

The Execute Package task is used to allow one Integration Services package to call another Integration Services package.
Why is this a good thing? After all, we can achieve everything we need to do by adding tasks to a single package:

The author has seen such a package, printed out for "easy reference". The printout was approximately 12' wide and 8' high, with text so small you had to be within a foot or so of the wall to be able to read it.
Using the Execute Package task allows us to break down the work into smaller units, which has the following benefits:
- Complicated workflow can be broken down into smaller, more maintainable units.
- A child package can be called from multiple parent packages, allowing code re-use.
- Different packages can be worked on simultaneously by different developers - it is next to impossible to manage concurrent development on a single SSIS package, despite the improvements made to "mergeability" in SQL Server 2012.
In short, these are the benefits associated with modular programming, which have been recognised for a long time, certainly since Edsger Dijkstra and others were writing about structured programming in the 1960s.
A Simple Example
We'll create a parent package with two child packages, one with a data flow that goes nowhere, and one that sends an email to notify us that the data load is complete. As a bonus, we'll capture the number of rows inserted in the "Data Flow" package, and pass this via the parent to the "Send Email" package.
We'll create the child packages first, then the parent package to hook them all together.
The "Data Flow" package
This package uses tempdb as the destination for our data flow. We need to create a table to hold the rows we're going to be inserting.
use tempdb; CREATE TABLE dbo.EPDemo ( numCol int not null );
Now, the package. This contains a single data flow task, with an OLEDB source and and an OLEDB destination that both use the same connection manager, which is pointing to tempdb.
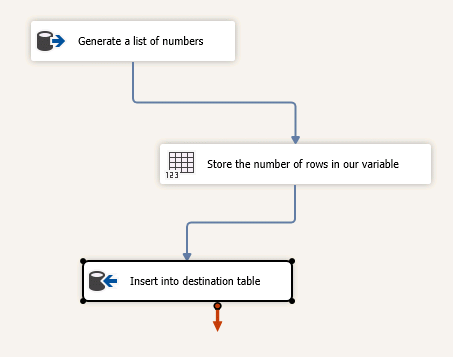
The source contains the following query, which generates a few numbers without referencing any tables:
WITH Fnums (c1, c2) AS (SELECT 0, 1 UNION ALL SELECT c2, c2 + c1 FROM Fnum WHERE c1 <10000 ) SELECT c1 FROM Fnums OPTION (MAXRECURSION 0);
We also have a Row Count Transformation, which will store the number of rows generated into a variable. More on this later.
The dataflow just executes this source, stores the row count in our variable, and inserts the rows to our destination, which references the table we created above.
The "Send Email" package
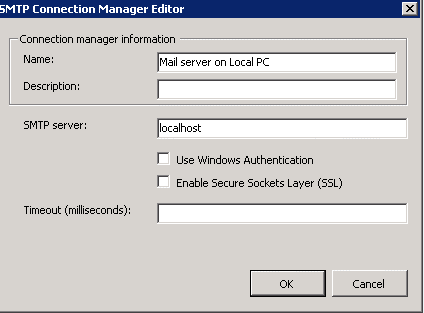
This package is even simpler than the first one. It contains a Send Mail task which we configure to send an email via a mail server on our local machine. The "From" and "to" fields are mandatory, but it doesn't matter what we type in, as long as they "appear" to be valid email addresses.

The SMTP connection manager used by this task is also very easy to configure; it just looks like this:
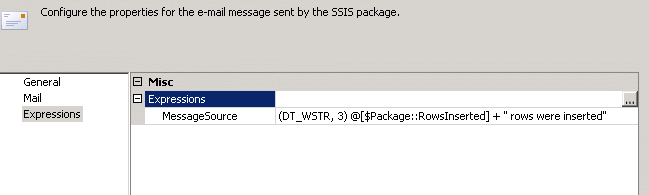
Keen-eyed readers will have noticed that the Send Mail Task contains an expression. This is used to include the number of rows inserted in the body of the email message. As you can see, this value is passed in via a package parameter, for which the default value is zero.
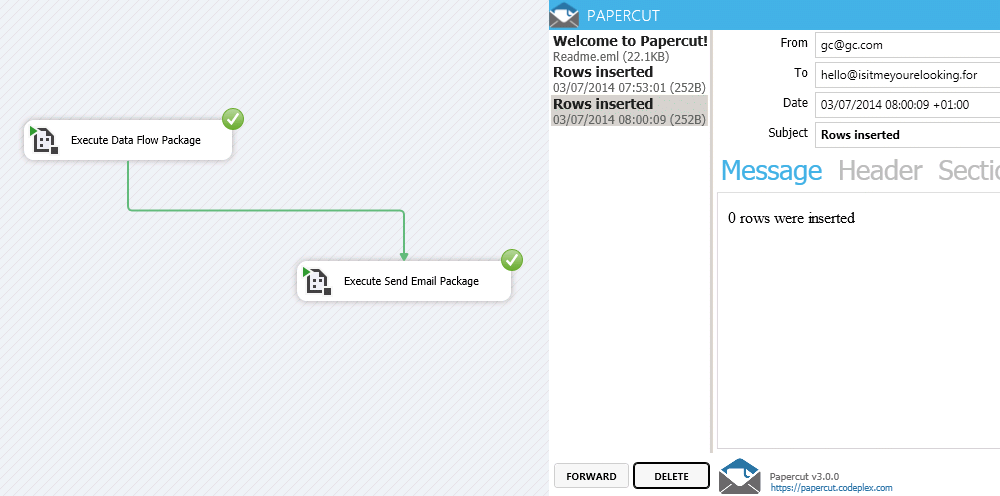
I use the "Papercut" mailserver from papercut.codeplex.com for testing this kind of thing; this creates a mail server on our local machine that can receive messages and display them without sending them anywhere. There's no configuration to do, just download and run.
If we run the "Send Email" package, we get an email telling us 0 rows were inserted.

