

If you are working with Notebooks in Azure Synapse Analytics and multiple people are using the same Spark cluster at the same time then chances are high that you have seen any of these below errors:
"Livy Session has failed. Session state: error code: AVAILBLE_WORKSPACE_CAPACITY_EXCEEDED.You job requested 24 vcores . However, the workspace only has 2 vcores availble out of quota of 50 vcores for node size family [MemoryOptmized]."
"Failed to create Livy session for executing notebook. Error: Your pool's capacity (3200 vcores) exceeds your workspace's total vcore quota (50 vcores). Try reducing the pool capacity or increasing your workspace's vcore quota. HTTP status code: 400."
"InvalidHttpRequestToLivy: Your Spark job requested 56 vcores. However, the workspace has a 50 core limit. Try reducing the numbers of vcores requested or increasing your vcore quota. Quota can be increased using Azure Support request"
The below figure shows one of the errors while running a Synapse notebook:
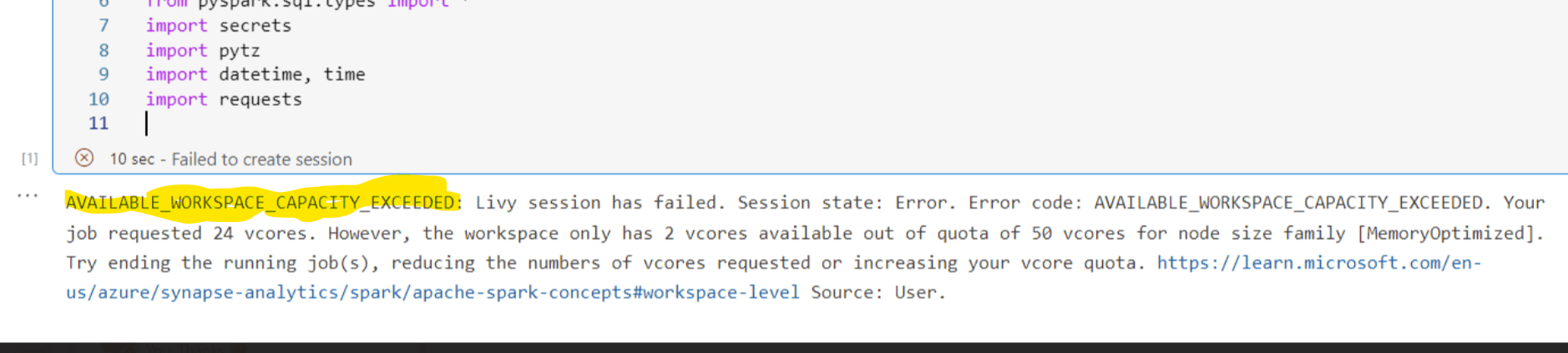
Fig 1: Error Available workspace exceed
What is Livy?
Your initial thought will likely be, "What exactly is this Livy session?"! Apache Livy is a service that enables easy interaction with a Spark cluster over a REST interface. Whenever we execute a notebook from Azure Synapse ,Analytics Livy helps interact with Spark engine.
Will increasing vCores fix this error?
After looking at the error message, you may attempt to increase the number of vCores to fix this. However, increasing the number of vCores will not solve your problem.
Let's look into how Spark pool works, by definition of Spark pool. When a Spark pool instantiated, it creates a Spark instance that processes the data. Spark instances are created when you connect to a Spark pool, create a session, and run a job. Multiple users may have access to a single Spark pool. When multiple users are running a job at the same time, then the first job might have already used most of the vCores so the next job executed by another user will receive the Livy session error.
The Solution
The problem occurs when multiple people work on same Spark pool or the same user is running more than one Synapse notebook in parallel. When multiple Data Engineers work on the same Spark pool in Synapse, they can configure the session and save into their DevOps branch. Let's look how to do this step by step.
You will find configuration button (a gear icon) under Azure Synapse notebook as shown in this figure:
Fig 2: configuration button
By clicking on the configuration button you will find details about Spark pool configuration details, as shown in the below image.
