example, for the English locale, words, such as articles (i.e. "a","an"," the"), conjunctions (i.e. "and","but","while" and so forth), are considered noise words. The noise words differ from project to project, which means a word that is considered as noise in one case is a keyword in another case. You should identify your noise words accordingly. A good place to start is by looking at Microsoft noise-word file which is available in $SQL_Server_Install_Path\Microsoft SQL Server\MSSQL.1\MSSQL\FTDATA\ directory. This directory is created, and the noise-word files are installed when you set up SQL Server with Full-Text Search support.
Note:You can open the noise file with any text editor such as notepad.
Simulating the full-text index behavior
Although you can use this technique in SQL Server 2000, because of some new features in SQL Server 2005
that tempt me very much, I would rather use SQL 2005. First, I create a table to maintain the noise words.
create table dbo.NoiseWords( noise varchar(50) primary key )
You may populate this table with your own noise words or copy and customize the Microsoft noise-words file. This step is completely up to you. Also we need a table valued function to extract words from a string. Here is the function:
CREATE function dbo.ufnSplitWords(@s varchar(8000))
returns @out table (wrd varchar(8000))
as
begin
declare
@pos int,
@tmp varchar(8000),
@wrd varchar(50)
declare @UnwantedPunctuations table (punc char(1))
/*keep unwanted punctuations in a table,
you may customise these punctuation as you wish,but do not add double quote as it
has another meaning! */
insert @UnwantedPunctuations
select '.' union all select ',' union all select '?' union all select ':'
--Removing unwanted punctuations from the input string
update @UnwantedPunctuations
set @s=replace(@s,punc,' ')
set @s=ltrim(rtrim(@s))+' '
while len(@s)>0
begin
set @pos=CHARINDEX(' ',@s,2)
set @wrd=ltrim(left(@s,@pos))
--Removing unwanted punctuations
update @UnwantedPunctuations
set @wrd=replace(@wrd,punc,'')
if not exists(select noise from dbo.NoiseWords where noise=@wrd)
insert @out values( rtrim(@wrd))
set @s=ltrim(stuff(@s,1,@pos ,''))
end
return
end
As you see, the logic of this function is very simple. Maybe the update statement seems strange to beginners because it does not update any field of the underlying table; instead it removes all unwanted punctuations from @s. In fact the replace function will execute for each punctuation that is in @UnwantedPunctuations. The WHILE loop will execute repeatedly to extract words that are not noise and put them into output table (@out).
For the sake of this article, I have used the table "Person.Address", which is located in AdventureWorks ( a new sample database that is provided with SQL Server 2005). There is a text field in this table that I used it as test, called AddressLine1. the text data type will be removed after SQL server 2005, so it is better to use VARCHAR(MAX) instead of the Text data type. Now, we need a table to hold keywords for this field as well as main table dbo.Address:
select * into dbo.Address from Person.Address alter table dbo.Address add constraint pk_dbo_adress primary key(AddressID) CREATE TABLE dbo.Address_AddressLine1 (id BIGINT IDENTITY(1,1) NOT NULL, recNumber INT NOT NULL REFERENCES dbo.Address(AddressID)ON DELETE CASCADE , wrd VARCHAR(50), PRIMARY KEY CLUSTERED (recNumber ,id ) ) create index idx_dbo_Address_AddressLine1_wrd on dbo.Address_AddressLine1(wrd)
I used special naming with the format of tablename_richtextfield. This naming convention has the advantage of keeping the name of the child table (dbo.Address_AddressLine1) near the parent table (dbo.Address) when SQL server lists tables' name. Anyway you can use your own naming convention.