The story so far
We now have two SSIS packages which can be deployed and tested independently of one another. This means they can both be re-used in a range of contexts, and indeed developed independently.
The Parent Package
The parent package contains two execute package tasks linked by a precedence constraint so that the "Data Flow" package will always run before the "Send Email" package.

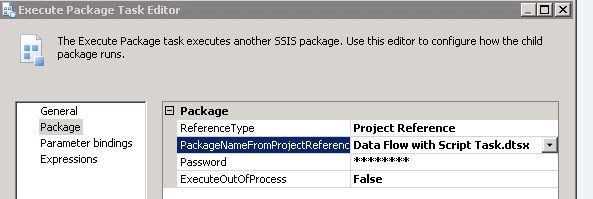
Looking inside the editor for the "Data Flow" Execute Package Task, there are a couple of things to configure:

We set the ReferenceType parameter to "Project Reference", meaning that the package we want to execute is contained in the same project as the caller (the other option is "External Reference", which would allow us to specify the path to a .dtsx file on a file system, or to a package stored elsewhere in a SQL Server). We need to select the package name from the drop-down list, and supply a package password if necessary. ExecuteOutOfProcess does what it says, but we'll leave this at the default of "False" in the absence of any compelling reason to change it.
Passing a value from the parent to the child
In the editor for the "Send Email" Execute Package Task, there is one more thing to note:

We are binding the RowsInserted parameter in the "Send Email" package to a variable in the Parent package. This is how we pass variables from the parent into the child.
If we execute the parent package now, both child packages will be executed, but we will pass a zero to the RowsInserted parameter in the "Send Email" package. What we really want to do, of course, is pass the number of rows from the "Data Flow" package into the parent and then back into the "Send Email" package.
Passing a value from the child to the parent
The most reliable way of passing a value from a child package to its parent is via a script task. We take advantage of the SSIS variable scoping rules to do this. Remember that the scope of the variable "User::ParentRowCount" is set to the parent package, which means that this variable is accessible in all subcontainers of the package, including the Execute Package Task and the child package. The only constraint is that the child package can't contain a variable of the same name as the parent variable we want to write to, as otherwise the child variable would "hide" the parent variable.
The simplest way to do this is to create the script task and add the child variable to the "ReadOnlyVariables" collection and the parent variable to the "ReadWriteVariables" collection.

Our script task only requires one line of code, to assign the one variable to the other;
Dts.Variables["User::ParentRowCount"].Value = Dts.Variables["User::RowsInserted"].Value;
This works because the contents of this dialog are not validated at design time, so we will be able to deploy and run our package, as long as we only ever execute the "Data Flow" package via the Execute Package task. If we attempt to execute the child package by itself, it will fail, as there will be no variable "User::ParentRowCount" to write to. This is somewhat unsatisfactory, as we'd really like to be able to develop and test the child package in isolation.
The answer is to remove these variables from the built-in ReadOnlyVariables and ReadWriteVariables collections, and add a test in the body of the code to see whether the variable is present before attempting the assignment.

I've included the whole of the Main() function here. We use the Contains() function to check whether the variable exists before doing the assignment. We also have some additional "plumbing" to do to create our own variables collection, "lock" the variables we need, then "unlock" them when we're done.
public void Main()
{
if (Dts.VariableDispenser.Contains("User::ParentRowCount"))
{
Variables vars = default(Variables);
this.Dts.VariableDispenser.LockForWrite("User::ParentRowCount");
this.Dts.VariableDispenser.LockForRead("User::RowsInserted");
this.Dts.VariableDispenser.GetVariables(ref vars);
vars["User::ParentRowCount"].Value = vars["User::RowsInserted"].Value;
vars.Unlock();
}
Dts.TaskResult = (int)ScriptResults.Success;
}In the download that accompanies this article, I've included a second version of the "Data Flow" package containing this script task. If you modify the Execute Package task to call this version instead, you should get the number of rows inserted into the body of the email.
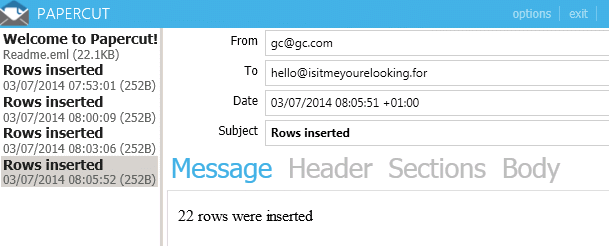
Here's the Papercut window again, this time with the correct row count.
Summary
If you run the "Data Flow" package by itself, the rows will still be inserted and the package will not fail.Likewise, the "Send Email" package can also be run by itself, in this case reporting that "0 rows were inserted". By adding a few lines of code, we have two child packages that can be developed and tested independently, delivering the benefits noted at the start of the article.
