

Introduction
In my last article, Reporting Services: Adding extra columns / rows to a matrix I showed you how to add an extra column to a matrix. The basic idea was to write a stored function that retrieves the data in the way it is needed. This allows you to expand the standard functionality of a matrix which only supports subtotals and totals.
You can use a similar method to solve another common problem: Reporting Services cannot join 2 data sets. If you want to build a table or a matrix which holds data from two different SELECT-statements, you have two options:
- You could use sub reports which suffer from poor performance and limited export functionality (Excel).
- You could develop a stored function to bring together all the relevant data. Then, you have only one SELECT-statement - from Reporting Services' perspective.
In this article, I want to show how to use the second method to retrieve data from Analysis Services and a SQL Server relational database in one dataset. As you can imagine, this leads to many new possibilities.
I will reuse the example I had in my previous article. I want to create the following report:

For this article, we assume that the actual values Jan 2008-May 2008 come from an Analysis Services cube and the target values come from SQL Server tables. (Of course, this is not realistic, but I think, it's a good example). If you want, you can download a backup of my (tiny little) cube at the end of that article.
The approach is quite straight-forward, but there are a lot of obstacles to overcome. Therefore I will describe the process step by step. We have to manage 2 main parts:
- get data from Analysis Services from T-SQL
- get the collected data to Reporting Services:
Get data from Analysis Services from T-SQL
Since we want to use the idea of a SQL-Server-Stored function to collect the data, we must be able to retrieve data from the cube within T-SQL.
For this, we are going to use a linked server to the cube and OPENQUERY to execute an MDX-Statement which reads the cube data.
Linked Server to Analysis Services
You can add a "linked server" to an Analysis Services cube within SQL Server Management Studio (when connected to the SQL Server relational database):
- Go to Server Objects > Linked Servers
- Right click and choose "New linked server ..."
- Fill in the fields in the popup:
- Linked Server: The name you want to use for the linked server - in our example "MYCUBE"
- Provider: Select Microsoft OLE DB Provider for Analysis Services 9.0 from the drop-down-list
- Product name: put any name here. It is not needed, but it is not allowed to stay empty. I use "empty" in my example.
- Data Source: the Analysis Services server - in my example "localhost"
- Catalog: the database of Analysis Services you want to use - in my example "Article_Sales"
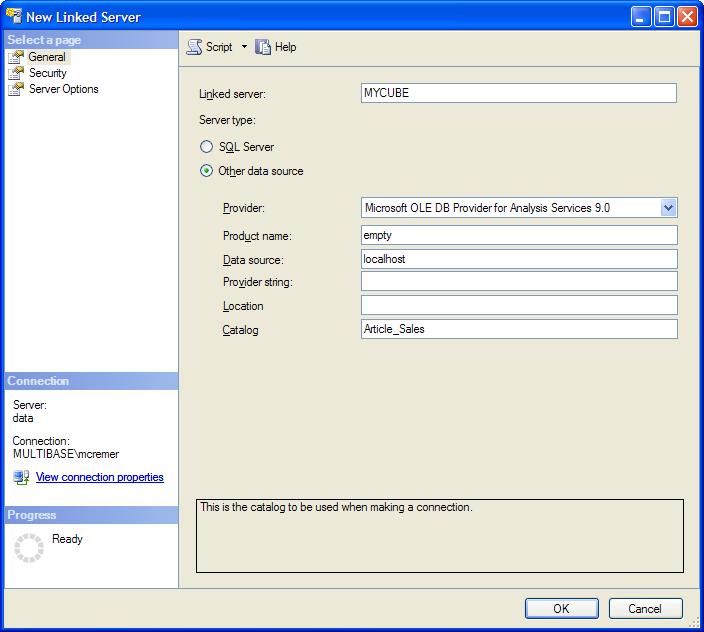
On the tab "Security" you should set the radio button to "Be made using the login's current security context". This will only work if you connect to SQL Server with Windows Security. Then this user will also be used to connect to Analysis Services. (Of course, you can change the settings according to your needs. However, be careful, not to open a security hole)
