

Extract-Transform-Load (ETL) is a process that is used to take information from one or more sources, normalize it in some way to some convenient schema, and then insert it into some other repository.
A common use is for data warehousing, where regular updates from one or more systems are merged and refined so that analysis can be done using more specialized tools. Typically, the same process is run over and over as new data appears in the source application(s). Many data warehouses also incorporate data from non-OLTP systems, such as text files, legacy systems, and spreadsheets; such data also requires extraction, transformation, and loading. In its simplest form, ETL is the process of copying data from one database to another. This simplicity is rarely found in data warehouse implementations. ETL is often a complex combination of process and technology that consumes a significant portion of the data warehouse development efforts and requires the skills of business analysts, database designers, and application developers.
ETL process is not a one-time event; new data is added to a data warehouse periodically. Many companies have data warehouses that are loaded nightly and used as READ ONLY databases for the applications during regular business hours. ETL processes must be automated and documented. The data warehouse is often taken offline during update operations. But what if data warehouse database used 24*7 even traffic at a load time is very low? It means that the database can't be taken offline during the load! This is the reality of my company and this presents some challenges for the DBA group to setup processes with following criteria:
- database must be online 24*7
- data (tables) can't be locked
- data must be consistent at any time. E.g. it can't be time when data is loaded partially
- If load is failed then the previous day data must be returned
Also, there are some other restrictions that require special architecture for the nightly ETL process.
Let's start with the fact that the ETL job itself is very complicated and consists of 60+ individual steps. If at least one step fails the whole job should fail and database should keep the previous day's data. The challenge to control data includes the fact that the load process can't be transactional because the data warehouse database used 24*7 even traffic at
night time is very low. This means that the database can't be locked or placed
offline. At the same time, load can't leave partially loaded data in case of
error and/or partially loaded data for users while load is running. It requires
mentioning that the ETL process usually runs for 30-60 minutes based on the
number of daily made changes.
After many hours of thinking I came up with this idea for the load based on the fact that this is the data warehouse and data changes ONLY with ETL process once a day.
I decided keeping 2 the same databases on the server. Let's call them LOAD and PROD databases.
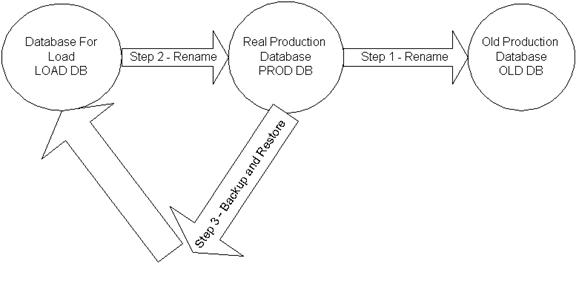
LOAD and PROD databases are the same at the time ETL process is started. ETL starts loading data to the LOAD database. If load is successful then LOAD database keeps the new data and PROD keeps the previous day's data.The next two steps will be done consecutively with no delay time in between.
Step 1 and 2 rename production database to the OLD database and rename LOAD database to PROD database. The rename process takes less than a second.
Step 3 backup production database and restore LOAD database from PROD backup to prepare for the next day's load. At the end we have the previous day's data in OLD database, current day's data in PROD database, and current day's data ready for the next day's load.
If you can't afford to keep 3 databases because of drive space restrictions or some other factors, then OLD database can be dropped. You don't need to restore LOAD database until the next load is started and it can be the first step for the ETL process. The picture below shows the whole process logic.
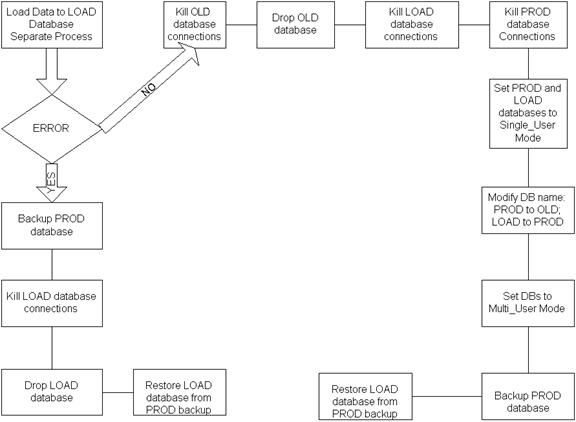
Let's see the code for the parts of the process.
Step - Kill database connections.
