

Purpose
With the release of ADO .NET Microsoft has fundamentally changed the way of database applications development. The new version of ADO introduced with .NET Framework is extremely flexible and gives developers a wide variety of tools for handling common database programming tasks. This comes with special regard to so called disconnected data structures, i.e. objects residing in memory that hold copy of data in the database. These structures allow developers to easily manipulate data in client applications (often referred to as “presentation layer”). This approach may be called a thick client as a vast part of data manipulation is performed on client side. Thanks to ADO .NET users can slice and dice data and make changes to it with as little effort put in application preparation as possible. Off-line objects need to be filled with data from database and commit changes made by user. It appears as though this task is not so easy, especially if we consider the vast number of techniques for retrieving and especially updating data in the database.
Experienced database developers might get fed-up with repeatedly performed tedious tasks such as opening a database connection, fetching results from DataReader object to a DataTable and so on. On the other hand, not every developer has to be familiar with database programming and he might get confused with all those off-line structures and various techniques to bring them alive. The purpose of this article is to introduce a custom framework that handles common database access scenarios and isolates widows / Internet presentation layer development from data access layer by exposing several comprehensive routines. Its main goal is to incorporate most elegant solutions and comply with highest standards of SQL Server development using the benefits of ADO .NET.
If you are not familiar with the basics of ADO .NET I guess it would be worth taking a while to read this article from Microsoft's MSDN before you continue.
The most basic task – retrieving information from the database
This was actually the moment I first came up with an idea of dbHelper. I was developing an application which processes enormous number of data. Results were presented to the user who could check whether they were correct and possibly apply some changes, yet the “crazy things” done in the server side were the key point of the application. In order to verify the results user had to access several databases on different servers. In this project I was responsible for developing the solution on SQL Server. My teammate was developing the front-end. After some time it became clear that the easiest way for an effective cooperation was for me to provide him with a library that handles all database access tasks. And so it began…
Retrieving information from database in enterprise scale applications is often handled by stored procedures. Major benefits of this approach are:
- better performance;
- better security;
- each operation can be logged on the SQL Server side;
- reduction of network traffic;
- very elegant solution thanks to programming abstraction;
- well, actually I guess there are hundreds more… This article could give you some perspective on what I named above.
Quite often it is desirable to maintain a log of who and when accessed a specific set of information. (In our case we had to make sure that the user did actually control the results). This task could have been handled by the client application, but it would have required additional coding for each and every data access operation, not to mention that such action would have had to take place two times for each operation (to handle beginnings and endings).
So my approach was to:
- create a stored procedure handling SELECT statements
- create second stored procedure that writes to application log and would be invoked by the first SP
- and finally create a function that uses the stored procedure to retrieve data into ADO .NET objects.
Before we start: our “data retrieval procedure” is going to use sp_executesql in order to execute dynamic SQL statements. As sp_executesql can process any valid SQL statement we have to ensure that the SQL command passed to the procedure is actually a SELECT statement. If not, then we should be able to throw a custom error.
In order to process custom error messages we will have to add a new error type to dbo.sysmessages in master database. We accomplish this task by running the following code in QA (assuming that your user belongs to either sysadmin or serveradmin role. If not then you'll have to ask your SQL server admin to run this code for you):
DECLARE @next_cust_msg_id INT USE master SET @next_cust_msg_id=COALESCE((SELECT MAX(error)+1 FROM dbo.sysmessages WHERE error>50000),50001) EXEC sp_addmessage @msgnum = @next_cust_msg_id, @severity = 16, @msgtext = N'Procedure dbo._spsys_select expects a valid SELECT statement to be passed as @command parameter. Parameter ['%s'] does not contain SELECT keyword.', @lang = 'us_english' SELECT @next_cust_msg_id
Note: You can browse the contents of dbo.sysmessages table in master database, but you cannot modify it unless your instance of SQL Server is configured to “Allow modifications to be made directly to the system catalogs”.