Build the appropriate MDX-statement
Now we need an MDX query to get the data. I assume you are familiar with MDX. If not, you can use Reporting Services to create the appropriate MDX-statement. You can use the Dataset-Designer to create the statement with drag-and-drop:
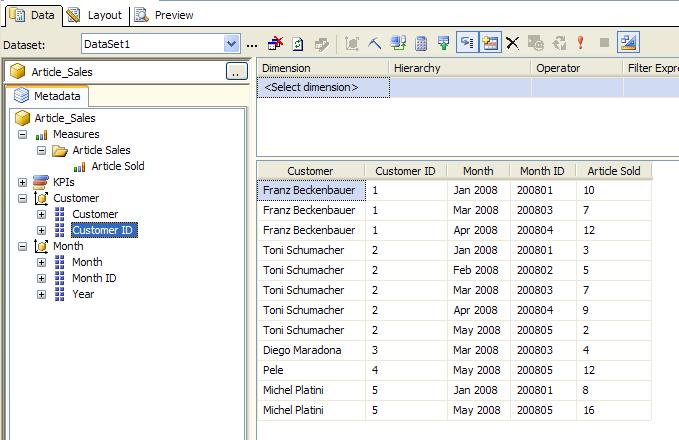
When you click on  you will see the MDX-statement corresponding to that query.
you will see the MDX-statement corresponding to that query.
Of course, this MDX statement is not optimized, so it's better to write a good MDX statement manually:
We start with the MDX statement giving us the customers, months and the amount of sold articles:
select [Measures].[Article Sold] on columns,
non empty [Customer].[Customer].[Customer].members *
[Month].[Month].[Month].members on rows
from [Article_Sales]
Since we need the IDs (we used them for ordering in my last article), we have to add the IDs as well. We could do that the same way Reporting Services' Dataset Designer does it by adding the ID-attributes. Since this is a cross join it is not efficient (in our example we will not see a difference since there is so little data, of course). Therefore we add "dimension Properties MEMBER_CAPTION, MEMBER_KEY" to our query which will give us the desired result - the name and the ID of the dimension element:
select [Measures].[Article Sold] on columns,
non empty [Customer].[Customer].[Customer].members * [Month].[Month].[Month].members
dimension Properties MEMBER_CAPTION, MEMBER_KEY on rows
from [Article_Sales]
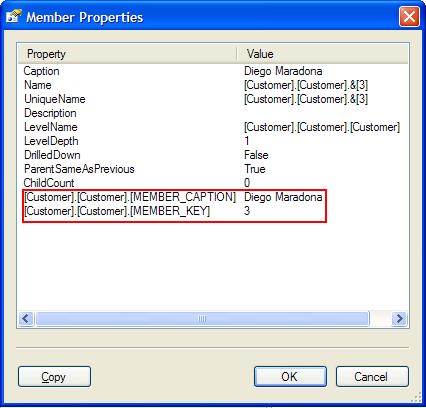
If you run these two MDX-statements in SQL Server Management Studio as an MDX-query, you will not see any difference in the result set, but click on any dimension member in a row and you will see two more entries in the popup:
Execute this MDX-Statement with OPENQUERY
Now we can execute the MDX-Statement with OPENQUERY within T-SQL:
select * from OPENQUERY(MyCube, 'select [Measures].[Article Sold] on columns,
non empty [Customer].[Customer].[Customer].members * [Month].[Month].[Month].members dimension Properties MEMBER_CAPTION, MEMBER_KEY on rows
from [Article_Sales]')
The result will contain the following columns:
- [Customer].[Customer].[Customer].[MEMBER_CAPTION]
- [Customer].[Customer].[Customer].[MEMBER_KEY]
- [Month].[Month].[Month].[MEMBER_CAPTION]
- [Month].[Month].[Month].[MEMBER_KEY]
- [Measures].[Article Sold]
We will need these column names later when we access the columns in a SQL-statement such as
select "[Customer].[Customer].[Customer].[MEMBER_CAPTION]" from OPENQUERY(MyCube, 'select [Measures].[Article Sold] on columns, non empty [Customer].[Customer].[Customer].members * [Month].[Month].[Month].members dimension Properties MEMBER_CAPTION, MEMBER_KEY on rows
from [Article_Sales]')
As you can see we used the column name with quotation marks to access the appropriate column.
