

I had been entrusted to improve several SSIS packages that form part of a data warehouse ETL load. The area I was to focus upon was the Update phase. Snce the system was already in production, with 100s of packages, I had to offer different solutions weighing in the changes involved vs the expected improved performamce.
The two options I will highlight below can be applied to any type of package that performs updates, whether to dimension or fact tables.
Hardware
Although the underlying hardware plays a major role in database and package tuning, in this case I'll obviously be using the same hardware in evaluating the different options. The hardware I'm using is quite basic and it's being used as a development environment.
I made sure that no one was doing anything on the servers while I took the readings to get a non-distorted picture of the performance improvement.
Current System
The current system is based on an OLE DB Command updating a table. I have removed all the other processing from the package to make it easier to follow and just left the Reading Source component (which is an OLE DB Source) and a destination component which is an OLE DB Command. Inside the OLE DB Command, I have a simple UPDATE statement where I'm updating all table columns using either the Surrogate Key or the table's unique columns.
This setup is giving me approximately 99K executions/min (as seen from the Activity Monitor)
Option 1 (Multiple concurrent (3) Updates)
Option 1 is based on the principle of increasing the UPDATE threads that are sent to the SQL Server. In this example I've bumped up the UPDATE threads to three. This new setup gives me appoximately 255K executions/min, much better than the previous option.
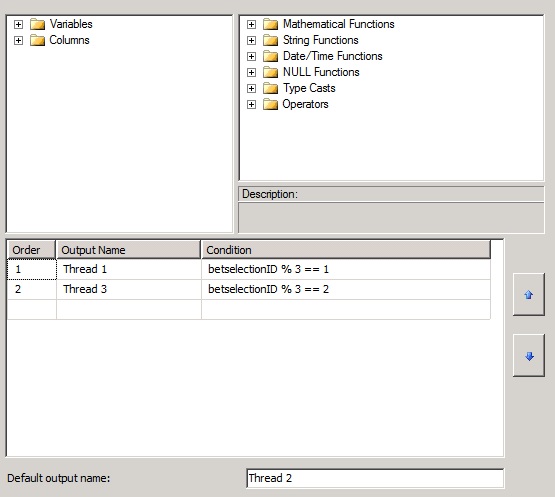
This is simply achieved by splitting the incoming Source into three threads using a conditional Split (below). I'm applying the SSIS modulus fuction to the Source ID and using the Integer remainder to split into multiple threads.
The image below is showing the Conditional Split component as setup for 3 threads.
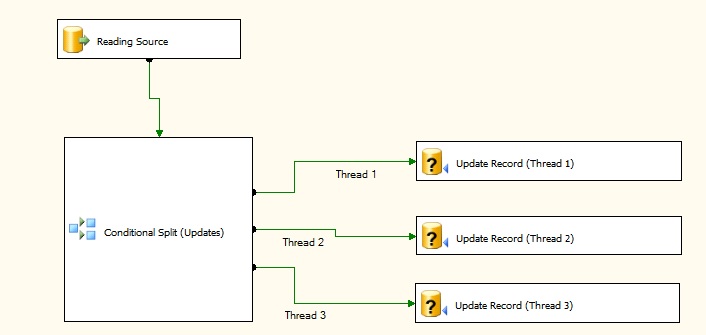
The image below is displaying how data flow will look once the additional update components have been created. This change is fairly simple and it's more a matter of copy & paste of components.
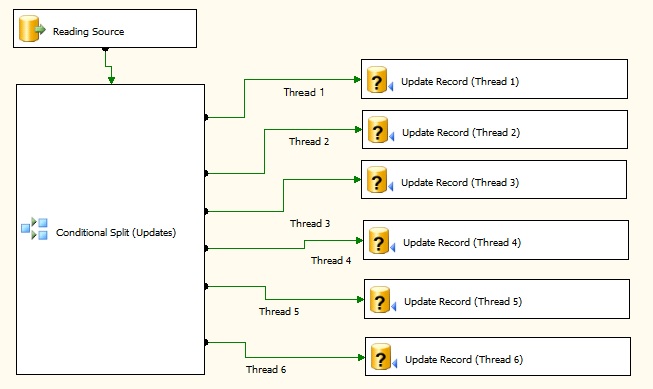
Option 2 (Multiple concurrent (6) Updates)
Option 2 is also based on the principle of increasing the UPDATE threads that are sent to the SQL Server. In this example I've bumped up the UPDATE threads to six. This new setup gives me appoximately 400K executions/min, better than the previous option and much better than the original setup.