The code above simply creates a new row in dbo.sysmessages table. The trick is that the primary key in this table has to be greater or equal 50001 for custom errors, so we have to check for first free error number and use it in our calls to RAISERROR function.
dbo._spsys_select - stored procedure for data retrieval
a) parameters
- @command NVARCHAR(1000) – SQL SELECT statement;
- @user AS VARCHAR(100) – user currently logged on to client application;
- @rows_returned AS INT OUTPUT – rows returned as a result of our query.
b) execution
- create an entry in log table by performing a call to dbo. _log_task SP;
- check whether @command really contains a valid SELECT
statement;
- construct an input to sp_executesql
- execute @command
- check for errors, if there is an error then create a proper entry in application log
- return 0 if everything worked OK.
- Pretty straight forward, isn’t it?
So far you can:
- execute this procedure in QA:

- view the log table for execution details:
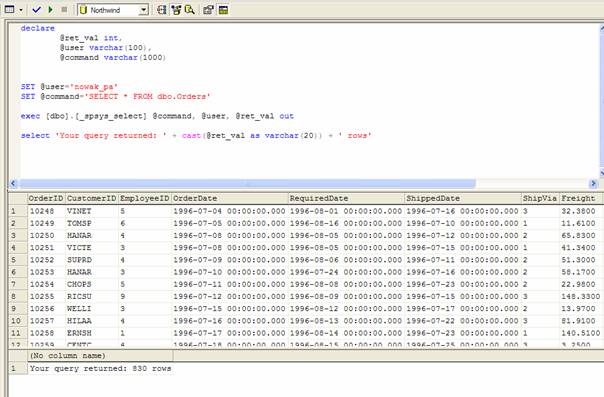
Now we can move on to actually using this thing in live application.
The very beginnings of our custom data access layer
First lest briefly discuss the architecture of our C# .NET solution. It involves two projects:
- windowsClient: our client (or data presentation layer) that is going to use our custom DAL component to retrieve data from the database.
- dbHelper: our class library that is going to be linked into the windowsClient project.
Even though dbHelper class is implemented in C# you may use it in your VB .NET applications also.
The working application should look like this:
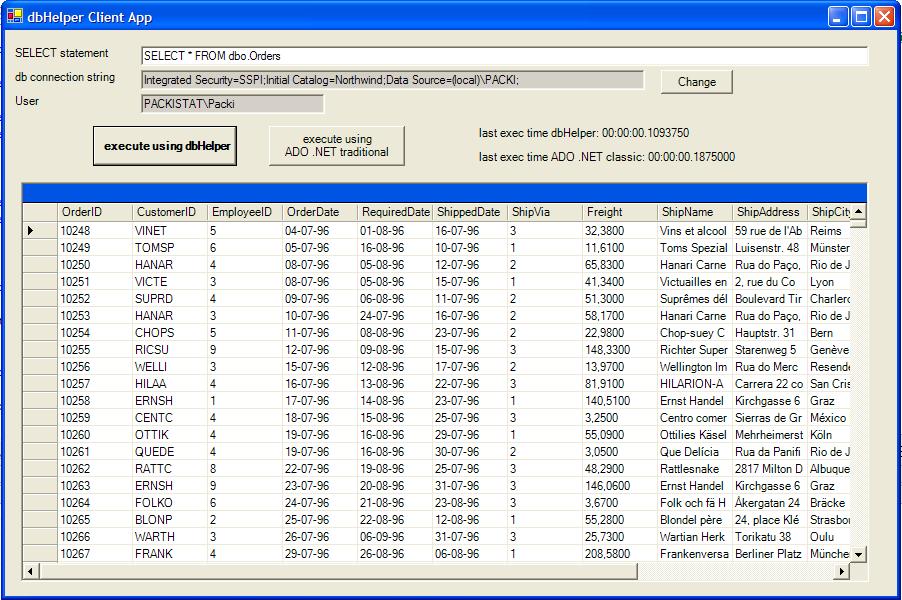
windowsClient’s sole purpose is to test the dbHelper class, so I didn’t care to much about the design.
