

How many times has a user told you that they entered a contact into your CRM system, and now they cannot locate it by name? Then, after you help them locate it by some other means, it turns out that either the original entry or the search term was misspelled? Would you like your search to be able to suggest alternates when a key word is misspelled?
When "fuzzy" string matching is most helpful
Whether it's misheard, mistyped, poorly scanned, or copied and pasted from a bad source, misspelled information is a common irritant to the user. If a user can't find the record they're looking for quickly, they will probably enter it again. If it's your job to merge the duplicates, then it's to your advantage to provide your users with a "fuzzy" search option. It may take a few seconds longer, so don't make it your default search. Just give your users the option, and they will learn to try it when their first search doesn't find what they're looking for. If they start entering a new record anyway, you can also launch a background process right after the user fills in the key field(s), which can alert them to potential duplicates before they are ready to hit the save button.
When a Transact-SQL-only solution is needed
Although Fuzzy-String Matching is built into SSIS to assist with bulk imports, that doesn't help your front-end application user. You may also be prevented from using an extended stored procedure to execute code outside of SQL Server, or you may need a solution that works in SQL Server 2000, or SQL Server Express. If you have ever struggled with this, and would like a Transact-SQL solution that is simple to use, with acceptable performance, read on! You get to take advantage of the effort I have put into this, both at client sites and on my public demonstration site.
I originally needed this for a client whose key field is the Vehicle Identification Number, which is a 17-character combination of letters and numbers. For example, my car's VIN is 4S3BH675017600337, so you can see why VINs are notoriously easy to misread and mistype. Therefore, they desperately needed a way to stop typos from becoming duplicates in their database.
Fuzzy searching is also useful when looking up names, phone numbers and zip codes. You can probably think of another application unique to your business.
Damerau-Levenshtein Distance (DLD)
Nowadays, Levenshtein Distance is a top result of a search for string (similarity or difference) algorithm on Google. Years ago, it wasn't quite that straightforward, but I still learned fairly quickly that Levenshtein Distance is the basic string metric. It measures how many characters must be added, removed, or changed, to transform one string into another. On Wikipedia, I found the pseudo-code for the algorithm to calculate LD, and the Damerau extension, which treats the transposition of adjacent characters (e.g. "wlak" vs. "walk") as one typo instead of two.
Caveat: This implementation of DLD is "restricted" or "direct," allowing each substring to be modified only once. That means it does not recognize that "TO" can be changed to "OST" by a transpose, then an insert between. However, the goal here is to find unintentional errors, and such combinations of changes are unlikely to be accidental.
The Damerau-Levenshtein algorithm also does not recognize varieties of abbreviations, verb tenses, and so on. The welcome page at my site http://fuzzy-string.com/ gives further examples of what it does and does not do.
If you are anxious to try it right away
You can just skip down to "How to use the SQL scripts," because you can certainly use DLD without knowing how it works! I considered publishing this article in parts, but I suspect some readers will want the theory first, while some will want the practice first (I know I would want to flip back and forth).
How the algorithm works
The "edit distance" number which results from a Levenshtein comparison is arrived at by walking through a matrix. There is a row for each character in the first string, and there is a column for each character in the second string. The cells are filled in by comparing the corresponding characters. When comparing "twice" to "thrice" it looks like this:

You can use my site http://fuzzy-string.com/Compare/ to show the matrix comparing any two strings (up to 100 letters each, although the SQL code presented here allows for 253).
Visually follow the simplest path of Changes from top-left to bottom-right in bold.
Each cell displays the cumulative number of Changes required to arrive there, and what type of Change is required to arrive there from the previous cell, as follows:
- Equality (e): Move diagonally down right, because there is no Change (the letters from String1 and String2 match).
- Substitute (s): Move diagonally down right, by replacing the letter from String1 with the different letter from String2.
- Delete (d): Move down from the previous row, by removing the letter from String1.