This works fine, but it has one limitation: OPENQUERY only accepts a hard-coded string as the second parameter - neither a variable nor an expression is allowed. In our case, this is sufficient, but in real life, it is not: You will want to build your MDX-Statement dynamically, because your statement probably includes parameters. Then you should build the SQL-String (as shown above) dynamically and execute it with sp_executesql.
Let's assume the year is passed to the stored function parameter @year. Then, our SQL-Statement would look like:
declare @year as nvarchar(4)
set @year = '2008' -- this simulates a passed parameter
declare @mdx as nvarchar(4000)
set @mdx = 'select [Measures].[Article Sold] on columns, non empty [Customer].[Customer].[Customer].members * [Month].[Year_Month_Hierarchy].[' + @year + '].children dimension Properties MEMBER_CAPTION, MEMBER_KEY on rows
from [Article_Sales]'
declare @sql as nvarchar (4000)
set @sql = 'select * from OPENQUERY(MyCube, ''' + @mdx + ''')'
exec sp_executesql @sql
[Be careful not to forget the ''' before and after @mdx.]
Side remark "allow inprocess"
Sometimes the above shown OPENQUERY-statement gives an access denied-error. For my case it did on 2 production servers. However, on my local machine it worked perfectly fine.
This error can be fixed by allowing inprocess for the MSOLAP-Provider for Linked Servers.
You can set this property with the following steps:
- Go to Server Objects > Linked Servers > Providers > MSOLAP
- Right click and choose "Properties"
- Enable "Allow inprocess"
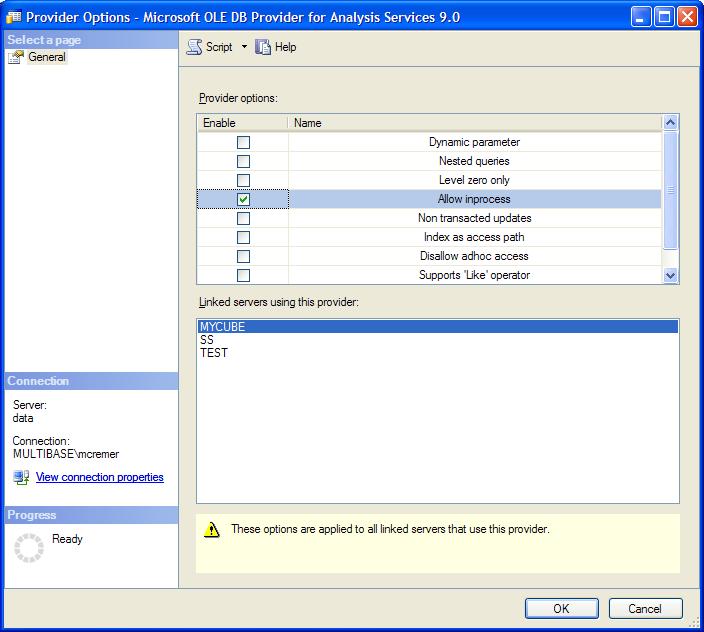
Microsoft advises to set this property for performance issues anyway.
Now we've finished the first task of accessing the Analysis Services cube. It's now time to address the second task of bringing this data into Reporting Services.
