

The perceived need for System-generated, single-value “Surrogate” Keys.
Data modelers commonly design databases wherein each table has a single primary key column whose value “has no business meaning”, but consists of a system-generated numeric value (aka “Surrogate Key”). The thinking is that a primary key value that has business meaning is subject to change, and to maintain database integrity any such change will necessitate “cascade updates” rippling through the database.
Say a table (Customer) has a primary key column custID that included values such as “ABC”, “XYZ”, etc., with a corresponding column custName with values “ABC Company”, “XYZ Inc”, etc. Say that there are 1000 rows in a table (SalesOrder) that has a foreign key column SalesOrder.custID relating to the Customer.custID primary key column. To maintain referential integrity, in case the Customer.custID primary key value changed, the relational database would need a Cascade Update rule on the relationship “Customer-SalesOrder”, so as to cascade the update of the foreign key value in all the matching SalesOrders records.
Many data modelers want to avoid this situation by using surrogate keys, in which case there would be no need for Cascade Update (although a Delete Rule of “Cascade” or “Restricted” is still required). Another benefit of using surrogate keys is simplicity: join statements are easier to construct.
Unfortunately, in using single-column surrogate primary keys database designers may be putting their databases at risk with respect to data quality (specifically database integrity). The reason is that using single-column surrogate keys blocks the relational database from enforcing database integrity “straight from the data model”: database designers must add extra unique indexes (or database application developers must add code) to maintain database integrity.
Data Quality problems arising from using Surrogate Keys.
Example 1. (Introduces risk of record duplication): Since surrogate keys are generated by the system, not coded by a user, it is possible for a user to unwittingly enter two rows in a table for the same record instance. Say an operator is entering new Customer records where the Customer table has a surrogate key. She just entered a new Customer record whose customer name is “ABC Company” and wants to stop for lunch. When she gets back to work, she sees the ABC record data sheet on her desk. Not remembering whether she entered this record or not, she decides to enter this record again (perhaps thinking the system would “stop her” if the new record is duplicated). If the custID column had not been a surrogate key, the database entity integrity rule requiring a unique primary key value would have prevented her duplicate entry of custID. But since a unique surrogate key is assigned to each record, she has in fact entered a duplicate record. Ergo an uncaught EI violation has occurred, and the database is no longer clean.
Example 2. (Loss of proper uniqueness in Intersection tables): A more common loss of database EI enforcement is the use of a single-column surrogate primary key for an intersection table (used to resolve a “many-to-many” relationship between two other tables). As an example, say we have a many-to-many relationship between a Physician table and a Specialty table. Each Physician may have a practice in more than one Specialty, and each Specialty may be practiced by more than one Physician. So an intersection table is created, called PhysicianSpecialty.
Most data modelers, wanting to have the database maintain Entity Integrity, would use an identifying relationship from each of the two tables, Physician and Specialty, to construct the primary key of the intersection table. So the primary key of PhysicianSpecialty would be the unique combination of physicianID and specialtyID. No user could enter the unique combination of these two values more than once. But using a single-column surrogate primary key, an uncaught EI violation could certainly occur unless the database designer creates a second Unique Index (on the combination of the two migrated foreign key columns), or unless the database application developers code for EI enforcement upon data entry.
The Alternative to Surrogate Keys – Using and Migrating Multi-Column Primary Key Columns
Many database designers prefer to design a database which can “protect itself” against unclean data, integrity violations and business rule violations. (Evidently database designers trust themselves more than application developers to try to protect the database). Database designers can protect their databases with models that use surrogate keys, and we’ll show how to do so while overcoming the types of problems discussed above. However, modeling and designing without single-value surrogate keys allows database integrity protection to be “baked into” the database itself. With such an approach, the model represents the database integrity rules visually, for all to see. Below are the features of a model created with an Entity Relationship Diagram (ERD) tool such as CA’s ErWin and Embarcadero ER/Studio.
Multi-Column Primary Key columns
As was discussed in Example 1 above, a surrogate primary key can allow “hidden duplicate records”. A non-surrogate primary key eliminates this problem. Also the primary key value is understandable to the user (custID is “ABC” rather than a randomly generated numeric value). In Example 2 above, an intersection table can, “by itself”, enforce a basic business rule of intersection tables that states: “only one instance is allowed for the combination of each of the two migrated foreign key values”. A multi-column primary key, consisting of the migrated foreign keys of the M-to-M related tables that are its “parent” tables, is all that is needed to enforce this business rule.
Migrated primary keys
Relationships are used to describe many policies and business rules of an organization. Referential Integrity (RI) of a database’s relationships is vital to the accuracy of a relational database. If the database designer is trained in data modeling to enforce RI through rules such as identifying relationships, he or she can design the database such that RI can be enforced by the data model itself.
