

Why Fragment an Index?
Recently I was tasked with rewriting database maintenance routines for a large (4000+ database) enterprise. One of the areas that warranted some concentration was the existing reindexing procedure, which was not entirely affective for a couple of reasons:
- The size of the index (in pages) was not factored in when determining whether to defragment or not, thus causing lots of small indexes to be ineffectively reorganized or rebuilt, wasting I/O and time.
- Indexes with a high amount of free space were not being reorganized unless they happened to be reindexed for a different reason.
By leveraging SQL 2005 dynamic management views I was able to more accurately target the indexes that needed defragmenting while also selecting the best method to reindex (ONLINE = ON/OFF, REBUILD, REORG). The end result was a much faster and more accurate reindexing system. While the improved index selection algorithm is an interesting topic (perhaps for another paper) the notion of a recreatable test plan to test the reindexing routine became an interesting technical challenge as I tried to create a predictable index fragmentation machine.
Creating Index Fragmentation Machines
Because I was testing my index selection algorithm, I needed a reliable way to create an index with specific amounts of fragmentation, specific number of data pages and also a specific amount of most of you, index fragmentation was not a subject that I'd studied under a microscope. I knew it was caused by insertion and deletion of data and that page splits also contribute significantly. Index growth patterns are fairly well documented, but there is no documentation on how to purposefully create index fragmentation other than the common sense notion to "apply lots of inserts and deletes". Because this process was a black box, I needed to apply different inputs and examine the output to find any patterns. In short, I would have to write some code and examine the results.
The Prototype Machine
My first method for creating a fragmented index was very simple: Create a clustered index on an integer column and perform incremental inserts (n, n+1, n+2) or deletes based on a weighted coin toss function that randomly decided whether to insert or delete.
Figure 0: the simple index fragmentation machine
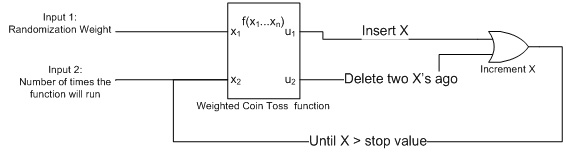
The Weighted Coin Toss Function
One of my favorite SQL functions is the RAND() function for generating random numbers. It's very useful for when management wants to collect a random sampling of records or when you need to do something that requires a little bit of entropy. In this case, I wanted to have a weighted coin toss (N is heads and 100-N is tails instead of 50/50 odds of heads or tails). To accomplish this I used the RAND() function to generate a random integer between 1 and 100 and compare it against the specified weight (N). The pseudo code is below:
Set @randomweight = (some value between 1 and 100)
--heads
if cast (100 * RAND() + 1 as int) >= @randomweight
insert a record
--tails
else
delete the record inserted two passes ago
This first effort was measured and calculable and a good first try as indicated by the graph of the results.
Figure 1: Results of machine 1 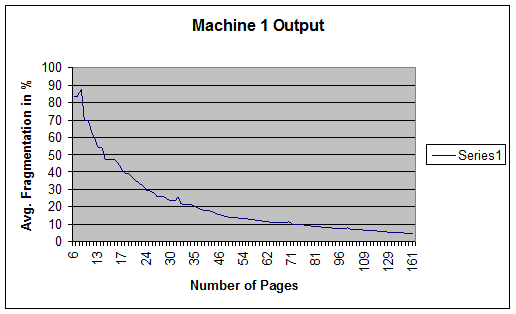
The programming behind this machine was very simple, but ultimately it only created fragmentation on indexes with less than 35 data pages. After that, higher math took over and as the number of data pages approaches infinity, the amount of fragmentation approaches 0%. This was not acceptable if I wanted to test my defragmentation routine on large indexes.
The Second Machine
My next effort was decidedly more sinister. I theorized that completely random inserts and deletes would be a faster way to fragment an index. It would also be more closely related to a real world index and hopefully not fall into the same pattern as the first machine. What this new machine did was fill both a clustered and nonclustered varchar(8) index with random UPPERCASE letters. Deletes were also random. This method turned out to be a fragmentation bomb! It took very little input to completely fragment an index to almost 100%. It should be noted that the same levels of fragmentation occurred on both clustered and nonclustered indexes, which was as expected. I removed clustered indexes from my further testing based on this finding.
