

In the early T-SQL days, finding overlapping dates in a table required the use of a user-defined-function or looping through SQL cursors. Both were slow and expensive processes, especially on large tables. Thankfully, we now have Common Table Expressions (CTE) and Ranking Functions, both of which are great tools that give us more flexibility in applying problems like this one and turning it into a set operation solution more easily. Almost always, a set operation solution will provide a faster query time than its non-set operation counterpart.
Lets examine how we can utilize these tools to solve the problem of finding overlapping dates with this sample table:
create table Schedules ( ScheduleID int identity(1,1) not null ,PersonID int ,startDate datetime ,durationDays int ,constraint [PK_Schedules] primary key clustered ( ScheduleID asc ) ) insert into Schedules (PersonID, startDate, durationDays) select 1, '10/17/2010', 45 union all select 1, '09/07/2010', 40 union all select 1, '12/01/2010', 30 union all select 2, '09/01/2010', 12 union all select 2, '09/08/2010', 15 union all select 3, '10/01/2010', 20 union all select 3, '11/16/2010', 30 union all select 3, '11/01/2010', 15 select * from Schedules
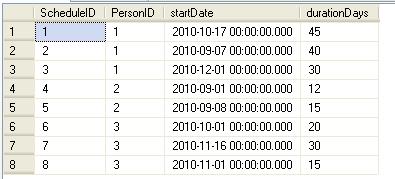
The durationsDays column is the amount of days we need to add to the startDate to determine the end date. Since this could be a large transactional schedule table, we need to be able to find anyone that could have overlapping time periods. And if there are no overlapping time periods, determine if the time period is either contiguous or a gap between the schedules.
First, we need to establish an order for the start dates. In this example, we have to clean the data because the sort order isn't correct on the stored table. Good practice suggests that you should always sort your sets because you can never trust that your data is 100% the way you expected unless you explicitly define that order.
We want to sort on the startDate in ascending order, partitioned by PersonID using the ROW_NUMBER() ranking function. The SQL looks something like this:
select ScheduleID ,PersonID ,startDate ,durationDays ,row = ROW_NUMBER() over (partition by personid order by startdate) from Schedules
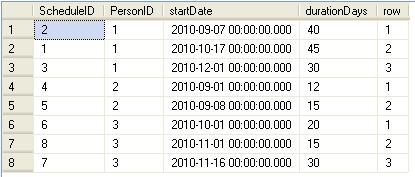
With the table now ordered correctly by startDate, we want to be able to "look ahead" from the first ordered startdate of each person. How do we do this? Wouldn't it be nice if we could somehow instruct the query engine to peek ahead at the next row? Well, we can!
;with
scheduleRanked as (
select ScheduleID
,PersonID
,startDate
,durationDays
,row = ROW_NUMBER() over (partition by personid order by startdate)
from Schedules
)
select sr1.ScheduleID, sr1.PersonID, sr1.startDate, sr1.durationDays ,sr1.row
,row2startDate = sr2.startDate
from scheduleRanked sr1
inner join scheduleRanked sr2 on sr2.PersonID = sr1.PersonID
and sr2.row - 1 = sr1.row
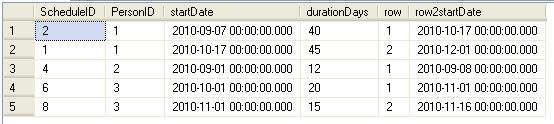
What did we do? We effectively aliased the table such that we could join onto itself but with logic of joining the row index from the first set against the row index subtract one from the second set. The reason we subtract one is because we want to be able to "pull up" the next row from our "current" row so that we can apply a test to both rows in one shot.
A good way to think about this is to treat this as two identical tables. For each PersonID partitioned, we remove the first row on the second table so that we can compare the second row instead. In essence, this allows us to offset the row index by one in the second identical table. Here's a better picture showing this:
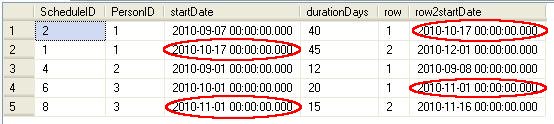
The red eclipses show that the row2startdate is always the same value as the next row's startdate that is within that partitioned set. Note that for PersonID 2, we are just seeing one row because we have already "pulled up" the next row.
To find the answer to our question is now easy. Once we "pull up" the next row into the same row space as our current row, we can apply the DATEDDIFF to determine the date offset. It's basic date arithmetic from here on out.
;with
scheduleRanked as (
select ScheduleID
,PersonID
,startDate
,durationDays
,row = ROW_NUMBER() over (partition by personid order by startdate)
from schedules
)
,scheduleCalc as (
select sr1.ScheduleID, sr1.PersonID, sr1.startDate, sr1.durationDays ,sr1.row
,row2startDate = sr2.startDate
,calculatedEndDate = DATEADD(day, sr1.durationDays, sr1.startDate)
,datedifference = DATEDIFF(day, sr2.startDate, DATEADD(day, sr1.durationDays, sr1.startDate))
from scheduleRanked sr1
inner join scheduleRanked sr2 on sr2.PersonID = sr1.PersonID
and sr2.row - 1 = sr1.row
)
select *
, case when datedifference = 0 then 'contiguous'
when datedifference > 0 then CONVERT(varchar, datedifference) + ' days overlapped'
else CONVERT(varchar, abs(datedifference)) + ' days gap'
end as analysis
from scheduleCalc

We learned two things. One, how to very quickly find dates overlapping (or gaps) in a large table. But perhaps, more importantly, we learned that you can apply this principle of comparing rowsets within any partitioned set in a single table. This is essential if you need to run comparisons on rows against other rows within a specified partition.
More information about ranking functions and partitioned sets can be found in BOL or at http://msdn.microsoft.com/en-us/library/ms189798.aspx