If your main table has already some records, you need to populate the child table. The following code will show you how to populate the child table, in this case dbo.Address_AddressLine1.
insert dbo.Address_AddressLine1(recNumber,wrd) select AddressID,wrd from dbo.Address CROSS APPLY dbo.ufnSplitWords(AddressLine1) as d
If I wanted to do the population in SQL 2000, I had to make an extra effort (maybe using damn cursors!). In order to do search I have written a STORED PROCEDURE as follows:
create proc dbo.uspSearchWords$Ver1 @search varchar(400) as declare @words table (wrd varchar(50)) SET NOCOUNT ON insert @words select wrd from dbo.ufnSplitWords(@search) as d select AddressID,AddressLine1 from dbo.Address A where not exists( select * from @words W where not exists( select * from dbo.Address_AddressLine1 where (wrd like w.wrd+'%' ) AND A.AddressID=recNumber ) )
The first statement will extract essential keywords and put them into @words. The second statement requires an explanation. Consider two set A and B. All members in A will exist in B if the result of A-B is an empty set, so the second NOT EXISTS acts as a minus operator and will subtract keywords of the current row of dbo.Address_AddressLine1(B set) From keywords of the input string(A set).
If all the keywords of the input string exist in the dbo.Address_AddressLine, then the result will be NULL and the first NOT EXISTS will interpret to TRUE and the record in dbo.Address will be include in final result set.
After testing the procedure and having a look at the subtree cost, I was really frustrated. It seems like all my efforts were in vain. In my second try to solve the problem I came up with the following procedure and its subtree cost satisfied me.
create proc dbo.uspSearchWords$Ver2 @search varchar(400) as declare @words table (wrd varchar(50)) SET NOCOUNT ON insert @words select wrd from dbo.ufnSplitWords(@search) as d select p.AddressID,p.AddressLine1 from dbo.Address p inner join (select recnumber from @words W inner join dbo.Address_AddressLine1 p on ( p.wrd like w.wrd+'%' ) group by recnumber having count(distinct w.wrd)=(select count(*) from @words))d on recnumber=p.AddressID
Most programmers think the only operator which is valid in front of the ON clause of a JOIN is equals, but they are mistaken. You can use all arithmetic operators as well as LIKE. In order to be sure that all words of input string exist in a record I have used Group by recnumber and compared the cardinality of @words against cardinality of the group.
Since I have used the LIKE operator, maybe there is more than one match for a word. It is very likely that the left hand side COUNT() returns a value which is not equal to the COUNT() of @words, so you need to use DISTINCT inside the COUNT() function. Also there is a trick behind COUNT(DISTINCT w.wrd). If you use COUNT(DISTINCT p.wrd),the result would be completely wrong. To clear this subject, assume you want to search for 'Moon Book' and we have the following data in our tables:
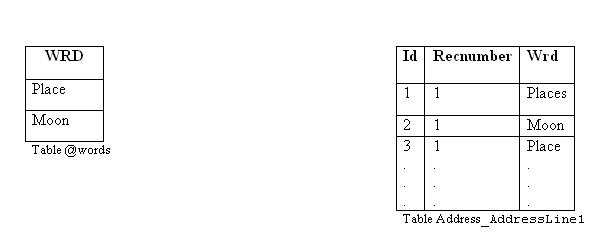
The COUNT (DISTINCT w.wrd) will return 2, but the COUNT (DISTINCT p.wrd) will return 3, which is not equal to count of @words.
NOTE: you should pass a string with no similar words to this stored procedure.
Dealing With Phrasal Search
Phrasal searching is different from word searching. One thing you should be concerned about with phrasal searching is white spaces. For instance "Moon Book" does not match with "Moon__Book" (Underscores used to show spaces). I suggest when you want to insert a row, firstly remove extra white spaces by means of REPLACE function, and then insert the new row.
After a lot of effort, I found out because of the sequential nature of phrasal searching (i.e. book is the next word after moon in "Moon Book"), which is not suitable for set based query, all additional SQL statements that deal with this matter will slow down the query; therefore, the question is how can I deal with phrasal searching?