How it works:
First check whether the connection string is valid for your SQL Server configuration. If not then you'll receive an error when application starts, because dbHelper class is instantiated when application form is being loaded. If so, then use the change button next to connection string TextBox to adjust the configuration. Next thing to do is to input a valid SELECT statement into the first textbox. You can execute your query both using dbHelper and using a simple function. They both do exactly the same thing including logging into the log table. What differs is the execution performance and code involved into retrieving result. The core function for data retrieval using SP is:
public bool execSpsysSelect(string command, string dtTablename)
which takes as parameters your SQL query and the name that should be assigned to newly created DataTable object that is going to hold the result. Function returns false if your query returned an empty set and thus no DataTable object has been created.
In order to display the result the DataGrid control’s DataSource property is set to the newly created DataTable object which resides in the default DataSet called dsDbHelper. All you need to display the result is to add the following code to Button’s OnClick event handler:
if (this.dbh.execSpsysSelect( this.txtSQL.Text, "res"))
this.dataGrid1.DataSource=this.dbh.dsDbHelper.Tables["res"];
Seems nice, especially if you compare it to classic ADO.NET:
int logid=this.dbh.execLogTask("ADO .NET classic ["+this.txtSQL.Text+"]",null,true,-1);
System.Data.SqlClient.SqlConnection c = new System.Data.SqlClient.SqlConnection();
c.ConnectionString=this.txtConnStr.Text;
System.Data.SqlClient.SqlCommand cmd = new System.Data.SqlClient.SqlCommand();
cmd.Connection=c;
cmd.CommandTimeout=3600;
cmd.CommandText=this.txtSQL.Text;
c.Open();
System.Data.SqlClient.SqlDataAdapter da = new System.Data.SqlClient.SqlDataAdapter(cmd);
System.Data.DataSet ds = new DataSet("adonet");
da.Fill(ds,"nonadores");
this.dataGrid1.DataSource=ds.Tables["nonadores"];
this.dbh.execLogTask( null,"completed [rows returned:"+
ds.Tables["nonadores"].Rows.Count.ToString()+"]",false,logid);
Note: dbh.execLogTask is a function included into dbHelper that handles calls to the dbo._log_task SP in order to create log entries in logs table.
Performance
With very simple queries simple ADO .NET performs slightly (I mean really!) better to dbHelper. The difference in execution time is hardly ever over one second. This is possibly due to the fact that dbHelper uses time expensive method FillSchema in order to create the DataTable object that is further filled by a DataReader object. It also has to populate SqlParameter collection for SqlCommand that executes the SP. Finally, in this case, we’re kind of using cannon to kill a fly, aren’t we?
For more complex queries things turn better for dbHelper that performs up to about 10%-20% better. You might want to check it out on my example. It creates 2 tables with 7 columns of random numbers. It is for you to choose the number of records in each table. The SQL script to recreate and populate those objects is included in the companion package.
To test performance I like to use the IN clause…
Before you ask
Anyone who goes through the code of the execSpsysSelect function will notice that I create the DataTable object before I check whether query returned any rows. One could also ask why don’t I use the @rows_returned value.
Well, I don’t use it simply because it is not set until I finish retrieving the result from SELECT statement. The @@ROWCOUNT variable is set after the SELECT statement is completed. In this case SELECT statement is considered to be finished after you close the DataReader object.
Things to do
Ideally a custom DAL library should perform additional tasks that ADO .NET does not handle:
- retrieve additional metadata such as column description and its default value. (Actually I've read on several newsgroups that it is not possible to retrieve column's default value from SQL Server and apply it to DataColumn object. Believe me - it is!)
- properly set ReadOnly flag for columns such as columns with DATETIME() default value that indicates when a given record was created;
- analyze SELECT commands passed to it and implement techniques such as usage of DataRelation object to increase performance and facilitate handling updates, which leads to…
- handle updates to database – this is a challenge using different techniques for optimistic / pessimistic concurrency;
- introduce multithreading to prevent client application from hanging when a large query is begin processed.
- use XML to store / parse data and be able to communicate through XML Web Service
I’m going to take you through all this in future articles.