Reporting Services gets the desired data
Replace the SQL statement of the last article's example by the OPENQUERY-SQL
The SQL statement of my last article, which reads the actual data, was
SELECT ArticleSales.CustomerID, Customers.CustomerName, ArticleSales.MonthID, Months.Monthname, ArticleSales.ArticleSold
FROM ArticleSales INNER JOIN
Customers ON ArticleSales.CustomerID = Customers.CustomerID INNER JOIN
Months ON ArticleSales.MonthID = Months.MonthID
In order to use the OPENQUERY-statement the same way as the old statement, the OPENQUERY-statement should return the 5 needed columns in the appropriate order. This is easy with what we have learned above. I added the @columns-variable into my script:
declare @mdx as nvarchar(4000)
set @mdx = 'select [Measures].[Article Sold] on columns, non empty [Customer].[Customer].[Customer].members * [Month].[Month].[Month].members dimension Properties MEMBER_CAPTION, MEMBER_KEY on rows
from [Article_Sales]'
declare @columns as nvarchar(4000)
set @columns = '"[Customer].[Customer].[Customer].[MEMBER_KEY]", "[Customer].[Customer].[Customer].[MEMBER_CAPTION]", "[Month].[Month].[Month].[MEMBER_KEY]", "[Month].[Month].[Month].[MEMBER_CAPTION]", "[Measures].[Article Sold]"'
declare @sql as nvarchar (4000)
set @sql = 'select ' + @columns + ' from OPENQUERY(MyCube, ''' + @mdx + ''')'
exec sp_executesql @sql
Actually we should convert the columns to the appropriate data types, since OPENQUERY returns ntext for all the column results. In order to convert them to int, we first need to convert them to nvarchar(...). Therefore, the @columns-variable should finally read like the following:
set @columns = 'convert(int, convert(nvarchar(10), "[Customer].[Customer].[Customer].[MEMBER_KEY]")) as CustomerID, convert(nvarchar(50), "[Customer].[Customer].[Customer].[MEMBER_CAPTION]") as CustomerName,
convert(int, convert(nvarchar(10), "[Month].[Month].[Month].[MEMBER_KEY]")) as MonthID,
convert(nvarchar(50), "[Month].[Month].[Month].[MEMBER_CAPTION]") as MonthName,
convert(int, convert(nvarchar(10), "[Measures].[Article Sold]")) as ArticlesSold'
Stored Procedure
Since we need to use sp_executesql in our SQL-statement, we cannot use a stored function any more. If you try, SQL Server produces the following error:
Only functions and extended stored procedures can be executed from within a function.
Ok, so now we have a problem.
We now need to change the stored function to a stored procedure.
The first idea is to use a @CrossTab-table-variable, then the changes will be minor. This will not work, however, since this variable will not be accessible within sp_executesql. Therefore, we must use a temporary table, #CrossTab. The changes in detail:
- In the beginning we create the #CrossTab manually
- We replace all the references of @CrossTab to #CrossTab
- In the end we return all the entries of the #CrossTab
- In Reporting Services, we execute the Stored Procedure instead of the Stored Function
The changes in Detail:
| Old text | New text | |
|---|---|---|
| Start | CREATE FUNCTION [dbo]. [createReportExample3] () RETURNS @CrossTab TABLE ( rowSort int, rowDesc nvarchar(50), colSort int, colDesc nvarchar(50), value int ) AS BEGIN | CREATE PROCEDURE [dbo]. [createReportExampleWithAS2] as BEGIN CREATE TABLE #CrossTab ( rowSort int, rowDesc nvarchar(50), colSort int, colDesc nvarchar(50), value int ) |
| References | INSERT INTO @CrossTab (rowSort, rowDesc, colSort, colDesc, value) | INSERT INTO #CrossTab (rowSort, rowDesc, colSort, colDesc, value) |
| Return values | RETURN | SELECT * FROM #CrossTab |
| Reporting Services | SELECT * FROM dbo.createReportExample3() | exec dbo.[createReportExampleWithAS2] |
Missing fields in Reporting Services
So far, our approach was simple and straight-forward. There is only one problem: it is not going to work:
Reporting Services cannot detect the fields of the temporary table correctly. There will not be any fields contained in this dataset and, henceforth, we cannot build our report 🙁
You could try to add the fields manually, either in the datasets-window when right-clicking on the appropriate dataset or when editing the selected dataset (button ... in tab "Data") in the "Fields" tab.
I managed to enter the numeric fields (rowSort, colSort, value), but failed to enter the string fields (rowDesc, colDesc). As soon as I enter them I get an error when executing the reports, even if this field is not shown on the report:
Index was outside the bounds of the array.
(I think this is a bug in Reporting Services or the OLE DB driver, but - any way we have to live with it.)Therefore we have to find another solution.
Non-temporary tables
Since temporary tables do not work, the next option is to create a real table (In my example, I will call it ExampleReport-table).