Setting an identifying relationship migrates the “parent table” primary key column(s) to the related table as part of its primary key, thus creating a compound primary key consisting of multiple columns. Migrated primary keys can then be migrated again to other related tables, either as an identifying relationship (again part of a primary key) or a non-identifying relationship: foreign key column(s) that become non-key attributes. Migrated multi-column primary keys also enable an important feature of relational theory: Unification (Top-of-the-line Data Modeling tools like Embarcadero’s ER/Studio prompt the modeler when Unification / Non-Unification needs to be established, per migrated FK column.)
The Unification business rule
Unification allows common foreign key columns to be shared by two or more migrated primary key columns. Unification (and its reverse “non-Unification”) acts like an advanced Normal Form, because it in effect enforces RI between tables that aren’t directly related to each other.
Below is an example of Unification at work.
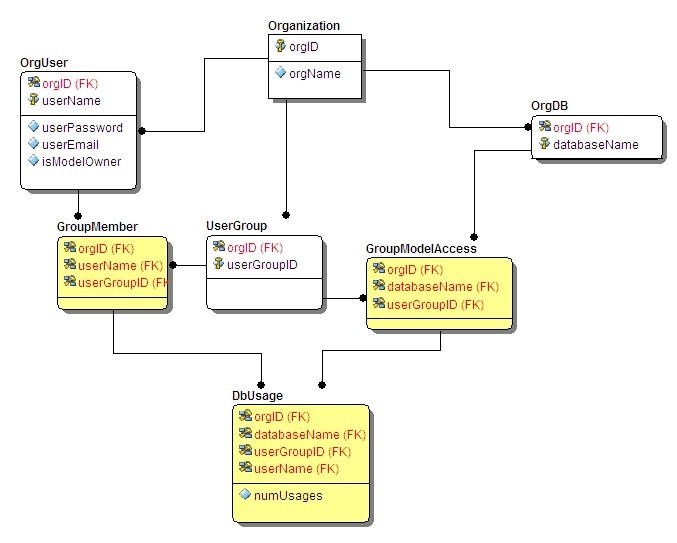
The data model in Figure 1 below models the interaction between users and databases, with business rules about which group of users can access which databases. This model allows a type of “multitenancy”, capturing similar information of several Organizations. Within each Organization, a key business rule is that only an Organization’s own Users (OrgUser) can access that Organization’s databases (OrgDB). Likewise each Organization has its own set of User Groups (UserGroup). Since the modeler created identifying relationships, the primary keys of these other three tables all include orgID, the migrated primary key of Organization. Intersection tables control which Users are members of which UserGroups, and which UserGroups have access to which Databases.
The other three tables in the model (shown in Yellow) show the effects of Unification. Note that the migrated primary key column orgID is shared (not duplicated) in these tables. Also, in the table DbUsage, the migrated key column userGroupID is unified (shared). This unification helps control data quality: there is no chance that the key business rule is ever violated.
Figure 1. Enforcement of database integrity and business rules through multi-column keys and unification.
So is it possible to enforce database integrity (both EI and RI) while still using single-column surrogate keys? The answer is yes, but data modelers and database designers need to know how this can be accomplished.
Enforcing database integrity when using Surrogate Keys.
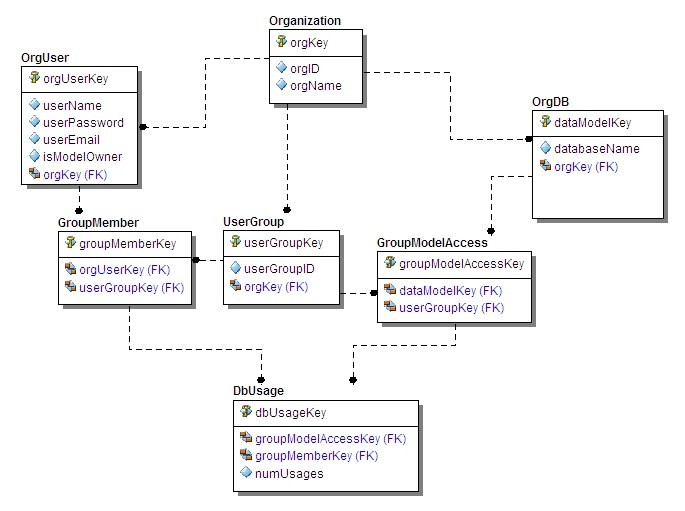
Below in Figure 2 is the same database as shown above, except that we’ve used single-column surrogate primary keys for all tables. When using single-column primary keys, there are no identifying relationships: all migrated primary key columns become foreign key columns that aren’t part of the primary key. So DbUsage, GroupMember and GroupModelAccess – tables that included shared key columns before, can no longer enforce Unification.
Figure 2. Using surrogate primary keys, database integrity and business rule enforcement is not depictable.
