

If you are working with ADF (Azure Data Factory) data flows, then you may have noticed there was a new feature released in November 2020, which is useful to capture any error while inserting/updating the records in a SQL database. This article will describe how to setup the error row handling feature and why it's important to set up this feature. This feature is shown below in the sink database.
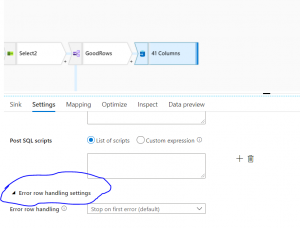
Fig 1: Error row handling at sink database
For error handling there are two options to choose from:
- Stop on first error (default)
- Continue on error
These options are shown below in the drop down.
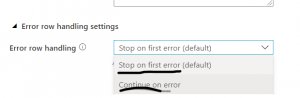
Fig 2: Error row handling options
By default, ADF pipeline will stop at the first error. However, the main purpose of this feature is to use the Continue on error option to catch and log the error so that we can look at later and take action accordingly.
Let's change the settings to catch errors. The below figures show the settings and will also describe each item. Please follow the numbering of each item in Fig 3.
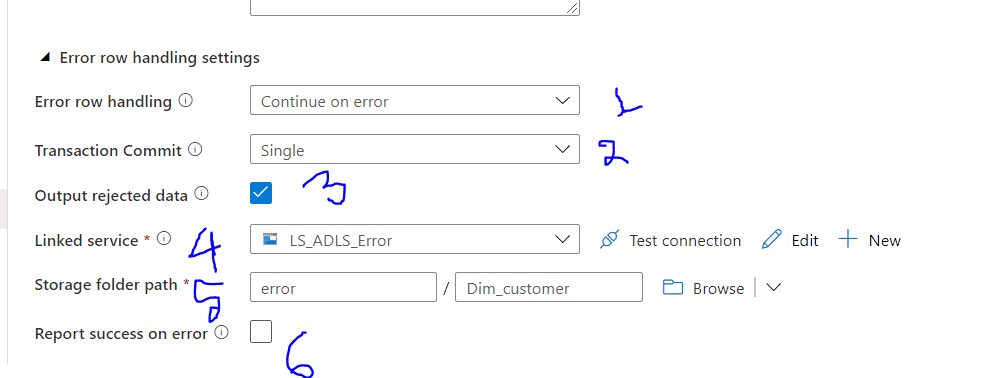
Fig 3: Settings Continue on error1) Error row handling: Since we wanted to catch errors, we have chosen "Continue on error".
2) Transaction Commit: Choose whether the data flow will be written in a single transaction or in batches. I have chosen single, which means whenever there is failure, it will store the record that failed. Batch will store the error records when the full batch is completed.
3) Output rejected data: You need to check this box to store the error rows. The whole point of error row handling is you want to know the error records. If so, please tick check mark. Though you can avoid this, if there are any errors, you will not know which record(s) caused the error.
4) Linked Service: Put the linked service and test the connection
5) Storage folder path: This is the path where you would like to store the error records from a file.
6) Report success on error: I don't select this checkbox, since I want to know if there is a failure.
After changing the settings, when you run the pipeline and there is any error in the dataset, it will be stored in the storage folder you have provided at no 5 in the settings.