

Introduction:
Database indexing is not an exact science. It's difficult to weigh the performance benefits adding indexes to a table will have. While adding indexes can improve performance on SELECT queries, it can slow down performance or introduce locking scenarios on highly transactional tables with a high number of INSERT/UPDATE/DELETE statements. With the release of SQL Server 2005, Microsoft has snuck in a few new ways to help you with this strategy. Most people are aware of the Database Engine Tuning Advisor which can provide good information by analyzing a workload from SQL Profiler, however there are other approaches which I'd like to discuss.
For this article, I'm assuming you have a good grasp of indexing basics: the difference between clustered and nonclustered indexes, how they are stored, how the query processor makes use of them, using them to "cover" a query, and the various index options. This isn't to teach someone how to index, per se, but hopefully add some new tools to your approach to indexing in SQL Server 2005. For demonstrations in this article I will be using the AdventureWorks database which comes with SQL 2005 or can be downloaded here. As with all performance "enhancements", things don't always work the way you'd think they would. For each change I would recommend you take a baseline, apply in a test environment first, measure against the baseline to be sure your changes have the desired affect, and always have an undo script.
Identifying Potential Indexes: sys.dm_db_missing_index_details
The new dynamic management views in SQL Server 2005 have done a lot to enable quick scripting of management functionality. One which has gone largely undocumented is sys.dm_db_missing_index_details. This stores a list of columns the query processor has gathered since the last server restart which would assist in covering the queries.
For the first example, I will execute the following code to view a list of orders and their details in the last 3 years with a value of $20,000 or more:
SELECTh.SalesOrderID, h.OrderDate, h.DueDate, h.TotalDue
, p.[Name] AS Product_Name, d.OrderQty, d.UnitPrice, d.LineTotal
FROMSales.SalesOrderDetail d
JOINSales.SalesOrderHeader h
ONh.SalesOrderID = d.SalesOrderID
JOINProduction.Product p
ONd.ProductID = p.ProductID
WHEREh.TotalDue >= 20000
ANDh.OrderDate >= DATEADD(yy, -3, GETDATE())Now it's time to go check the dynamic management view and see what the query processor picked up:

This view collects data for the entire server, yet I only want information about the current database (AdventureWorks), hence the WHERE database_id = DB_ID(). The last four columns are the ones you really want to look at here. Here's how they break down:
- equality_columns - This lists any columns where the query processor looked for an exact match (i.e. column = value). In this case it's null as we had no equality statements needing to be scanned upon in our WHERE clause. The only equal statements in there are on our JOIN conditions, however since all our key columns in the join have indexes on them they're not listed.
- inequality_columns - This lists any columns where the query processor looked for an inequality match. Greater-than, less-than, not-equal or BETWEEN predicates would fall in here. As we were looking for records which fell both above a certain value and a certain date, the OrderDate and TotalDue columns are listed here.
- included_columns - SQL Server 2005 allows you to specify non-key columns which will be stored with the index. This allows you to include more columns within the index so that you can cover queries more effectively while not requiring the data in those columns to be sorted during transactional processing.
- statement - This is the underlying object on which the index would be created.
Your initial reaction here might be to think that Microsoft has done all the work for you, however this would be premature. This should be used to point you in the right direction for what to index, not build indexes directly off of it. In general you should build your indexes by listing the equality (most restrictive) columns first, the inequality columns second and specifying the included columns in your INCLUDE clause. If you stop here and build your indexes you may be missing a large part of the picture. Let me identify some other considerations you should think about:
- In practice I've seen this technique list columns in SELECT order, rather than the order in which they're scanned by the query processor. You would really gain the most performance by building the index in the order in which they query processor scans them.
- How large is the table? A narrow table and/or one that will not grow above 100 rows might not be worth indexing.
- You don't really know how often the queries which reference these columns are run. Are they one-time ad-hoc queries or part of a larger stored procedure which is run frequently? In the case in the example it's easy, however if you select from the same management view on a production machine you may have many rows returned. It is unlikely that building and maintaining an index which would be referenced only occasionally would do anything to increase performance.
- There may be multiple listings in this view which could all be covered by a single query. For instance if you add another line to the WHERE clause (say "ANDDATEDIFF(dd, h.OrderDate, h.ShipDate) > 7" to find any orders that didn't ship within a week) and re-run the query and then check the management view again. You should see an additional column in the list:

Instead of making two indexes, it might be better off to only create a single index including the extra column and allow the query processor to use that index to cover both queries. As always, set a baseline, implement the changes in a test environment, and measure the performance impact before implementing in production.
Identifying Potential Indexes: SET STATISTICS XML ON
While sys.dm_db_missing_index_details is good, you still need to trod carefully and think about how you use the columns it lists. A more focused approach is to use SET STATISTICS XML ON to receive an XML showplan result detailing how the query processor fulfilled the request. To return to our original example (with appropriate additions/commenting for this section):
SET STATISTICS XML ON; GO SELECTh.SalesOrderID, h.OrderDate, h.DueDate, h.TotalDue , p.[Name] AS Product_Name, d.OrderQty, d.UnitPrice, d.LineTotal FROMSales.SalesOrderDetail d JOINSales.SalesOrderHeader h ONh.SalesOrderID = d.SalesOrderID JOINProduction.Product p ONd.ProductID = p.ProductID WHEREh.TotalDue >= 20000 ANDh.OrderDate >= DATEADD(yy, -3, GETDATE()) --ANDDATEDIFF(dd, h.OrderDate, h.ShipDate) > 7 GO SET STATISTICS XML OFF; GO
Executing this block of code returns both the standard result set and a Microsoft SQL Server 2005 XML Showplan result. Clicking on the XML in Management Studio will bring it up in its own document for easier browsing. The element we want to focus in on is <MissingIndexes>:

