

Introduction
Loading non-duplicated from source is often an exercise needed in the data warehouse environment. In this article, we walk through an example of how all the rows that are duplicated can be removed by using Integration Services (SSIS). Below are the steps given to achieve the same.
Building a Package
For our example, let’s assume that following table (Stage Source 1) is loaded into our environment with data as shown below:
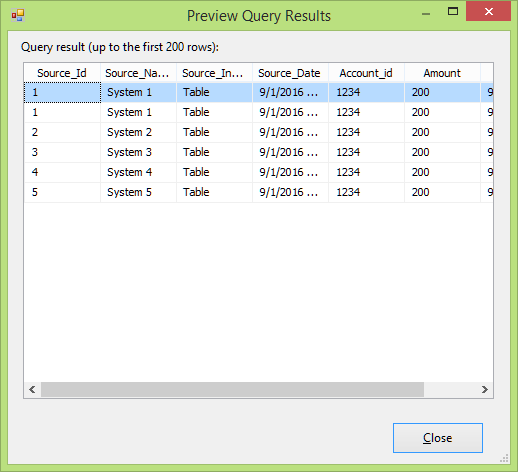
In this rows, with source id 1 are the duplicated rows. We will be developing a workflow using aggregator transformation to remove these duplicated rows as shown in the diagram below:

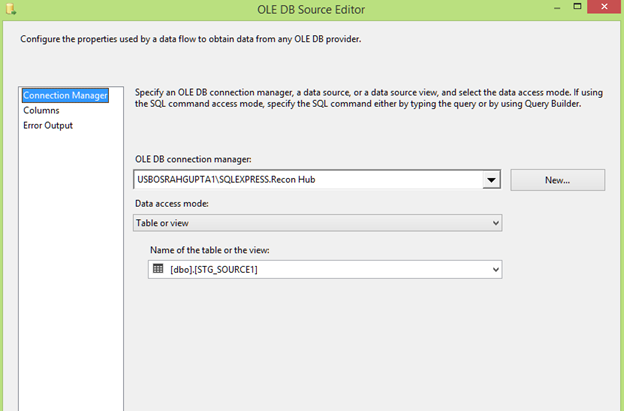
Configure the OLE DB source connection manager as shown below:
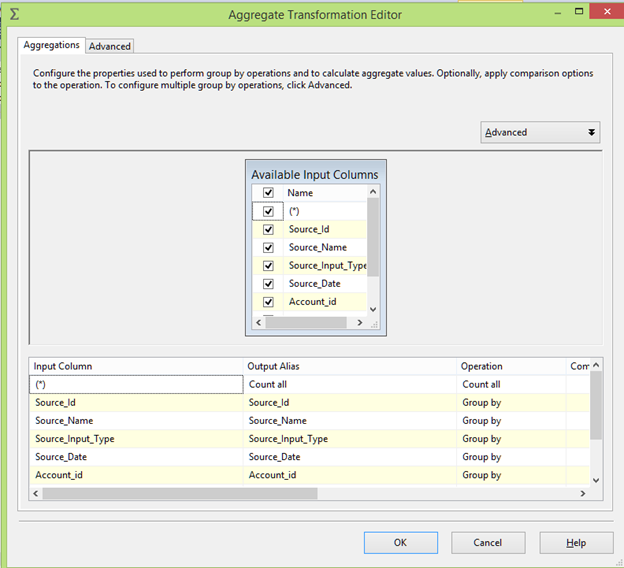
Configure the Aggregator transformation as shown below. Take the count of records and do a group by all the columns present in the table.
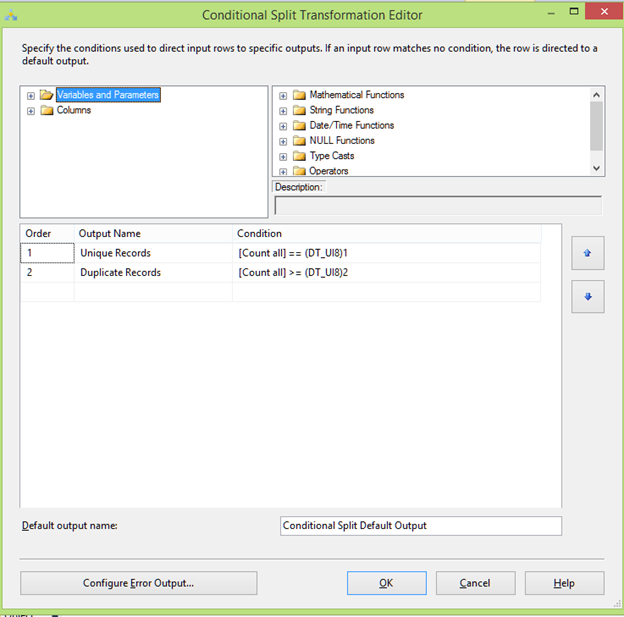
Now using the conditional split transformation let’s split the output into unique and duplicated records. The unique records are identified by the condition where record count is equal to one while the duplicated records are identified by the condition where record count is greater than one as shown in the figure below:

After running this step only the unique rows from Source id 2 to 5 (as these are unique records) will be loaded into the OLE DB destination . The duplicated rows will be ignored and not loaded into the OLE DB destination.
Summary
In this article, I have shown how to load data which don’t have duplicated records in source into the target using SSIS. This is useful in situations where we cannot remove the duplicated data in the source using sql. In those scenarios, SSIS can be used to load non-duplicated data into the target.