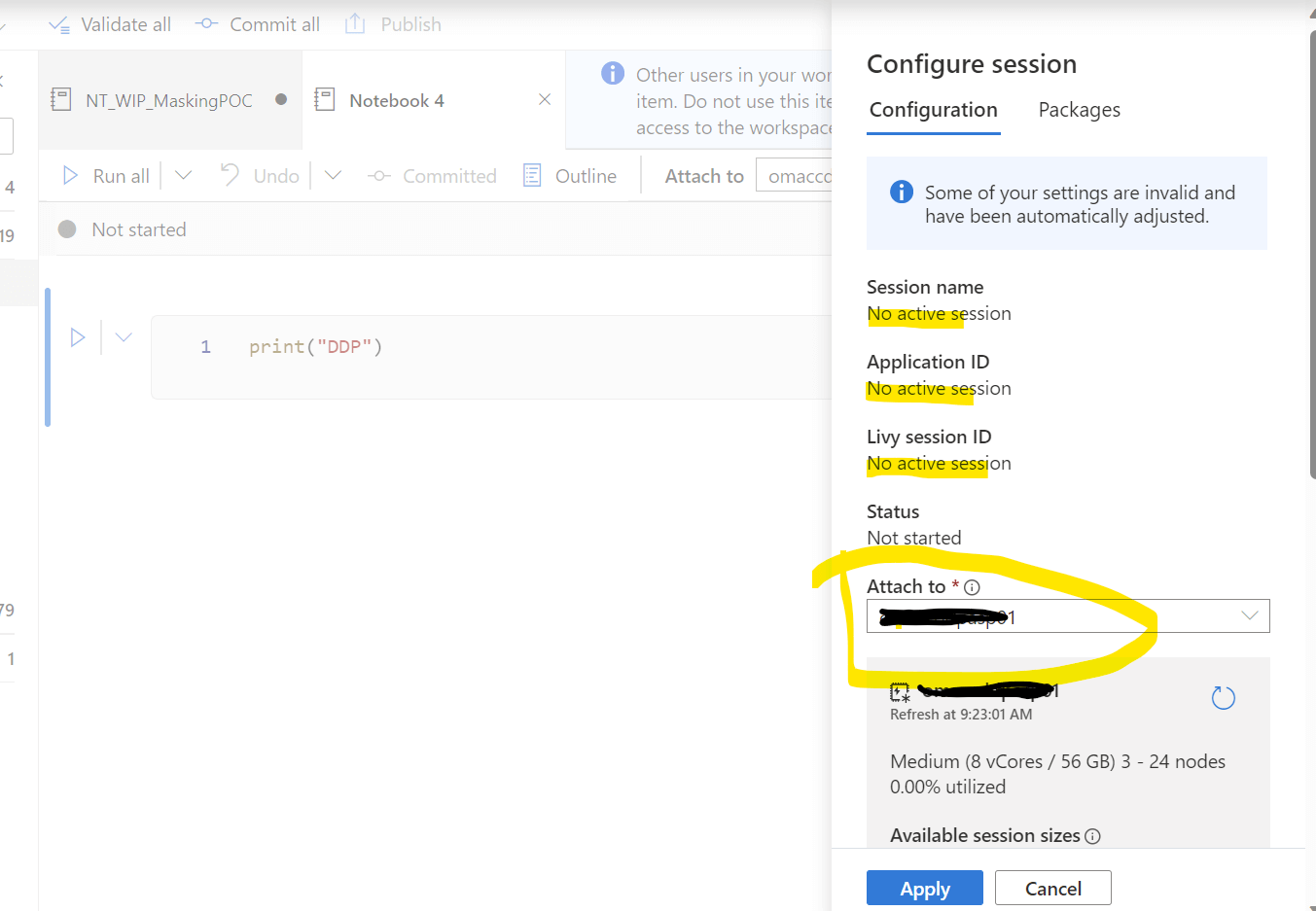
Fig 3: Session details
As you find in the above Fig 3 there is no active session since I did not start any session yet.
Activate your session by attaching the Spark pool and assigning the right resources. Please look at the below fig 4 and see the detailed steps to avoid the Livy session error.
In the image, for a) attach the Spark pool from available pools (if you have more than one). I only have one Spark pool.
For b) select the session size. I have chosen small by clicking the 'Use' button next to the line with Small.
Next, in c) enable Dynamically allocate executor, this will help Spark engine to allocate the executor dynamically.
For d) you can change the number of Executors. As an example, by default the small session size has 47 executors. However, I have chosen 3 to 18 executors to free up the rest for other users. Sometimes you may need to get down to 1 to 3 executors to avoid the errors.
In e) apply the changes to your session.
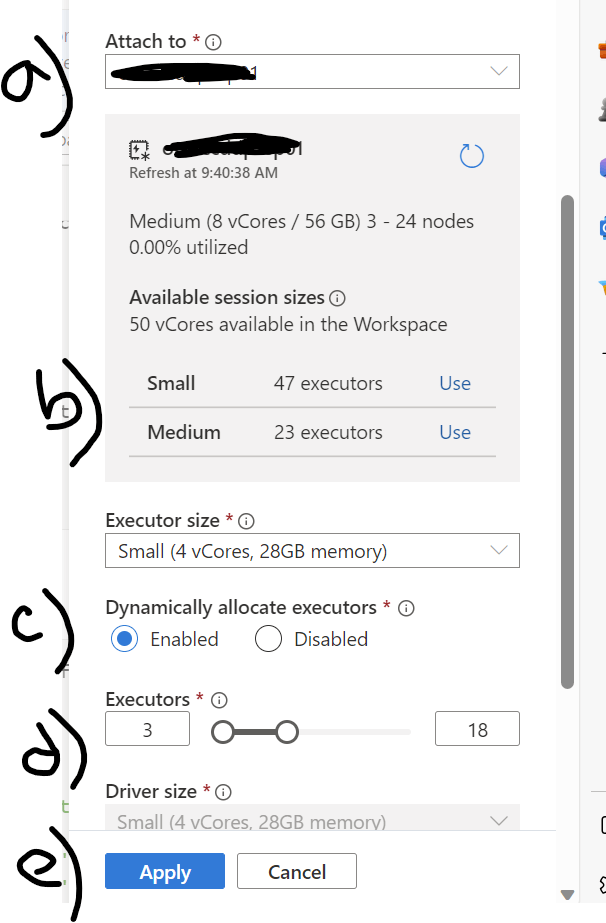
Fig 4: Fine-tune the Settings
And you can commit this changes to your DevOps branch for the particular notebook you are working on so that you don't need to apply the same settings again. In addition, since the maximum Synapse workspace's total vCores is 50, you can create a request to Microsoft to increase the vCores for your organization.
In summary, the Livy session error is a common error when multiple data engineers working in the same Spark pool. So it's important to understand how you can have your session setup correctly so that more than one session can be executed at the same time.