- Insert (i): Move right from the previous column, by adding the letter from String2.
- Transpose (t): Move diagonally down and right twice as one Change, by swapping the letter from String1 with the next one.
Calculation of Changes starts from the top-left cell.
To produce the numbers in each cell, the first (0th) row and column are initialized with the positions of the letters in the strings. For each cell after that, the number of Changes required to arrive there is calculated as the minimum of:
- Equality (e): The Changes from the cell diagonally above left (if the letters from String1 and String2 match).
- Substitute (s): The Changes from the cell diagonally above left, plus one (if the letters from String1 and String2 are different).
- Delete (d): The Changes from the cell above, plus one.
- Insert (i): The Changes from the cell to the left, plus one.
- Transpose (t): The Changes from the cell diagonally above left twice, plus one (if the current letters are swapped with the cell above left).
Upon arrival at the bottom-right cell, the total number of Changes is known.
If that number is all you are interested in, such as in the WHERE clause of a search, you can stop calculation. However, if you want to markup the search results to highlight the differences from the search term, then you need to proceed to determine the simplest path, so you know which operations were done to which letters. That path is determined by working backwards from bottom-right to top-left, following the direction of the minimum Change in each cell. (If the top or left edge is reached before the top-left cell, then the type of Change in the remaining cells is overwritten, with Inserts or Deletes respectively.)
Performance Considerations
Obviously I was not the first to need to implement this, so when I searched for "Levenshtein SQL" I found worthy efforts (listed at http://fuzzy-string.com/Reference/ on my site) but I also found much discussion of performance issues. Therefore, I decided to make a fresh start, to incorporate some of the potential improvements suggested from the wikipedia pages, which I will discuss below (and which are commented in the SQL code).
Limiting the Changes
The most important performance improvement comes from realizing that your user doesn't care what the "edit distance" is between what they typed and every record in the table. They only want to see the records which are "close" to what they typed. So you start with a small "change limit" or "threshold," so that:
- You can stop filling in the matrix, when the number in any cell on the diagonal ending at bottom-right (silver in the picture) is larger than the threshold. Consider that the best case is that the remainders of the strings are identical, with "Equality" operations all the way down that diagonal, adding zero cost. If you already have too many changes, then there is no hope, so just quit.
- You need not fill in the whole matrix, only the cells that are not too far away from that diagonal. If the strings are different lengths, then the calculated cells must also be within the threshold of the diagonal starting at top-left (white in the picture). Consider that if the optimal path goes outside that stripe, you have performed too many operations to get back to the silver diagonal without exceeding the threshold. Basically, you avoid comparing the letters from the beginning of one word to the letters at the end of the other, because it would take too many operations to move them that far.
- You need not even call the comparison code on records where the length of the key field is too different from what the user typed. By not considering these comparisons for DLD, you avoid the cases where the silver and white diagonals are further apart than the threshold. That is, there is no way to get from the top-left to the bottom-right without more operations that you are allowing, so don't even try.
Searching is quicker with a smaller threshold, so start with 1 or 2. Then let the user expand the threshold by 1 or 2 at a time, until the search gets too slow, or returns too many results. You should also stop before the threshold reaches the length of the string they are looking for, because then you would be allowing every letter to change. My site http://fuzzy-string.com/Search/ lets you try out this process against the dictionary.
Below is the comparison of "twice" to "thrice" with a threshold of 2, which is the minimum "change limit" that will let the comparison complete, since there are 2 differences. Note that on each row, only the cells within 2 of both the white and silver diagonals are filled in.
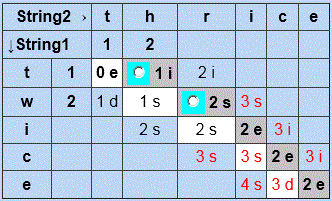
Below is the same comparison with a threshold of 1, which prevents the comparison from completing. Note that it stops on the first cell of the silver diagonal ending at bottom-right which exceeds the threshold.
