

Introduction
Elasticity is quite a buzz word these days: Elastic Cloud, Elastic Search, Elastic Database… Some do reflect the elastic nature of underlying products, some are just marketing tricks. Microsoft alone offers Azure Database Elastic Pool, Azure SQL Database with (or without) Elastic Tools, and Azure Elastic Data Warehouse.
In this article I’d like to take a closer look at some of the Microsoft cloud elastic solutions. To be able to evaluate how elastic they are, we need to define what we understand under elasticity. So let us, for the purpose of this article, define elasticity as an ability of a database to adjust to the load reasonably fast (and desirably, with little effort from us database administrators). Of course the adjustment should work both ways (for high and low load) – since it’s a cloud and we don’t want to pay for any under-utilized databases.
Azure Database Elastic Pool
I will not evaluate it here as it’s not much more than a marketing tool. It allows you to stretch your tier cost over a few databases but it won’t provide you more power. It still could be useful though, in that relatively rare case when you have a few databases that are never used simultaneously.
Azure SQL Database
With a single database obviously we are able to scale up and down only. For Azure SQL Database it means changing tiers. To evaluate it I came up with the following simple approach. I started with Standard 2 (S2, 50 DTU) and went up through Standard 3 (S3, 100 DTU) and Premium 2 (P2, 250 DTU) to Premium 6 (P6, 1000 DTU). I created a simple application to emulate e-commerce traffic to the extreme. That is the application in which the only function was to insert new customers, orders and, order items doing as few read operations as possible. Note that as you cannot avoid reads whatsoever, the application did the absolute minimum required: checking for customer and order existence and retrieving (once per session) customer and order details. On Figure 1 you can see the application workflow.

Also the application was able to run multiple threads to imitate multiple concurrent users. You can find the application and the SQL scripts here.
As a performance metric I chose the number of orders generated per second. The test consisted of increasing the number of threads running the user session emulator till the performance metric stalled. Once this point was reached, the Azure Database had been scaled up to the next tier. The number of threads running had been kept at the maximum during the transition and was dropped to zero after, to start over from scratch. During the test the DTU usage and prevailing waiting types had been monitored. The data is in the following table:
DTU | Max Orders/Sec | DTU Usage% | # of concurrent users |
50 | 47 | 100 | 50 |
100 | 60 | 100 | 60 |
250 | 140 | 55 | 200 |
1000 | 150 | 13 | 250 |
To illustrate the data I added a couple of charts. Figure 2 shows the relationship between the performance metric and the tier (measured in DTUs) and Figure 3 shows the relationship between the usage (%) and the tier.
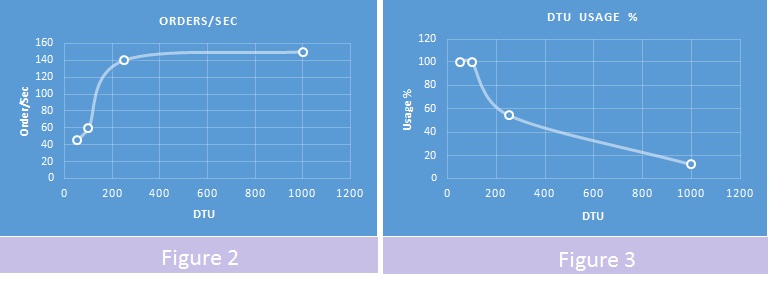
Though I did not expect to see exactly a straight line on Figure 2, the demonstrated asymptotic behavior was rather surprising (to say the least). And Figure 3 clearly shows that there was a lot of untapped processing power. So what is going on here? To find out we need to look at the waiting types that dominated the field when the maximum number of orders per second was reached. For S2 tier (50 DTU) the majority of them is LOG_RATE_GOVERNOR (meaning Azure resource governor is doing its job) – no surprises here. For S3 tier (100 DTU) it is still LOG_RATE_GOVERNOR and WRITELOG is closing up. It gets interesting on P2 (250 DTU) where we see a lot of spare power and a new waiting type, HARD_SYNC_COMMIT starting to climb to the top. And on P6 (1000 DTU) the system does not do much but waits on HARD_SYNC_COMMIT.
It looks like one of the Azure Database’s most prominent features, “High Availability”, clashes with another one – “Scalability on Demand”! It’s well known fact that keeping a synchronous replica affects overall performance. What comes as a surprise here, is the fact that the performance degrades that fast. I’m not aware of any way of switching to asynchronous mode – it would be interesting to know what Microsoft thinks about it. Will they address the issue or provide some level of control in the future?