Let's have a look at the following stored procedure that I provide you:
create proc dbo.uspSearchWordsAndPhrases @search varchar(400)
as
declare @words table (wrd varchar(50))
declare @Phrases table ( id int identity(1,1) primary key,phrase varchar(50))
declare @firstqoutePosition int,
@secondqoutePosition int,
@repacedDoubleQoutedString varchar(400),
@lengthOfSearch int,
@lengthOfrepacedDoubleQoutedString int
create table #InterimResult (id int identity(1,1), recnumber int,wrd varchar(50))
/*It is better to check if indexing can imporove the performance or not
for some soulution indexing on interim table only cause additional overhead */create clustered index idx_recnumber on #interimResult(recnumber,id)
SET NOCOUNT ON
select @repacedDoubleQoutedString=replace(@search,'"','')
select @lengthOfSearch = len(@search),
@lengthOfrepacedDoubleQoutedString =len(@repacedDoubleQoutedString)
--check for mathing even double qoutes
if (@lengthOfSearch-@lengthOfrepacedDoubleQoutedString) %20
begin
raiserror('missing double qoute',16,1)
return
end
insert @words
select wrd
from dbo.ufnSplitWords(@repacedDoubleQoutedString) as d
insert #InterimResult(recnumber,wrd)
select recnumber,w.wrd
from @words W inner join dbo.Address_AddressLine1 p
on ( p.wrd like w.wrd+'%' )
if @lengthOfSearch-@lengthOfrepacedDoubleQoutedString>0
begin
--extracting phrases from the input string
set @firstqoutePosition=charindex('"',@search)
set @secondqoutePosition=charindex('"',@search,@firstqoutePosition+1)
while @firstqoutePosition>0
begin
insert @phrases
select substring(@search, @firstqoutePosition+1,@secondqoutePosition-@firstqoutePosition-1)
set @search=stuff(@search,@firstqoutePosition,@secondqoutePosition-@firstqoutePosition+1,'')
set @firstqoutePosition=charindex('"',@search)
set @secondqoutePosition=charindex('"',@search,@firstqoutePosition+1)
end
;with cteWordsSearchResult
as(
select recnumber,AddressLine1
from
(
select recnumber
from #InterimResult
group by recnumber
having count(distinct wrd)=(select count(*) from @words)
) s
inner join dbo.Address p
on AddressID=recnumber
)
select *
from cteWordsSearchResult p
where not exists(
select *
from @Phrases
where not p.AddressLine1 like '%'+phrase+'%'
)
end
else
begin
select recnumber,AddressLine1
from
(
select recnumber
from #InterimResult
group by recnumber
having count(distinct wrd)=(select count(*) from @words)
) s
inner join dbo.Address p
on AddressID=recnumber
end
drop table #InterimResult
I have omitted double quotes from searching string and have added all words as well as words of phrases into @words table. So every record that resides in #InterimResult will have at least all words of the search string. I have added simple criteria to the WHERE clause in order to see if all phrases exist in main table (dbo.Address). In order to test the above stored procedures run the following code:
exec uspSearchWords$Ver1 ' place du ter' exec uspSearchWords$Ver2 ' place du ter' exec dbo.uspSearchWordsAndPhrases '70 "place du"'
INSERT, UPDATE, DELETE
I used ON DELETE CASSCADE in the CREATE TABLE dbo.Address_AddressLine1 Statement; therefore if a record is deleted from the main table, all its child's in Address_AddressLine1 will be deleted as well.
For inserting and updating, we need a trigger:
create trigger dbo.trg_IU_Address on dbo.Address after insert,update as declare @rowcount int set @rowcount=@@rowcount /*if no records affected,exit from trigger*/if @rowcount=0 return set nocount on if exists(select * from deleted) /*meaning the SQL statement that cause trigger to fire was UPDATE*/if update(AddressLine1) begin delete A from dbo.Address_AddressLine1 A inner join deleted d on A.recNumber=d.AddressID end insert dbo.Address_AddressLine1(recNumber,wrd) select AddressID,wrd from inserted as I CROSS APPLY dbo.ufnSplitWords(I.AddressLine1) as d
At the beginning of the TRIGGER, I checked to see if there are any rows affected by the statement that cause the trigger to fire. If there is no record, I exit from the TRIGGER; this will happen when you have an update statement with a WHERE clause that does not mach any rows. if there is at least one record in DELETED, it means the statement that cause trigger to fire was an Update; therefore, I remove all the child records of the DELETED table from dbo.Address_AddressLine1. Then I populate dbo.Address_AddressLine1 with the new records that are in the Inserted table. The last step will occur for an insert statement as well.
Conclusion
Microsoft full-text index is a great tool for word and phrasal searching, but in many solutions it is not very suitable. I have tried to simulate some functionality for those cases. As with all solutions, you should test this carefully against your data to see if it is suitable for your situation or not. Hopefully, you will find this article useful.