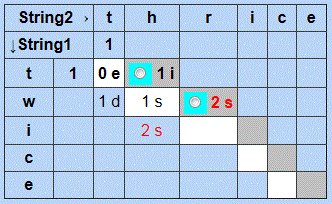
Note also that one cell on the row below the stopping point is filled in, because this visual matrix is generated with a table-based version of the algorithm, which calculates all the cells in a diagonal (perpendicular to the silver and white diagonals) at once. The faster string-based version of the algorithm will not calculate that cell.
For more information, see http://www.cs.uta.fi/~helmu/pubs/psc02.pdf which helped me understand the importance of the diagonals. (If you understand more of it than I did, you'll probably improve upon my code!)
Optimizing how UDFs are used
This implementation of DLD uses a multi-statement Scalar UDF (User-Defined Function), with an outer loop over the characters of the first string, and an inner loop across the characters of the second string. Note that I did put some thought into achieving the nirvana of an Inline Table-Valued UDF using a Recursive CTE (Common Table Expression) with zero logical reads, but I was not able to do it. Readers interested in that challenge are welcome to start with my code. Of course, such a solution would not be compatible with SQL 2000, which was important to some of my clients.
- To get the best possible performance, even though I call a multi-statement Scalar UDF [udfDamerauLevenshteinLim] in the WHERE clause (on every record with a close enough key field length), I don't make things worse by doing any table manipulation inside it, or by calling any nested UDFs.
- The first step in each comparison is to initialize the "0th" row with the position of each letter in the second string as the starting cost. Since the string you are searching for is the same when comparing each record, make it the second string, so that initial row is the same for each comparison. I created multi-statement Scalar UDF [udfDamerauLevenshteinRow0] which is called once before the search query, so the result can be passed to each call of the WHERE clause UDF.
- I created a separate multi-statement Scalar UDF [udfDamerauLevenshteinOpHTML] for use in the SELECT clause, to highlight the differences between what the user typed and what was found. First it recalculates the matrix, while saving the operation types for all the rows. Then it walks backwards through the matrix, marking up the found string with HTML corresponding to the optimal Change path. This version uses a local table variable, but still calls no nested UDFs. It also uses the same pre-calculated Row0.
- Finally, optional multi-statement Table-Valued UDF [udfDamerauLevenshteinOp] is only used to display one comparison matrix when requested. It returns much more information for each cell, using nested UDF calls and local table variables, because its performance is not as critical.
Datatypes and Collation matter
To avoid table manipulation in the UDF used in the WHERE clause, and to effectively mimic a matrix with a variable number of columns, each row of cost numbers is stored as TINYINT ASCII values in a VARCHAR string. The input string length is limited to 253, because the highest number that might need to be stored or compared is two more than the length. (If you need to consider longer strings, you will have to store SMALLINT numbers as UNICODE values in an NVARCHAR string.)
On the other hand, since INT is the native datatype for integer calculation in SQL, INT is used for all parameters, variables and columns used for looping, even if the value would never exceed the 255 limit of TINYINT. (Therefore, these will not need to be changed in order to consider longer strings.)
Since SUBSTRING treats the first character as position 1, and the 0th column in each row is always simply the position of that row in the first string, it is not stored. Also, since the algorithm walks through the matrix in a linear fashion, each cell is appended to the row as it is calculated, instead of initializing all the cells, and then replacing them. Finally, since the algorithm for calculating the number in each cell only needs to look back two rows (to check for transposition of two letters), only three rows are kept in memory. These are significant improvements over implementations that keep the entire matrix in memory as one long string, including the 0th column, in which the cells are initialized and then updated.
