

Temporal calculations are almost always the most requested set of requirements for a multidimensional SSAS implementation. Recently I had a scenario whereby a client wanted to examine their data using multiple calendars and calculations and this article details the approach that I took.
There are many ways to achieve temporal calculations, but my favoured method over the years has been to use some sort of variation on Marco Russo’s brilliant Date Tool Dimension method (http://sqlblog.com/blogs/marco_russo/archive/2007/09/02/datetool-dimension-an-alternative-time-intelligence-implementation.aspx). There are many advantages to this method: it’s flexible, scalable, and has the rare quality of being both developer and user friendly. The concepts defined in the above article are used throughout this one.
Most commonly, in a single cube there will be two calendars that users wish to slice data by: a standard Gregorian calendar and a financial calendar peculiar to the organisation. In these cases, using the Date Tool method, the simplest way to make this work is to have a block of code for one calendar and a block of code for the other, using SCOPE to use the correct context (more on this below).
A Note on SCOPE, THIS, and Context
An in depth discussion on the SCOPE statement in MDX is beyond the remit of this article (start with the MSDN page (https://msdn.microsoft.com/en-GB/library/ms145989.aspx) and do some research for examples) but a brief note on it is required to understand what follows. To quote the MSDN page:
“[SCOPE] Limits the SCOPE of specified Multidimensional Expressions (MDX) statements to a specified subcube.”
The keyword THIS (https://msdn.microsoft.com/en-gb/library/ms145569.aspx) is described by MSDN as follows:
“[THIS] Returns the current subcube for use with assignments in the Multidimensional Expressions (MDX) calculation script.”
I find that the easiest way to think of SCOPE is to think of it as a statement of context. Because MDX calculations are calculated at the time of a query then the context of the current query is important. So the following statement (using the AdventureWorks cube):
SCOPE ([Date].[Fiscal Year].&[2005]); THIS = [Measures].[Sales Amount Quota]*2; END SCOPE;
Could be read in plain English as: “If the current query includes the fiscal year of 2005, double the sales quota for that year”
It is not quite as simple as that, (for a start this SCOPE would only work if the Fiscal Year attribute was selected in isolation, but it may also be part of a hierarchy, in which case if the year was selected in the hierarchy then the above would do nothing. This is arguably poor design but is a discussion for another time...) however, it gives a general idea.
Context is important in the following scenario because the calculation uses the premise that whenever a hierarchy is not specifically selected then its All member is in context. This sounds strange but the following calculations make use of this behaviour.
Multiple Calendars
I recently worked with a client that collects data from a number of different customers. They had multidimensional cubes in place but only had the functionality to query by the Gregorian calendar. During requirements gathering sessions, it transpired that each customer team (four of them) would like to be able to analyse their data using their customer’s own reporting calendar as well as the standard Gregorian calendar. They also wanted to utilise date calculations within these calendars; things like “Last Year” and “Year To Date”.
I knew that this would be possible with the Date Tool Dimension method, but I am a big fan of compact and easy to read code, so I did not want to have 5 big blocks of code covering each calendar. Although this would be possible, personally speaking, I think that having to look at one block of code to change a calculation is preferable to have to do it across 5.
I had previously read about nested SCOPE statements and their ordering behaviour on Chris Webb’s blog (https://blog.crossjoin.co.uk/2010/08/03/order-of-nested-SCOPE-statements/) so I decided to use them in conjunction with the All member of the different hierarchies serving as a way of excluding the other hierarchies out of the context.
After gathering the data for the customer calendars, I set them up in the Time dimension into different hierarchies and correct attribute relationships. This is a crucial part of the process and is often overlooked but not only can it have a performance impact, it can also result in incorrect data being displayed if it is not set up properly. Correctly setting up composite key and name columns in a temporal dimension is covered in the MSDN tutorial here: https://msdn.microsoft.com/en-us/library/ms166578.aspx
I set the hierarchies up as follows:
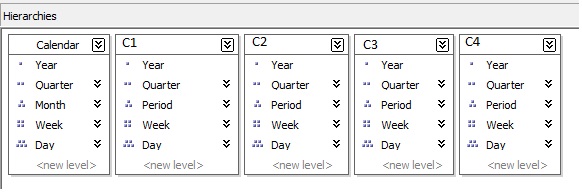
The first hierarchy is the standard Gregorian calendar and the subsequent ones belong to the individual customers (C1 – C4 for the purposes of this article).