As in option 2, this is simply achieved by spliting the incoming Source into six threads using a conditional Split (below).
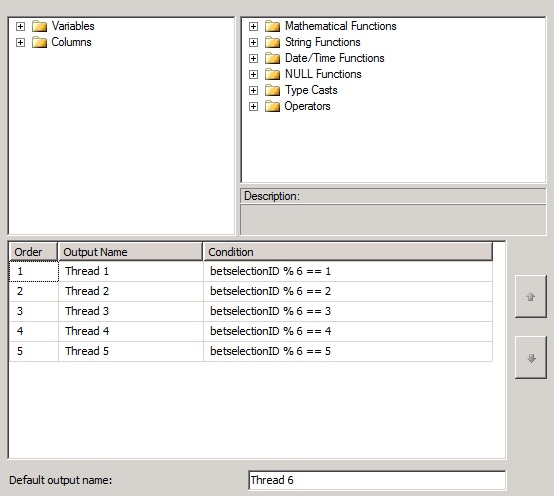
The image below is showing the Conditional Split component as setup for 6 threads.
The image below is a screenshot of the new data flow utilizing 6 update threads.
Option 3 (INSERT then UPDATE)
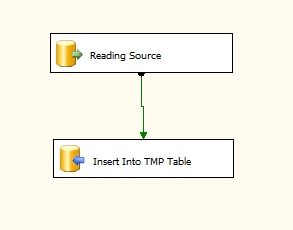
This option will involve the most development effort to implement. Here, the records requiring an Update (in our example, all records to keep it simple) will first be Inserted into a Temp Table using the fast Bulk Insert. This table will have the same structure as the final destination table, however without any column constraints & foreign keys. At this stage we need the fastest possible Inserts and a heap table is our best bet for this task. Once all records have been inserted into the temp table, an Update statement is performed on the destination table reading from the temp table linking to either the surrogate key or unique columns.
For example, the statement will look like;
Update <Destination Table>From <Temp Table>Where <Destination Table>. Surogate Key = < Temp Table> . Surrogate Key
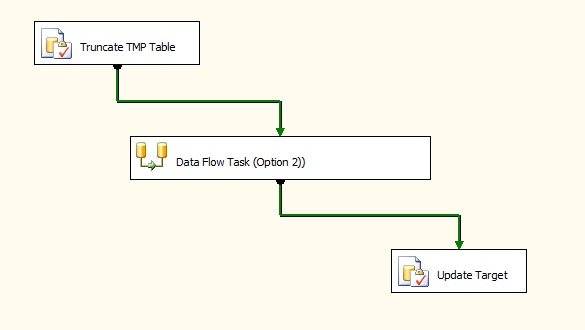
The image below is showing the required changes. The first SQL statement is being used to truncate the temp table before executing the data flow while the Update Target SQL taskis used to execute the UPDATE statement.
Results
The table below details the results I obtained on performing the mentioned changes to the package. The source has been limited to 1 million rows, enough to get a fairly accurate representation of the real world performance.
| Option Name | Processing Time | % Faster | Changes required | |
| 1 | Current Setup | 12 mins | 0% | None |
| 2 | Option 1 (Multiple (3) concurrent Updates) | 4.54 mins | 62.17% | Moderate |
| 3 | Option 1 (Multiple (6) concurrent Updates) | 3.15 mins | 73.75% | Moderate + |
| 4 | Option 2 (INSERT then UPDATE) | 2.25 mins | 81% | Most |
Option 1 is the current setup and is the slowest. No development changes are needed if the performamce is satisfactory or the number of updates on the destination table is very low.
Options 2 & 3 do involve some development changes. Both are faster than Option 1, and both options will take approximately the same effort, (option 3 slightly more). No major changes are required and therefore less UAT time will be spent to confirm and check the changes.
Note: An observation regarding options 2 & 3: increasing the number of threads will not continue increasing the executions/min simply because eventually the server's IO limit will be reached and no further increase will be possible. It must be emphasised that this option demostrates that a simple modification will aid in performance, however the ultimate improvement will be achieved through option 4.
Option 4 is the fastest however it will involve the most changes to the package.
Conclusion
As can be noted above, more than one solution can exist to speed up these kind of packages, the ultimate deciding factors being performamce vs developement effort. From a business point of view, option 4 may be the way-to-go but this involves the most changes and might not be feasible to implement due to time/HR constraints. On the other hand, if this package is part of an ETL process and the acceptable processing time window is being breached, then option 4 may be the way to go since it provides the best timings.