To support globalization, the strings and letters are defined as NVARCHAR and NCHAR. Every column is defined with COLLATE DATABASE_DEFAULT to ensure that if you change the default collation of your database, the new collation is used automatically, without having to recompile. Of course, variables always use the current database default collation, so I have commented every line with "Latin1_General_CS_AS_KS_WS" where collation is important. Note that the collation of the search key column in your base table is ignored when it is passed to the UDFs. Therefore, do not expect case-sensitive comparison, just because your search key column is defined with a case-sensitive collation. If your database default is case-insensitive as usual, then you will need to specify the case-sensitive collation on all the indicated lines, which will reduce performance slightly (about 10%).
Note that this algorithm only compares one character at a time, so Unicode Canonical Equivalence has no effect. (That is, combinations of letter characters with accent characters are not treated as equivalent to the single-character accented letters.) Also, the only comparison is equality or inequality, so it does not matter whether upper-case sorts before or after lower-case, just whether it is considered equivalent.
An alternative to specifying collation
At sites where they would always use a binary collation for complete case and accent sensitivity, performance can be slightly improved (about 10%) by:
- Defining the letter variables as SMALLINT instead of NCHAR
- Assigning the letter variables to UNICODE() of the letter, instead of the letter itself
- Then the comparison of letters is just integer equality or inequality, so collation does not apply.
That approach also helps when the search key column (as in the example of VINs like 4S3BH675017600337) is always one case, with no accents, so it doesn't matter if the comparison is case and accent sensitive or not.
The tradeoff is that the behavior of the code becomes less clear, when what seems like it should be a string comparison is not affected by collation. However, it can make sense if the strings you are comparing are actually tokenized sequences of integers. (For instance, to compare documents to detect plagiarism, you could convert words into integers, and use DLD to detect similar word patterns.)
Combining SETs into SELECTs
To optimize the actual calculations done in the loops, I take advantage of the fact that Transact-SQL allows combining multiple SETs of variables into one SELECT. Most importantly, it does the calculations in the order they are listed, so dependent SETs can still be combined.
In particular, the most time taken in the calculation is at the start of the inner loop, in which:
- The letter from the second string is retrieved.
- The cost from the same position in the previous row is retrieved.
- A "change" flag is set, according to whether the letter just retrieved matches the letter from the first string.
- That flag just calculated is used in another calculation.
Combining those steps into one select, in that order, improved performance without changing the result:
SELECT @thisChr2 = SUBSTRING (@Str2, @Pos2, 1) -- letter retrieval = 50% , @aboveVal = ASCII (SUBSTRING (@prevCosts, @Pos2, 1)) +1 -- cost retrieval = 40% , @thisChg = CASE @thisChr2 WHEN @thisChr1 -- COLLATE matters here THEN 0 ELSE 1 END -- letter comparison = 50% , @thisVal = @diagVal + @thisChg -- calculation = 10%
The percentage comments indicate the relative time taken by each SET when they were separate. Combining them reduced the total time taken slightly (about 10%). Quick plug: I have used and loved Confio Ignite at client sites, so I actually bought it for my own site to verify my performance theories. It produces graphs showing the performance of individual SQL statements over time, like this:
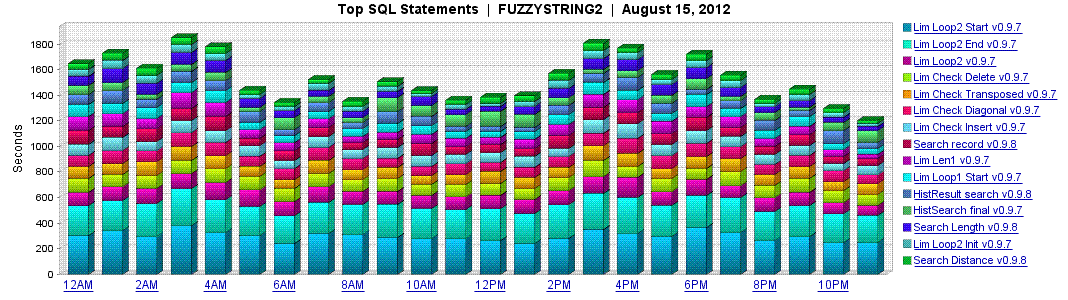
Comments like "--Ignite=" are included in my code, to make it easy to name the individual SQL statements in the graph.