I set up the attribute relationships in the following way:
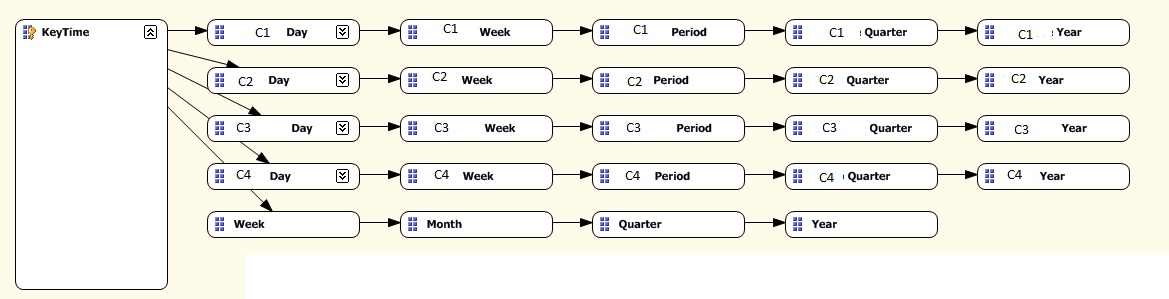
Two things to note here – firstly, each hierarchy relationship has its own complete distinct members. In other examples that may be seen, the most atomic level of the hierarchy (usually date [called Day in this example]) is shared by each hierarchy. This makes sense, since a date is a constant in a temporal dimension row. Using that methodology here would cause the subsequent MDX to function incorrectly at Day level – it would use whatever calendar hierarchy that you define the calculations on first at this level, no matter what hierarchy a query is using.
Note also that the Gregorian calendar hierarchy is using the generic day level. This is because we are going to use this as the "default" hierarchy in the MDX. For completion you could add in a day level for the Gregorian hierarchy and it would not make a difference - it would just give you the flexibility to have one of the other hierarchies as the "default". I prefer to leave it as above as it is a reminder of which is the default hierarchy.
Secondly, the relationships here are set as Rigid, rather than Flexible. During development, I would recommend that relationships are kept as Flexible, to cover incorrectly provided data and subsequent tweaks. Once it is fairly certain that things will no longer change then change the relationships to Rigid. A good explanation of relationship types can be found here (http://bidn.com/Blogs/userid/17/-repost-dimension-attribute-relationships-rigid-vs-flexible).
The MDX
Once the above has been set up for each calculation member that has been defined in the Date Tool Dimension then the pattern is as follows (unless the calculation references another in the dimension). For the sake of keeping the code as simple as possible for this article, a SUM function is being used here. In the real world (as in the original Date Tool Dimension) then use of AGGREGATE or a CROSSJOIN may better suit requirements as this would not affect pre-existing aggregation, like LAST NON EMPTY or DISTINCT COUNT to give but two examples. So a calculation for “Last Year” is defined as follows:
SCOPE ([DateTool].[Comparison].[Last Year]);
THIS =
//Default Calculation
SUM(
PARALLELPERIOD([Time].[Calendar].[Year],1,[Time].[Calendar].CurrentMember)
,
[DateTool].[Comparison].DefaultMember
);
/*If the all member is in context,
it means that the hierarchy is not in use therefore it does the calc on the other hierarchy.
These nested SCOPEs solve the problem of having >2 hierarchies to choose from*/
SCOPE ([Time].[Calendar].[All]);
THIS =
SUM(
PARALLELPERIOD([Time].[C1].[Year],1,[Time].[C1].CurrentMember)
,
[DateTool].[Comparison].DefaultMember
);
SCOPE ([Time].[C1].[All]);
THIS =
SUM(
PARALLELPERIOD([Time].[C2].[Year],1,[Time].[C2].CurrentMember)
,
[DateTool].[Comparison].DefaultMember
);
SCOPE ([Time].[C2].[All]);
THIS =
SUM(
PARALLELPERIOD([Time].[C3].[Year],1,[Time].[C3].CurrentMember)
,
[DateTool].[Comparison].DefaultMember
);
SCOPE ([Time].[C3].[All]);
THIS =
SUM(
PARALLELPERIOD([Time].[C4].[Year],1,[Time].[C4].CurrentMember)
,
[DateTool].[Comparison].DefaultMember
);
END SCOPE;
END SCOPE;
END SCOPE;
END SCOPE;
END SCOPE;As it mentions in the comments in the above code, it starts first with a “default” calculation. This default is effectively defined by the hierarchy used in the first nested SCOPE (“Calendar”, the Gregorian calendar). When SSAS evaluates a calculation at query time, it does so in a linear order (notwithstanding the use of SOLVE_ORDER or FREEZE). As such, by putting the All member of the “Calendar” hierarchy in the first nested SCOPE this excludes that hierarchy from all subsequent calculations within the SCOPE.
This is due to the fact that, unless the “Calendar” hierarchy is involved in a calculation then by default the All member is what is in context. This pattern is followed through the rest of the hierarchies before the SCOPEs are all closed at the end.
This pattern of nested SCOPEs is not needed if the calculation is referenced after it has been defined, as the pass through will go through the initial calculation first. For example, to define the current (contextual) year minus the (already calculated) previous year then the calculation would be:
SCOPE ([DateTool].[Comparison].[This Year – Last Year]);
THIS =
[DateTool].[Comparison].DefaultMember – [DateTool].[Comparison].[Last Year];
END SCOPE;As with everything, this is only one method of solving this particular problem but I like it as it keeps code compact and clean and is easy to maintain going forward. One thing to note is that this code will produce unpredictable results if you crossjoin two different time hierarchies - but personally I can't think of a reason why anyone would need to do that.
Many thanks for reading and please feel free to comment/criticise.