Figure 2: Random insert and delete machine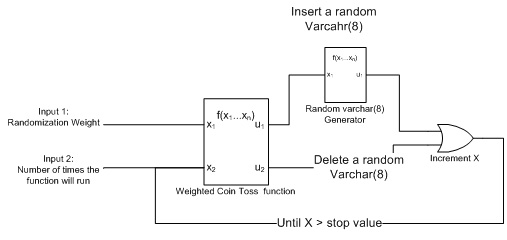
The Random Varchar(8) Generator
Once again I used the RAND() function with different influences to target a random range of values, in this case ASCII characters 65-90. (The UPPERCASE letters).
By multiplying our random value * 26 I am assured to get a value between 0 and 25, then adding 65 to the output number gets me up into the range I want to be. I loop through the function 8 times and append each new character onto the string.
while @n < 8
begin
set @fragchar = @fragchar + char(cast (26 * RAND() + 65 as int))
set @n = @n + 1
end
The output of this machine was consistent and predictable, but I had no way of targeting a specific level of fragmentation, unless it was near 100%.
Figure 3; results of Random insert/ random delete.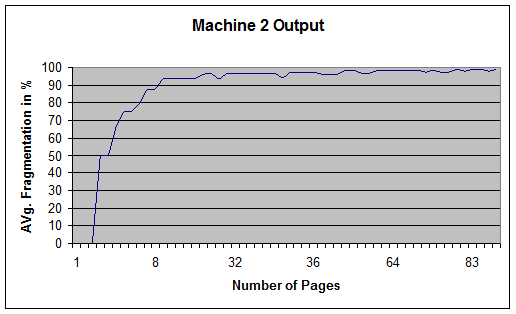
I also discovered by trial and error that with it didn't matter if I deleted any records in my machine or not: the level of fragmentation approached 100% regardless. After testing the second machine, it was clear to me that a synthesis of the two methods was needed for granular (and hopefully linear) control. I also decided to take out the delete portion of the code because it was ineffective, as were updates which I also tried. With this in mind, I gave the predictable index fragmentation machine one more shot.
The Final Machine
My new machine took 3 inputs, the randomization rate (for the weighted coin toss), the number of times to loop through the program, and a new serialization weight input that controlled how many records would be inserted in a serial (incremental) manner when the randomization "coin toss" was won.
Figure 4: The predictable index fragmentation machine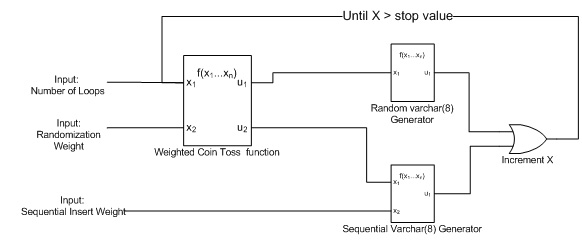
Figure 5: The results of the new and improved machine
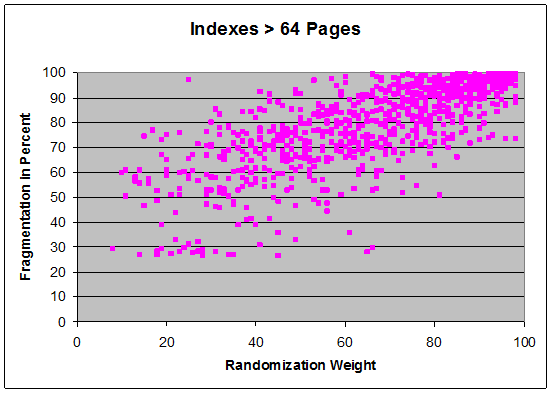
Success!
As you can see there is a general trend of predictability based on the randomization weight. It should also be noted that the number of data pages had no direct correlation with the average fragmentation percent. The most important thing was that my goal was met: running the machine with the same input values produced the same results (within a standard deviation). This machine was indeed predictable.
Below are the results of 30 loops through the machine with a serial insert weight of 4000 incremental inserts. These results clearly follow the trend from the overall graph and appears to be a more or less linear function based on the randomization weight. The dips and spikes in the graph can be attributed to the effects of randomization and circumstantial things like page splits.