Approaching the search in phases
To make sure the WHERE clause UDF is never called when the string lengths are too different, put the results of the length comparison (phase one) into a table variable. Similarly, to make sure the HTML markup UDF is never called when the strings are too different, put the results of the DLD comparison (phase two) into another table variable. The third phase is the SELECT to the client, calling the HTML markup UDF, and joining back to the base table to get any other desired columns.
This approach of separating the search into phases also allows for separate timing of each phase. The timing is shown at the bottom of each search results page on my site, and http://fuzzy-string.com/Search/Statistics.aspx provides overall statistics. Choose any recent version, and you will notice that the speed of the search is very sensitive to increasing the Change Limit. I have not worked out a mathematical formula for it, but search time increases as roughly the square of a Change Limit increase:
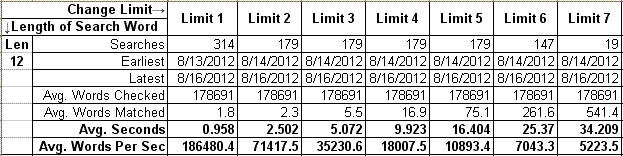
On the other hand, you will notice that the speed of the search is not very sensitive to increasing the Length of the Search Word. In fact, it is slowest in the middle lengths. If you choose just Phase 2 (DLD) statistics, you can see why that is. Since there are more words in the dictionary with middle lengths, there are more words that make it past the Phase 1 length check. When DLD is required to compare a higher percentage of records, it will comprise a higher percentage of the search time:
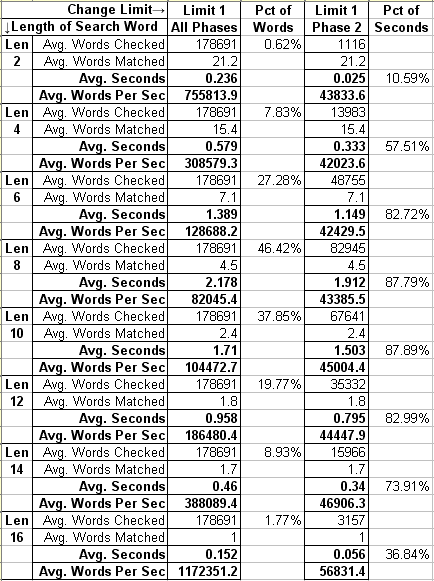
Why is this important? Because it will certainly make sense to your users that the fuzzy-string search is much slower when allowing for more typos, and also that it is somewhat slower when there are many similar records to check. But fuzzy-string searching would not be useful to them if it were slower to find longer strings, just because they were longer.
Index and other Hints
Of course, you should have an index on the column you want to search, which can be (but does not have to be) a unique or primary key constraint. If you have an index that combines it with other columns, the column you want to search on should generally be first in the list. Since the first phase is a query on the length of the column, rather than on the string in the column, it will need to scan that index, but at least it won't have to fetch any row data.
Of course, if you have control of the schema, and you need every last ounce of performance, I would recommend creating an indexed computed column for the length of the string. Then you can query that column, with that index, as Phase 1. (I could certainly have done that in my site, but I wanted to show that performance is acceptable without doing that.)
This is somewhat controversial, but I've learned to specify WITH (INDEX (name)) hints in queries on substantial tables, when only one index is a reasonable choice. (There is less dependency on statistics that way. Also, using index hints makes you think about indexes, so you can take better advantage of them.) Therefore, in the first phase, specify the index that starts with the search key column. In the last phase, when joining back to the base table on the primary/unique key, specify the name of that constraint. (You can just remove these hints if they make you uncomfortable.)