All that said, Azure SQL Database still provides scalability, especially if your application is hungry for processing power. I’d give it an “acceptable” mark on a three point scale (“poor”, “acceptable”, “good”). The transition mechanism deserves a solid “good”. It’s not lightning fast, but won’t take days either and it’s done completely behind the scene with guaranteed consistency throughout the transition. I cannot tell for sure how it works but most likely, Microsoft uses a secondary replica to copy the majority of data to the new database located on the targeted tier. The transition does not interfere with the client activities until the very end (where it presumably switches to the new database). At that moment all new sessions will be bounced (not a big deal if your application has a retry capability).
Since Azure SQL Database limits the maximum database size (it’s rather large though - 1Tb) and due to performance considerations you might want as well to scale your databases horizontally (either by implementing sharding or applying the Separation of Concerns principle). In both cases it’s important to know how Azure SQL Database handles cross-databases queries (yeah, right, I know that we’re never going to have them). To figure it out I created two tables Test.Orders on the host database and Test.Customers on another database and registered it on the host one as an external table (the details can be found in the attached script register_external.sql).
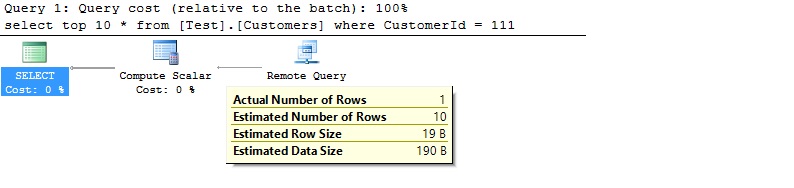
Scenario 1: Query that deals with objects from another database only
select top 10 * from [Test].[Customers] where CustomerId = 111
It worked excellent, the Azure SQL engine correctly sent the entire query to the remote database for processing, receiving only the results back. Look at the query plan:
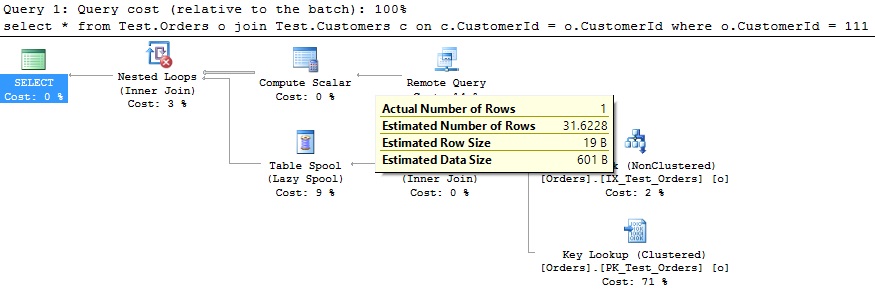
Scenario 2: Query that deals with a mix of objects (good case scenario)
select *
from Test.Orders o
join Test.Customers c on c.CustomerId = o.CustomerId
where o.CustomerId = 111
It worked excellent as well, the Azure SQL Engine correctly sent a subquery to the remote database and joined the received data with the locally retrieved ones. The query plan here looks quite good:
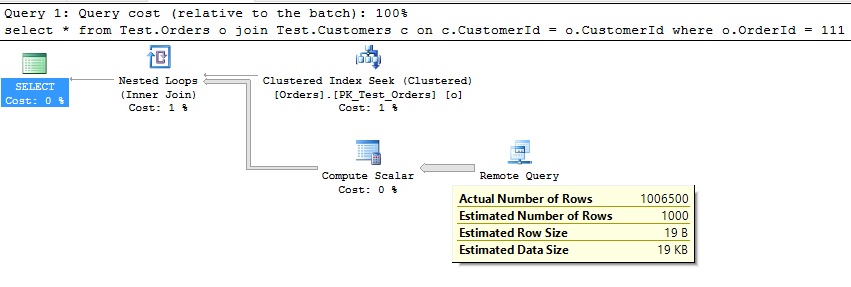
Scenario 3: Query that deals with a mix of objects (bad case scenario)
select *
from Test.Orders o
join Test.Customers c on c.CustomerId = o.CustomerId
where o.OrderId = 111
It was a disaster, the Azure SQL Engine could not build a proper subquery and pulled the entire table to the host database. The query plan tells us the sad story (note the Actual Number of Rows):
Despite the later I still think that Microsoft has done a good job here. However, I would avoid mixing local and remote objects in cross database queries. I believe the best approach would be to split them by hand into two parts – one dealing exclusively with the remote objects (and storing the results into temporary table, for instance) and another one handling the local objects.