CREATE procedure dbo.KILL_DB_CONNECTIONS
@db_nm varchar(50)
as
begin
SET NOCOUNT ON
declare @tmpkill table (cmd varchar(255), tid int identity(1,1))
declare @cnt int, @cmd varchar(4000), @minid smallint, @maxid smallint
insert into @tmpkill(cmd)
select 'kill ' + cast(sp.spid as varchar) from master..sysprocesses sp
inner join master..sysdatabases sd on sp.dbid = sd.dbid
where sd.name = @db_nm and sp.spid <> @@SPID
select @minid = min(tid), @maxid = max(tid)
from @tmpkill
while (@minid <= @maxid)
begin
select @cmd = cmd
from @tmpkill
where tid = @minid
exec (@cmd)
set @minid = @minid + 1
end
SET NOCOUNT OFF
End
Step Set database to Single User Mode
SINGLE_USER | RESTRICTED_USER | MULTI_USER controls which users may access the database. When SINGLE_USER is specified, only one user at a time can access the database. MULTI_USER returns the database to its normal operating state
ALTER DATABASE PROD SET SINGLE_USER with rollback immediate
You need to remember that ALTER DATABASE permissions default to members of the sysadmin and dbcreator fixed server roles, and to members of the db_owner fixed database roles. These permissions are not transferable.
ROLLBACK IMMEDIATE specifies whether to roll back after the specified number of seconds or immediately. If the termination clause is omitted, transactions are allowed to commit or roll back on their own. Remember that this database is a data warehouse and used as READ ONLY source.
Step Modify database name
Alter database PROD modify name = OLD
Step Set database to Multiuser mode
ALTER DATABASE PROD set MULTI_USER
Step backup database to the database device
Backup database PROD to PROD_BAK with INIT
The step to restore LOAD database from backup file presents some challenge because each time databases are renamed or restored the physical file names should have unique name's.. The code below illustrate the example of the step restore from device LOAD_BAK and files named based on the database name LOAD, OLD, and PROD
declare
@prd varchar(100), @prd_old varchar(100)
select top 1
@prd = reverse(left(reverse(rtrim(ltrim(filename)))
, charindex('\',reverse(rtrim(ltrim(filename))))- 1 ) )
from PROD.dbo.sysfiles
select top 1
@prd_old = reverse(left(reverse(rtrim(ltrim(filename)))
, charindex('\',reverse(rtrim(ltrim(filename)))) - 1 ) )
from OLD.dbo.sysfiles
IF ( left(@prd_old,4) <> 'LOAD' and left(@prd,4) <> 'LOAD')
begin
restore database LOAD from LOAD_BAK with
move 'PROD_Data' to 'd:\Data\LOAD_Data.mdf',
move 'PROD_Log' to 'd:\Log\LOAD_Log.ldf',
recovery, replace, stats = 10
end
IF ( left(@prd_old,3) <> 'OLD' and left(@prd,3) <> 'OLD')
begin
restore database LOAD from LOAD_BAK with
move 'PROD_Data' to 'd:\Data\OLD_Data.mdf',
move 'PROD_Log' to 'd:\Log\OLD_Log.ldf',
recovery, replace, stats = 10
end
IF ( left(@prd_old,4) <> 'PROD' and left(@prd,4) <> 'PROD')
begin
restore database LOAD from LOAD_BAK with
move 'PROD_Data' to 'd:\Data\PROD_Data.mdf',
move 'PROD_Log' to 'd:\Log\PROD_Log.ldf',
recovery, replace, stats = 10
end
This is the logic if load is successful. If ETL process fails then PROD database must be backed up and the LOAD database must be restored from PROD backup (see picture above). You may notice from the process that the user's requests will be cut from the database during renaming process. This is true, but remember, it takes less than a second to switch the database's names and the user has to have active request during this time. Most of our requests are very short ,2-3 seconds, and traffic is very low at night time. During our tests we prove that the worst case scenario for the user will be an application message stated that user has to hit "Refresh" button to get the result.
Conclusion
The process may have some additional logic. For example, if you would like to keep the LOAD database when load fails, then the steps to rename LOAD to ERR database can be added to the process. It will allow you to make the load analysis and to find an answer for the question "why the load failed" easier. In our case, we added some additional data verification and analysis steps to the process after the ETL is completed to verify the data integrity and business rules. If the fatal data rules violation is found then ERROR part of the process is started and loaded database renamed to ERR. LOAD database is restored from the PROD database. Next day DBA is analyzing the data issues from ERR database. But the process of data verification and analysis is the topic for my next article.
We using this architecture for 6 months and there are no issues or user's complains.