Depending on the issues you typically encounter in your system, "your mileage may vary." Using table variables for staging is subject to the usual caveats regarding parallelism, because of the caching of temporary objects and the plans that depend on them. My site is built on a fairly vanilla SQL installation, but I have successfully implemented DLD in more issue-prone installations as well, so I can probably help if you experience issues.
Error-checking is in the PRC, not the UDF
To increase performance in the UDF that is called on every row in the WHERE clause, it does not validate its parameters. Therefore, please do not call it except as shown in the example Stored Procedure (PRC) provided, which does validate its parameters before starting the search. (The markup UDF used in the SELECT clause does validate its parameters, so it can be called in other contexts, as described below.)
How to use the SQL scripts
The Resources section at the end of this article includes two separate SQL scripts, to create my objects in your database:
- "scrDamerauLevenshteinLim.sql" creates the three UDFs that you need to run a Damerau-Levenshtein distance (DLD) search, plus one example PRC that shows you how to validate input and call the UDFs.
- "scrDamerauLevenshteinOpTbl.sql" creates the optional objects (one table, two UDFs, and one PRC) that you can use to visually illustrate DLD comparison, as my site does.
At the beginning of each script is a list of the replacements that you need to make, in order to compile and use the objects in your database:
- I use [usr] as the schema name, to separate my objects from the [dbo] schema. You can replace it with [dbo] or whatever schema or username you want the objects within.
- I use [webrole] as the security principal which is allowed to execute the procedures. Then I just add users to that role. You can replace it with [public] or whatever security principal you have that will run the PRCs. (No permission is needed on the UDFs, if they are only called via PRC.)
- My example PRC searches on my base table, so you need to change all the identifiers and types to match the table you want to search on. You can also return additional columns from your table as desired.
- If you want these objects to use a collation other than the current database default, you will need to modify the collation in several column definitions, and uncomment the collation in several variable comparisons. (All the important lines have comments including "Latin1_General_CS_AS_KS_WS".)
- In the optional script, if you already have a sequence table, you can remove the creation and population of [usr].[tblNumbers], then replace references to it with yours.
To just play with it, without much effort
If you don't want to create my objects in your database at first, the Resources section at the end of this article includes a third "scrDamerauLevenshteinNewDB.sql" script, which you can use to create a test database to play with. Execute it with Results to Text (to review recordset and PRINT output together).
- First, it creates a database, role, login, user, and base table. (If you run the complete script, all these will be dropped. Otherwise you should change the password of the login, or disable it.) You may change the default collation of the database.
- Next, both of the scripts above are included, to create all my objects in that new database.
- The base table is populated with a few rows, and you can add more rows if you like.
- Then it shows you how to exercise my objects, by running a search in the base table, and displaying a comparison of two strings. The output will be different based on the case-sensitivity of the database's default collation.
- Finally, all my objects are dropped, including the database and the login. (Delete this section before running the script, if you want to keep the database around to play with, and you changed the login's password or disabled it.)
To run a search in the base table, just specify the string you are looking for, and the allowable number of differences:
EXEC [usr].[prcDamerauLevenshteinSearch] N'_LookupString', 3 id Matched Changes Differences -- ----------------- -------- ----------------------------------------------------------------------------------------------------- 3 PK_LookupString 2 <s>PK</s>_LookupString 14 UQ_LookupString 2 <s>UQ</s>_LookupString 7 tblLookupString 3 <s>tb</s><i>l</i>LookupString
The result set is sorted by the number of Changes (so closer matches are listed first). The "Differences" column is the "Matched" string, with HTML markup to highlight the changes required to transform it to the string you searched for (and with every character HTML-encoded to avoid any confusion with the markup).
The markup UDF uses deprecated single-character HTML tags to flag the operations, so it's possible that you're not using them for any other purpose in your site. Style should be used to highlight the markup for presentation. You can copy http://fuzzy-string.com/Style/Change.css if you like the way my site looks:
- Equality (e): no tag
- Substitute (s): <i> is used to tag the letter from Str1 that is replaced with a letter from Str2. It is styled with {font-weight: bold; color: green;} which adds to the italic slant.