Of course, you could use global temporary tables like ##CrossTab. These tables vanish when the last connection is closed which uses this table. If two users accessed the report at the same time, we would need to check the existence of the ##CrossTab-table which would not make the solution simpler.
When we use real tables, we must make them "multi-session-proof". This means, the solution must work in circumstances as well, when 2 (or more) users call the report the same time. Therefore, our stored procedure cannot simply empty and fill the table.
The most straight-forward method is to have a column in the real table which holds the session information. This means some changes for the stored procedure:
- The table does not need to be created inside the stored procedure any more.
- At the beginning of the stored procedure, a session-identifier is created. The best data type for the session-identifier is a uniqueidentifier (Guid), because this is unique for every stored procedure call by default. From now on I will call it session-guid
- All inserts into the table need to insert the session-guid as well.
- Even more important, all selects from the table must have an extra WHERE-condition to make sure we only retrieve the data of the current session.
- In the end, you can delete the records in the table belonging to this session.
There is one crucial point: You must double check that you added the WHERE SessionGuid = @sesGuid condition to every SELECT-statement. You will not receive an error message as you do when you forget it in the INSERT-statement, but you will retrieve wrong data.
Therefore, I encourage you to omit the delete-statement first and check whether or not you're getting the correct data. In this test, the table is filled with lots of data rows, which simulates the simultaneous execution of the stored procedure.
Now we have succeeded, and our changed code generates the result shown at the very beginning. (I did not speak about the layout of the report since this did not change from the last article).
Here is the SQL-statement for the table ...
CREATE TABLE dbo.ExampleReport
(
sessionguid uniqueidentifier not null,
rowSort int not null,
rowDesc nvarchar(50) not null,
colSort int not null,
colDesc nvarchar(50) not null,
value int null
)
... and the stored procedure in our example:
CREATE PROCEDURE [dbo].[createReportExampleWithAS3]
as
BEGIN
declare @sesGuid uniqueidentifier
set @sesGuid = newId()
/* basic crosstable data */
declare @mdx as nvarchar(4000)
set @mdx = 'select [Measures].[Article Sold] on columns,
non empty [Customer].[Customer].[Customer].members * [Month].[Month].[Month].members dimension Properties MEMBER_CAPTION, MEMBER_KEY on rows
from [Article_Sales]'
declare @columns as nvarchar(4000)
set @columns = 'convert(int, convert(nvarchar(10), "[Customer].[Customer].[Customer].[MEMBER_KEY]")) as CustomerID,
convert(nvarchar(50), "[Customer].[Customer].[Customer].[MEMBER_CAPTION]") as CustomerName,
convert(int, convert(nvarchar(10), "[Month].[Month].[Month].[MEMBER_KEY]")) as MonthID,
convert(nvarchar(50), "[Month].[Month].[Month].[MEMBER_CAPTION]") as MonthName,
convert(int, convert(nvarchar(10), "[Measures].[Article Sold]")) as ArticlesSold'
declare @sql as nvarchar (4000)
set @sql = 'INSERT INTO ExampleReport (sessionGuid, rowSort, rowDesc, colSort, colDesc, value) select ''' + convert(nvarchar(100), @sesGuid) + ''', ' + @columns + ' from OPENQUERY(MyCube, ''' + @mdx + ''')'
exec sp_executesql @sql
/* add total column */
INSERT INTO ExampleReport (sessionGuid, rowSort, rowDesc, colSort, colDesc, value)
SELECT @sesGuid, rowSort, rowDesc, 300000 as colSort, 'Total' as colDesc, sum(value)
FROM ExampleReport WHERE sessionGuid = @sesGuid
Group by rowSort, rowDesc
/* add target column */
INSERT INTO ExampleReport (sessionguid, rowSort, rowDesc, colSort, colDesc, value)
SELECT @SesGuid, ArticleSalesTarget.CustomerID, Customers.CustomerName, 300010, 'Target', Target
FROM ArticleSalesTarget INNER JOIN Customers ON ArticleSalesTarget.CustomerID = Customers.CustomerID
/* add delta column */
INSERT INTO ExampleReport (sessionGuid, rowSort, rowDesc, colSort, colDesc, value)