Now let’s enforce the same “multitenancy” business rules we had in the previous example: each Organization has its own set of Users (OrgUser), its own set of User Groups (UserGroup) and its own set of databases (OrgDB). Also, intersection table GroupMember will control which user belongs to which user group, and intersection table GroupModelAccess will control which User Groups may access which of the Organization’s databases.
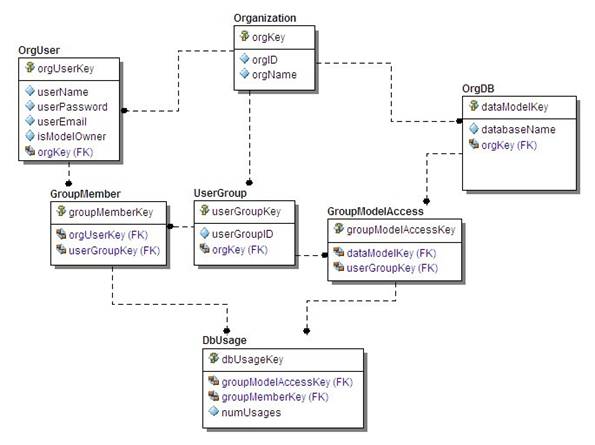
Business rule 1. Enforce the entity integrity rule on non-intersection tables (OrgUser, OrgDB and UserGroup): Each must have a unique index on two columns: the foreign key combined with the column(s) that would have been part of a non-surrogate primary key. The same OrgUser userName (say John Smith) may occur within different Organizations, so we can’t just set a Unique Index on userName; it must be for orgKey coupled with userName. Likewise, the same type of Unique Index rule must be used in OrgDB and UserGroup – coupling the foreign key column orgKey with databaseName and userGroupID, respectively.
Business rule 2. Enforce the entity integrity rule on intersection tables (GroupMember, GroupModelAccess and DbUsage): Each must have a unique index on the combination of the two migrated foreign key columns.
Note that for these two business rules above, we added an extra entity integrity rule; each table already had a unique index on the primary key (surrogate key). But by adding the extra entity integrity rule we have avoided the kinds of data anomalies and integrity rule violations described above in this paper.
Business rule 3. Unification.
Remember that in this data model a key business rule is that only an Organization’s own Users (OrgUser) can become a member of only UserGroups that can access that Organization’s databases (OrgDB): a rule that we enforced through unification in the non-surrogate key model. In the surrogate-key model, unification must be handled with some sort of user function or check constraint. Unfortunately there is no way to depict unification in IDEF1X or any other modeling notation. (If there were, it might be a relationship line with a special line-type, like “dot dash” below, showing that the OrgUser and OrgDB tables are unified on the same “orgKey” column value).
Figure 3. Depiction of unification with new “dot dash line” notation.
Summary
Data quality is crucial for the proper functioning of the organization: without it, executives and employees will start mistrusting the actionable information they receive through the organization’s B.I. tools. With, or especially without, an overall Master Data Management (MDM) initiative, 100% data quality is a core foundation of any organization.
Data quality is assured when the organization’s databases “by themselves” enforce clean, accurate data and also enforce the organization’s business rules. Instead, some organizations expect and rely on their application developers to ensure data quality. While it is to be expected that data entry validation and data update / deletion validation are built into all applications, each of the organization’s databases should be designed to protect itself in all cases.
Many data modelers today favor uniformly using single-column surrogate primary keys. Surrogate keys have many advantages, but in many databases there is a danger of losing database integrity enforcement unless proper safeguards are used, such as unique indexes on multi-column key columns.
Rather than prohibiting the use of surrogate keys, this author maintains that data quality and data-oriented business rules can, to a large extent, be verified while using surrogate keys, through the proper use of unique multi-column indexes. Even the important business rule of table unification can be enforced with surrogate keys, using user-defined functions and check constraints.
This author also strongly suggests that, since models of surrogate-key prevalent databases don’t visually represent all the database integrity rules, these databases should be “verified” by a Data Profiler tool to validate database integrity and business rule enforcement. While the article has described how to protect database integrity “by the database itself”, a perfect certification of database integrity and business rule enforcement may still require manual validation by database-savvy technologists if stored procedures or user functions are used in the database.
Marvin Elder
Author’s bio
Marvin Elder is a pioneer in end-user computing, having invented the world's first desktop database language with built-in Natural Language (Salvo, 1984).
Marvin also invented a PC-based Integrated CASE Tool in the 1990s (Inroads), which included an ad hoc query tool, Visual Query, a product that allowed users to construct ad hoc queries by 'pointing and clicking' on elements of a graphical data model.
Currently Marvin is founder and president of Real Time Answers LLC, an innovation company that is developing a product that allows users to create their own reports and graphs using a visual query tool, VC™. You can read more at www.realtimeanswers.com.