- Delete (d): <s> is used to tag the letter from Str1 that is missing from Str2. It is styled with {font-weight: bold; color: red;} which adds to the strike-though.
- Insert (i): <b> is used to tag an underscore indicating the space in Str1 where a letter from Str2 goes. It is styled with {border: solid 1px;} which adds to the bold weight.
- Transpose (t): <u> is used to tag the pair of letters that are swapped. It is styled with {font-weight: bold; color: green;} which adds to the underline.
Visual comparison in a SQL Query window
To display a comparison without having a web front end like mine, just call [prcDamerauLevenshteinOpTbl] without the @asCells parameter, so it uses PRINT statements to approximate the same display (the PRC is included in scrDamerauLevenshteinNewDB.sql and scrDamerauLevenshteinOpTbl.sql). To compare "twice" to "thrice" with no Change Limit:
EXEC [usr].[prcDamerauLevenshteinOpTbl] 'twice', 'thrice'
Str2 t h r i c e
Str1 1 2 3 4 5 6
t 1 \ 0e* ~ 1i* 2i 3i 4i 5i
w 2 1d \ 1s ~ 2s* 3s 4s 5s
i 3 2d 2s \ 2s ~ 2e* 3i 4i
c 4 3d 3s 3s \ 3s ~ 2e* 3i
e 5 4d 4s 4s 4s \ 3d ~ 2e*The backslash prefix (\) is used to mark the diagonal starting at top-left. The tilde prefix (~) marks the diagonal ending at bottom-right. The asterisk suffix (*) marks the optimal path. If the comparison is stopped, an exclamation point suffix (!) marks the point (on the tilde diagonal) where the Change Limit was exceeded. To compare "twice" to "thrice" with a threshold of 1:
EXEC [usr].[prcDamerauLevenshteinOpTbl] 'twice', 'thrice', 1
Str2 t h r i c e
Str1 1
t 1 \ 0e* ~ 1i*
w 1d \ 1s ~ 2s!
i 2s
c
e Other uses for [udfDamerauLevenshteinOpHTML]
The UDF that marks up the result strings, to show how different they are from the search string, can be useful in many other contexts. You can pass NULL for all parameters, if you are not comparing one string to many. (If you pass NULL for either of the strings, it will be treated as an empty string.)
In audit trail displays, it can be used to show how items change from one event to the next. Below is an example from a client site (the markup style is different, but the concept is the same):
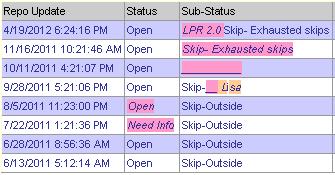
In displays of child objects that might have some inconsistencies from their parent objects, it can be used to highlight the differences. For example, if you used SSIS Fuzzy-String Matching to import some data from another system and link it to records in your system, you may want to visually flag the records that didn't match exactly. Below is an example, where one imported record has a mismatch on Account Number and Order Date, while the other has a mismatch on Year:
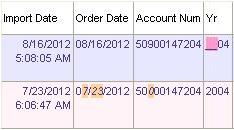
Conclusion
If you have a need for this in your system, please try it out! Based on the number of "Levenshtein SQL" discussions out there, I suspect many people do need this. Once there is some feedback here, I will post links to this article in those discussions. I look forward to feedback, positive and negative. It has been a labor of love to generalize and optimize this solution enough for publication, because I want to share the success I've had with it. It's come a long way already, but with more people testing and using, it can certainly be improved further!
Scripts updated 2012-09-21 from v1.0.0 to v1.1.0
Performance of [udfDamerauLevenshteinOpHTML] has been improved, by doing one less INSERT and one less SELECT on the table variable. (The values of @Pos1 and @theOps at the end of the first loop are proper to start the second loop, so they do not need to be saved and reloaded.) All other changes are only in comments. Also corrected google link above.