Figure 6: Graph of specific inputs 4000 and 30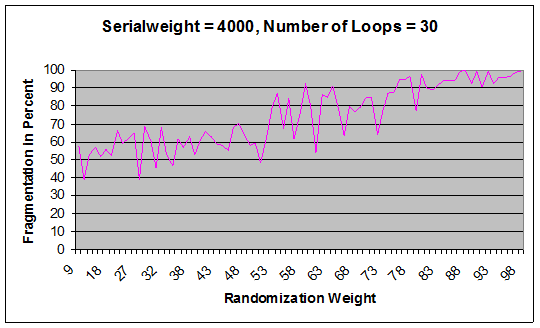
The final machine was consistently able to target number of index pages and fragmentation percent I was looking for by using a combination of all three input variables.
This final version of the fragmentation machine was clearly predictable, and understanding the effects of incremental inserts as opposed to random inserts was the key to its success.
Appendix A: The Code
/* --use this section to create your environment USE [master] GO -- CREATE A DATABASE. USE DEFAULTS, IT WON'T GET TOO BIG IF (select count(*) from sysdatabases where name = 'IDX_FRAG_DB') > 0 DROP DATABASE [IDX_FRAG_DB] GO CREATE DATABASE [IDX_FRAG_DB] GO --BUT THE LOG FILE MIGHT GET FULL.... LET'S BE PROACTIVE. ALTER DATABASE [IDX_FRAG_DB] SET RECOVERY SIMPLE GO USE [IDX_FRAG_DB] GO if object_id('FragTable') is not null drop table FragTable go CREATE TABLE FragTable ( fragchar varchar(8)) --need to create the fragchar non-unique non-clustered index go CREATE NONCLUSTERED INDEX [IDX_FRAG_NC] ON [dbo].[FragTable] ( [fragchar] ASC ) GO */ if object_id ('[usp_fragmachine]') is not null drop proc [usp_fragmachine] go create proc [dbo].[usp_fragmachine] @serialweight int, -- value > 0 number of serial records to insert in a row if the coin toss is lost @randomweight int, -- value between 1 and 100; weight of the coin toss (higher number favors random inserts) @numloops int -- value > 0. The number of times to execute the routine. -- The higher the numloops and serialweight, the more data pages you will get as set nocount on declare @i int, @n int, @fragchar varchar(8), @lastchar varchar(8), @twoCharsAgo varchar(8), @z int --only accept good values (minimal error handling) if @serialweight <= 0 return -1 if @randomweight > 100 or @randomweight < 1 return -1 if @numloops < 1 return -1 --start the loops through the machine set @i = 0 set @lastchar = '' while @i < @numloops begin --toss a coin (weighted) and if the toss wins, insert random data if cast (100 * RAND() + 1 as int) >= @randomweight begin set @n = 0 -- initialize the counting loop var set @fragchar = '' -- zero out the random varchar --generate the 8 byte varchar in this loop while @n < 8 begin set @fragchar = @fragchar + char(cast (26 * RAND() + 65 as int)) set @n = @n + 1 end --save this varchar so you can use it on the next coin toss set @lastChar = @fragChar --then put it in the table insert into FragTable select @fragchar end else -- if the coin toss is "lost" insert incremental data. while @z < @serialweight begin insert into FragTable select (left(@lastChar,(8-len(cast (@z as varchar(1000))))) + cast (@z as varchar(1000))) set @z = @z + 1 end --feed and water some counting loops set @z = 0 set @i=@i + 1 end select @numloops as number_of_loops, @randomweight as randomweight, @serialweight as serialweight, * from sys.dm_db_index_physical_stats(db_id(), object_id('FragTable'), null, null, 'DETAILED') return 0
Appendix B: Generating Free Space Fragmentation.
Good ideas strike when you least expect them: I had an inspiration that I could very simply increase the amount of index free space by reducing the size of data already in it. Simply put, I would blow up the balloon, and then let a little air out.
Since I wanted to affect the indexes as little as possible, I chose to reduce the size of the index key data using the LEFT() string function. By removing the right X characters from the index the amount of data stored in each page is reduced while keeping the number of data pages close to the same. This method, however clever also influences the amount of fragmentation and is a little unpredictable... but it works! After some trial and error I was able to use the index fragmentation machine with specific values, then let some air out of the index with the LEFT() function to prime an index to my specifications.
update fragtable
set fragchar = left(fragchar,7)

{kind=link}