Azure SQL Database with Elastic Tools (Sharding)
This is a set of Azure SQL Databases. It cannot be less than two of them (at least if you want to use Microsoft sharding tools) – one is a management database and one is a shard. As every single shard is a separate Azure SQL Database, one can expect an excellent scalability (given that the shards are located on different servers). Unfortunately, it comes at a price.
First and foremost, it’s the overall complexity of the system. You always have to remember the distributed nature of your data. Your applications must be “shard aware”. The client library provided by Microsoft helps but it’s available for .Net clients only. And your operational reports and tools might become your worst nightmare.
Second, it’s the moving data between the shards (back and forth). Microsoft provides a tool to make Split, Merge and Data Movement easier. It does a good job, but has its limitations. To transfer data it uses good old SqlBulkCopy behind the scenes. That means it relies on the Shard Management database for data consistency. In practice it takes the sharding key (or the range of them) “offline”, copies data in batches (you can control the batch size though) and after all of the data is copied, it removes the data from the source shard and sets the key (or the range) back “online”. Note the quotation marks here. They mean that the chunk of data being transferred is off or online only for those who bother to check the Shard Management database. If you have some large tables it can take quite a long time to move sharding keys around and during that time some data either will not be available for your application (if it’s written properly to respect the current Shard Management configuration) or conversely, will be seen on two shards simultaneously (if it’s not).
Third, it’s the sharding key itself. It is difficult to choose a good one as you walk a very fine line here. Your sharding key must be such that all your shards are engaged when dealing with your usual workflow (otherwise you won’t see the expected scalability). That is, it’s best to have as few sharding keys as there are shards when the system is maxed out. So we are looking at a single or double (at the most) digit number. On the other hand it should be granular enough (possibly four or more digits) to provide a relatively smooth transition from a single shard configuration (for instance) to a few and back to a single one (remember that we are talking about elasticity here!). Also, you have to add this key to every sharded entity and all your communications now must include it so forget about sending just Order ID as you used to do!
Would I use this approach for a new project where I anticipate a high load from the beginning and all the time? Maybe. For a system where I want to accommodate some seasonal traffic? Not so sure.
Azure SQL Data Warehouse
I know this was not designed to handle OLTP (and especially e-commerce) traffic. But as the concept looked really promising from elasticity standpoint I decided to have a closer look anyway (to be honest, I was toying with an idea of using it as a regular database).
Beneath the surface, it uses 60 distributions (the equivalent of shards) each with its own storage. You can think of them as of independent databases. A query will be parsed and sent to either one or all distributions for execution. The results will be gathered through temporary tables (if more than one distribution is involved). When you scale it, it moves some distributions to other nodes so ultimately you can have as many as 60 of them (quite a lot of power, isn’t it?). Since every distribution has its own storage, it seems the distribution does not have to transfer the data themselves, thus making the transition fast. My test showed (and Microsoft later confirmed it) that Azure SQL Data Warehouse does not have a full-fledged distribution elimination feature. Obviously it does it for inserts but that’s all. Selects and updates will be run on all distributions (that’s 60 queries!), no matter what distribution keys are involved. And even with pure inserts I could not see any performance benefits from scaling from one to a few nodes (I tried up to 6 of them). Apparently almost all the time is spent on parsing (it does not cache query plans), sending queries to distributions, and fetching data back to the control node. That said, it still should demonstrate noticeable scalability with real OLAP traffic (long running queries churning through a lot of data).
For those of you who want to use it - a few more observations. Many features we take for granted for SQL Server are missing here. Primary and unique keys, all DRI constraints, and identity, to name a few. It supports only one transaction isolation level – read uncommitted. The T-SQL language itself is also a bit different. One of the most widely used features, like an ability to populate variables using the select operator, is missing. In Azure SQL Data Warehouse you can only use the operator set for it.
Discussion
In my opinion, your best bet for an elastic database for now is Azure SQL Database. It scales reasonably well for many applications, does not bring extra complexity to your systems and (most important, at least in my eyes) the scaling itself is smooth and undemanding. Just follow the separation of concerns principle in your designs to keep your databases reasonably compact. For instance, keep order related objects in one database, and customer related ones in another.
All that said, I think that the search for elasticity is still on as none of these solutions quite cut it. In conclusion, I’d like to indulge myself in some kind of a dreaming exercise. What do I see as an ultimate elastic database? Here is my recipe.
Take Azure SQL Data Warehouse (multiple distributions, each with its own storage).
Drastically improve distribution elimination.
Allow to choose the tier(s) when scaling (like for Azure SQL Database), at least for the control node vs. the others.
Add support for most prominent SQL features we are accustomed to, like identity and DRI constraints.
Improve T-SQL language compatibility (at least add support for some very basic features like select to a variable).
Will Microsoft be willing to cook?