SELECT @sesGuid, isnull(total.rowSort, target.rowSort), isnull(total.rowDesc, target.rowDesc), 300020 as colSort, 'Delta' as colDesc, isnull(total.value, 0) - isnull(target.value, 0)
FROM (SELECT * FROM ExampleReport where colSort = 300000 and SessionGuid = @sesGuid) as total
FULL OUTER JOIN
(SELECT * FROM ExampleReport where colSort = 300010 and SessionGuid = @sesGuid) as target ON total.rowSort = target.rowSort
/* add total row*/
INSERT INTO ExampleReport (sessionGuid, rowSort, rowDesc, colSort, colDesc, value)
SELECT @SesGuid, 1000 as rowSort, 'Total' as rowDesc, colSort, colDesc, sum(value)
FROM ExampleReport where SessionGuid = @sesGuid
Group by colSort, colDesc
SELECT * FROM ExampleReport WHERE SessionGuid = @sesGuid
DELETE FROM ExampleReport WHERE SessionGuid = @sesGuid
END
Some final remarks
When you want to put this solution into production, you have to consider error robustness. We need to add this to our solution:
Try - Catch when reading data from Analysis Services
I do not want to talk about problems arising if the SQL Server or Analysis Services are down, because you will need to have a solution for this anyway (or the decision you don't need it).
Often, with solutions such as this one, errors can occur, which need to be handled:
Assume the MDX-statement does not return any data. We can force this situation by adding a filter on the year 2007:
select [Measures].[Article Sold] on columns,
non empty [Customer].[Customer].[Customer].members * [Month].[Month].[Month].members dimension Properties MEMBER_CAPTION, MEMBER_KEY on rows
from [Article_Sales] where (Month.Year.[2007])
Then we will get a result set with 1 column "Article Sold" but no row.
Therefore, our OPENQUERY does not return the columns which we expected. This means the SELECT * FROM OPENQUERY(.. would work fine, but the SELECT "[Customer].[Customer].[Customer].[MEMBER_CAPTION]", ... FROM OPENQUERY(... will lead to an error:
Invalid column name '[Customer].[Customer].[Customer].[MEMBER_KEY]'.
Since this error can occur, so we need to take care of that error.
The best method is to wrap the SELECT OPENQUERY part into a try-catch-block.
Now the error is caught and we have to decide what needs to be done. In our example, it is quite easy. Since there is no actual data, there should not be any columns in our matrix. Therefore, we do not do any inserts. This means our Catch-Block does not do anything. Depending on your situation, this may vary.
In our example, the part of the code looks like:
declare @sql as nvarchar (4000)
set @sql = 'INSERT INTO ExampleReport (sessionGuid, rowSort, rowDesc, colSort, colDesc, value) select ''' + convert(nvarchar(100), @sesGuid) + ''', ' + @columns + ' from OPENQUERY(MyCube, ''' + @mdx + ''')'
BEGIN TRY
exec sp_executesql @sql
END TRY
BEGIN CATCH
/* An error would arise if the MDX does not return any rows */
/* In this case we do not need to do anything */
END CATCH
Of course, the error handling could be more sophisticated. You could check whether the MDX works but does not return a row. With this, you could distinguish between "Server unavailable" and "no data". For my example, this is not necessary.
Next steps
Now you have a method which allows you to gather data from different data source types (ORACLE, SQL Server, Analysis Services, ...) or different cubes, for example.
In one of my productive reports, I used it for getting information from two different cubes. This solution was superior (in terms of performance) to building a bigger cube and having a complex MDX-statement gather the data in one statement.
In real-life scenarios, you will naturally have parameters for the stored procedure, but this is not a problem to implement, so I did not cover this subject.
Example data
You can download the example here. This includes
- The SQL scripts for the demo data
- The SQL scripts for the stored procedure and the table
- The solution which holds the Reporting Services and Analysis Services example
- A backup of the Analysis Services database.
Acknowledgements
I want to thank bteague for reading my draft of this article and his valuable comments.