As appropriate you will see various ColumnGroup elements for EQUALITY, INEQUALITY and INCLUDE which work in the same way as the previous example. The Impact value indicates an estimated improvement by the query processor assuming an index was created on the listed columns.
Specifying another predicate in the where clause which references another table (for instance "AND d.SpecialOfferID = 1") changes the XML plan when run to include multiple suggested indexes to improve overall query performance. In this case, adding the example above gives me this for my <MissingIndexes> element:
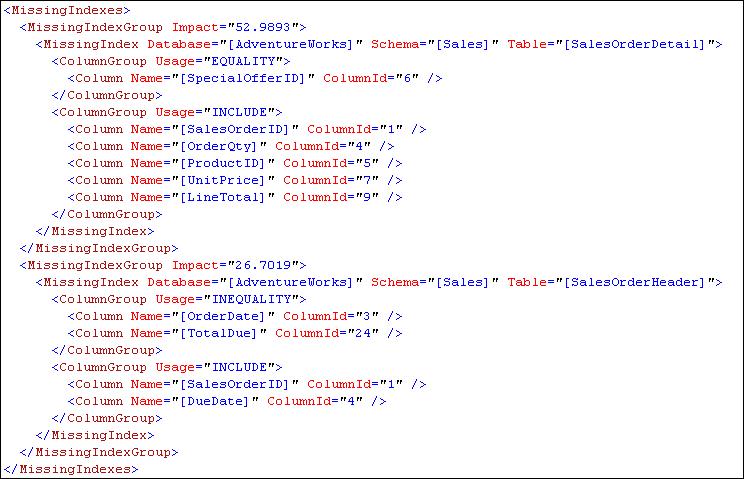
This shows two separate indexes on two separate tables which could assist in query processing.
This is very helpful in the early stages of improving problem queries. If you have an idea that a certain SQL statement is going to be repeatedly executed, using this technique can assist you in building better indexes on your tables.
Removing Unused or Problem Indexes: sys.dm_db_index_usage_stats
I once had a developer look me straight in the eye and say that there would never be a problem with adding as many indexes as possible to a table; the query processor would simply select the ones it needed and ignore the rest. While this is somewhat correct, it really falls far from the whole truth. Unnecessary indexes can force the query processor to evaluate more before deciding on an optimum execution plan, can slow down transactional processing and can take up a great deal of space on disk.
Index usage information is stored in another dynamic management view called sys.dm_db_index_usage_stats. Like the previous views, information available inside only persists since the last SQL Service startup. I would highly recommend you not evaluate information in this view until after the system has been running for an adequate period of time under normal load and usage conditions. This will allow you to obtain a decent set of information before determining which indexes to potentially remove.
With my warning out of the way, let's get to the code I like to use:
SELECTo.name AS object_name, i.name AS index_name , i.type_desc, u.user_seeks, u.user_scans, u.user_lookups, u.user_updates FROMsys.indexes i JOINsys.objects o ONi.object_id = o.object_id LEFT JOINsys.dm_db_index_usage_stats u ONi.object_id = u.object_id ANDi.index_id = u.index_id ANDu.database_id = DB_ID() WHEREo.type <> 'S'-- No system tables! ORDER BY(ISNULL(u.user_seeks, 0) + ISNULL(u.user_scans, 0) + ISNULL(u.user_lookups, 0) + ISNULL(u.user_updates, 0)), o.name, i.name
The reason I use a LEFT JOIN to sys.dm_db_index_usage_stats is to ensure that any indexes which have not been used since the last server restart are still listed accordingly. If my server has been up and running for six months without using that index, perhaps its time to consider dropping it! By sorting it in the order which I do, it moves the least used indexes to the top of the list. It's also important to note that indexed views will be listed in the object_name column.
I would highly recommend again that you factor in other considerations before removing or disabling indexes. It's important to make sure the database will not be using the index. It's also good to read this information even for your more commonly used indexes and examine the scans vs. seeks. This can provide good hints for optimizing your existing indexes and queries (for a good explanation of a scan vs. a seek, check out this entry in Craig Freedman's WebLog).
Summary:
As I said at the start, the intent of this article is not to teach you how to index. There are numerous resources devoted to this topic and it is beyond the scope of this article (see below for recommended reading). SQL Server 2005 gives you some great new tools to better understand index usage and gain insight into where new indexes might be helpful. While there is still no tool which can really replace a good understanding of how SQL Server makes use of indexes and where they can be beneficial, the information you can glean from the new dynamic management views and enhancements to viewing query statistics can assist you in optimizing your indexing to see real performance gains.
Recommended Reading:
- Index Creation Guidelines - Leo Peysakhovich
- Who Cares about FillFactor? - Gregory Jackson
- Index Basics - SQL Server 2005 Books Online (link doesn't work with FireFox)

