

Often we need to search for a string within another string. For cases where the match needs to be exact, we can use the LIKE operator with wildcards to specify a pattern. While this covers the requirement, it can be quite slow on larger data sets since it requires SQL Server to inspect each string while going through all rows. Indexing the character column which we are searching within can dramatically speed up the operation, however this technique has its limitations. This article examines the case where we are searching not only in the beginning or end of a string, but for a match anywhere within the string.
To illustrate the problem, let’s take as an example a very simple table with two columns:
CREATE TABLE dbo.String
(
StringId INT NOT NULL PRIMARY KEY IDENTITY(1, 1) ,
String VARCHAR(20) NOT NULL
);We can populate the table with a sample dataset of 5M rows, with exactly 20 characters in the String column and a sequential StringId. We will use this to test the performance of different queries.
To find the number of strings in the String column which begin with a character sequence of ‘abcd’, we can issue the following query:
SELECT COUNT(1) FROM dbo.String WHERE String LIKE 'abcd%';
It executes in ~14 seconds (all examples are run on a S2 SQL Azure instance).
To find the count of all strings which contain the ‘abcd’ sequence anywhere within them, we can write:
SELECT COUNT(1) FROM dbo.String WHERE String LIKE '%abcd%';
The execution time is the same. This is due to the fact that SQL Server has to do a full table scan and inspect each string for a match in either case.
A well-known technique to speed up the first query is to build an index on the String column of the table:
CREATE NONCLUSTERED INDEX ix_nc_test ON dbo.String (String);
After the index if built the query using the LIKE 'abcd%' predicate executes in ~1ms. However, the second query does not benefit from the index since the index is ordered from the first character to the last and the operation to find a matching string is similar to the one we saw previously. If the LIKE predicate was ‘%abcd’ and we wanted to search for strings ending with the ‘abcd’ characters, we could have used another optimization where we create a computed column on the reverse string and search for the reversed term. This is described here: Optimising “Ends With” searches with REVERSE
However, neither of these indexes help us with the original problem of finding the string if it appears anywhere in the strings in our table.
While this is a general problem, if we have a reasonably short limit on the string length, we could, at the expense of storage space and extra effort, cut the strings so that from a string like ‘abcdefgh’ we construct eight substrings and store them in another table in the following manner, along with their Ids:
abcdefgh
bcdefgh
cdefgh
defgh
efgh
fgh
gh
h
After we do this, we can index the column and perform a LIKE search with trailing wildcard. This would find the string which we search for if it appears anywhere in the stored string.
Of course, this means that for a string of length 3, we get 3 rows in our new table. And as the string length grows, so does the number of rows necessary to store it. Furthermore, the total number of characters (and thus, space) necessary to store the strings of length n becomes equal to n + (n-1) + (n-2) + … + 2 + 1, or (n*(n+1))/2 so for a string of length 100, this becomes 5050 characters, while for a string of length 20, the number of characters we have to store is 210. This in itself results in a much larger number of resources needed to process the query.
With longer strings the performance of the query using the expanded format might not justify the expense of these resources. Given other considerations such as the overall throughput of the system, it would be advisable to limit the application of this technique to strings such as emails, logins, short article titles and similar, which tend to be relatively short.
We can test the performance in our case with a StringSplit table populated with the data from the String table, where the strings are split as per the described technique (the StringId is the same for each substring):
CREATE TABLE dbo.StringsSplit
(
StringId INT NOT NULL ,
StringSplit VARCHAR(20) NOT NULL
);The row count in the table after the processing is done is 100M (or 20 times more than the original table). We create a clustered index on the StringSplit column:
CREATE CLUSTERED INDEX ix_c_test ON dbo.StringSplit (StringSplit);
Now we can test the following queries side by side:
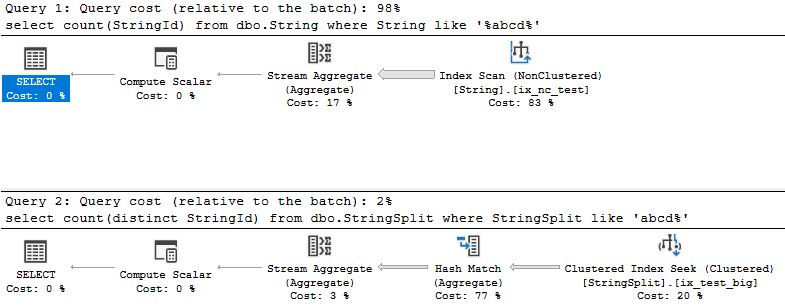
SELECT COUNT(StringId) FROM dbo.String WHERE String LIKE '%abcd%'; SELECT COUNT(DISTINCT StringId) FROM dbo.StringSplit WHERE StringSplit LIKE 'abcd%';
The first one completes in 14s, just like before, and the second one in 250ms. As expected, the query plans explain the difference quite well – we see a full index scan on the first one (because of the index we created to search in the beginning of the string) and a clustered index seek on the second.
While applying this might not applicable in all cases, this is how we managed to get the execution times of some search queries down to under a second from more than 10 seconds.


