
This article is all about joins in U-SQL. Before we go into that, it struck me that we’ve reached Level 8 in this U-SQL Stairway series, and I haven’t explained what the U stands for in U-SQL. You may think the language is called U-SQL as U comes after T in the alphabet, so U-SQL is the logical name, following on from T-SQL. Not so! I had the reason for the name directly from the horse’s mouth at SQLBits 2016. The horse in this case being Michael Rys, the principal program manager for U-SQL. The U stands for U-Boat, a German submarine. The idea is a U-boat can dive into the sea, and U-SQL can dive into your Data Lake. Makes sense when you think about it!
OK, without further ado let’s take a look at what joins are available to us in U-SQL. We’ve written a number of queries over the course of this series so far, but they’ve all used a single table. It’s time to spread our wings!
Before We Start
Before we start, we need to populate the tables with data - we haven't actually done this so far in the series. Open the Visual Studio project up and add a new script to it. Call the script 200 Populate Tables.usql. Add this code:
USE DATABASE UkPostcodes; USE SCHEMA Postcodes; DECLARE @CountyFilePath string = "/ssc_uk_postcodes/counties/England_Counties.csv"; DECLARE @DistrictFilePath string = "/ssc_uk_postcodes/districts/England_Districts.csv"; DECLARE @PostcodeFilePath string = "/ssc_uk_postcodes/postcodes/Postcodes.csv"; DECLARE @EstimatesFilePath1 string = "/ssc_uk_postcodes/postcodeestimates/Postcode_Estimates_1_A_F.csv"; DECLARE @EstimatesFilePath2 string = "/ssc_uk_postcodes/postcodeestimates/Postcode_Estimates_1_G_L.csv"; DECLARE @EstimatesFilePath3 string = "/ssc_uk_postcodes/postcodeestimates/Postcode_Estimates_1_M_R.csv"; DECLARE @EstimatesFilePath4 string = "/ssc_uk_postcodes/postcodeestimates/Postcode_Estimates_1_S_Z.csv"; TRUNCATE TABLE Counties; TRUNCATE TABLE Districts; TRUNCATE TABLE Postcodes; TRUNCATE TABLE PostcodeEstimates; INSERT INTO Counties (CountyCode, CountyName) SELECT CountyCode, CountyName FROM ( EXTRACT CountyCode string, CountyName string FROM @CountyFilePath USING Extractors.Csv()) AS counties; INSERT INTO Districts (DistrictCode, DistrictName) SELECT DistrictCode, DistrictName FROM ( EXTRACT DistrictCode string, DistrictName string FROM @DistrictFilePath USING Extractors.Csv()) AS districts; INSERT INTO Postcodes (Postcode, CountyCode, DistrictCode, CountryCode, Latitude, Longitude) SELECT Postcode, CountyCode, DistrictCode, CountryCode, Latitude, Longitude FROM (EXTRACT Postcode string, CountyCode string, DistrictCode string, CountryCode string, Latitude decimal?, Longitude decimal? FROM @PostcodeFilePath USING Extractors.Csv()) AS postcodes; INSERT INTO Postcodes.PostcodeEstimates ( Postcode, Total, Males, Females, OccupiedHouseholds ) SELECT Postcode, Total, Males, Females, OccupiedHouseholds FROM (EXTRACT Postcode string, Total int?, Males int?, Females int?, OccupiedHouseholds int? FROM @EstimatesFilePath1 USING Extractors.Csv()) AS estimates; INSERT INTO Postcodes.PostcodeEstimates ( Postcode, Total, Males, Females, OccupiedHouseholds ) SELECT Postcode, Total, Males, Females, OccupiedHouseholds FROM (EXTRACT Postcode string, Total int?, Males int?, Females int?, OccupiedHouseholds int? FROM @EstimatesFilePath2 USING Extractors.Csv()) AS estimates; INSERT INTO Postcodes.PostcodeEstimates (Postcode, Total, Males, Females, OccupiedHouseholds) SELECT Postcode, Total, Males, Females, OccupiedHouseholds FROM (EXTRACT Postcode string, Total int?, Males int?, Females int?, OccupiedHouseholds int? FROM @EstimatesFilePath3 USING Extractors.Csv()) AS estimates; INSERT INTO Postcodes.PostcodeEstimates (Postcode, Total, Males, Females, OccupiedHouseholds ) SELECT Postcode, Total, Males, Females, OccupiedHouseholds FROM (EXTRACT Postcode string, Total int?, Males int?, Females int?, OccupiedHouseholds int? FROM @EstimatesFilePath4 USING Extractors.Csv()) AS estimates;
This will insert data into the Counties, Districts and Postcodes tables, respectively. Hit the Submit button on the toolbar to execute this (refer back to article 4 if you need a refresher). Great, now we have some data. Back to the joins!
Join Types
U-SQL supports a number of join types – some may well be familiar to you, others may not.
- INNER JOIN
- FULL OUTER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- CROSS JOIN
- LEFT SEMIJOIN
- RIGHT SEMIJOIN
- LEFT ANTISEMIJOIN
- RIGHT ANTISEMIJOIN
I’m not going to explain what each join does in any detail – there are many articles available that explain this already. Rest assured that the first five joins in the list work in the same manner as those joins in SQL Server. We’ll briefly look at the SEMI and ANTISEMI join types later on.
Join Aliases
I always use aliases when writing T-SQL code. Something like this, for example:
SELECT p.Postcode, c.CountyName
FROM Postcodes p
INNER JOIN Counties c
ON p.CountyCode = c.CountyCode;Equality operator aside, this is invalid U-SQL syntax. If I try to run a script containing this statement, I’ll see an error:

The statement has failed because in U-SQL, the AS keyword is mandatory. We have to write the statement as:
SELECT p.Postcode, c.CountyName
FROM Postcodes AS p
INNER JOIN Counties AS c
ON p.CountyCode == c.CountyCode;Apart from the AS keyword, take note of the double equals (==) sign – the C# equality symbol. Remember what we’ve discussed in earlier articles – U-SQL uses C# operators, not T-SQL operators.
Here’s the full script for the above SELECT statement, which outputs the results to a file called joins.tsv. You can use this script for all other SELECT statements demonstrated – just replace the SELECT as appropriate.
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
@pcodes = SELECT p.Postcode, c.CountyName
FROM Postcodes AS p
INNER JOIN Counties AS c
ON p.CountyCode == c.CountyCode;
OUTPUT @pcodes TO "/outputs/joins.tsv"
USING Outputters.Tsv();There’s one more thing I need to mention about aliases – if they’re longer than one character, they can’t be written in upper-case letters. So this query will work:
SELECT P.Postcode, C.CountyName
FROM Postcodes AS P
INNER JOIN Counties AS C
ON P.CountyCode == C.CountyCode;But this version will fail:
SELECT PC.Postcode, CY.CountyName FROM Postcodes AS PC INNER JOIN Counties AS CY ON PC.CountyCode == CY.CountyCode;
Why? Because U-SQL considers all upper-case words to be code keywords. You’ll see compilation errors if you try this:
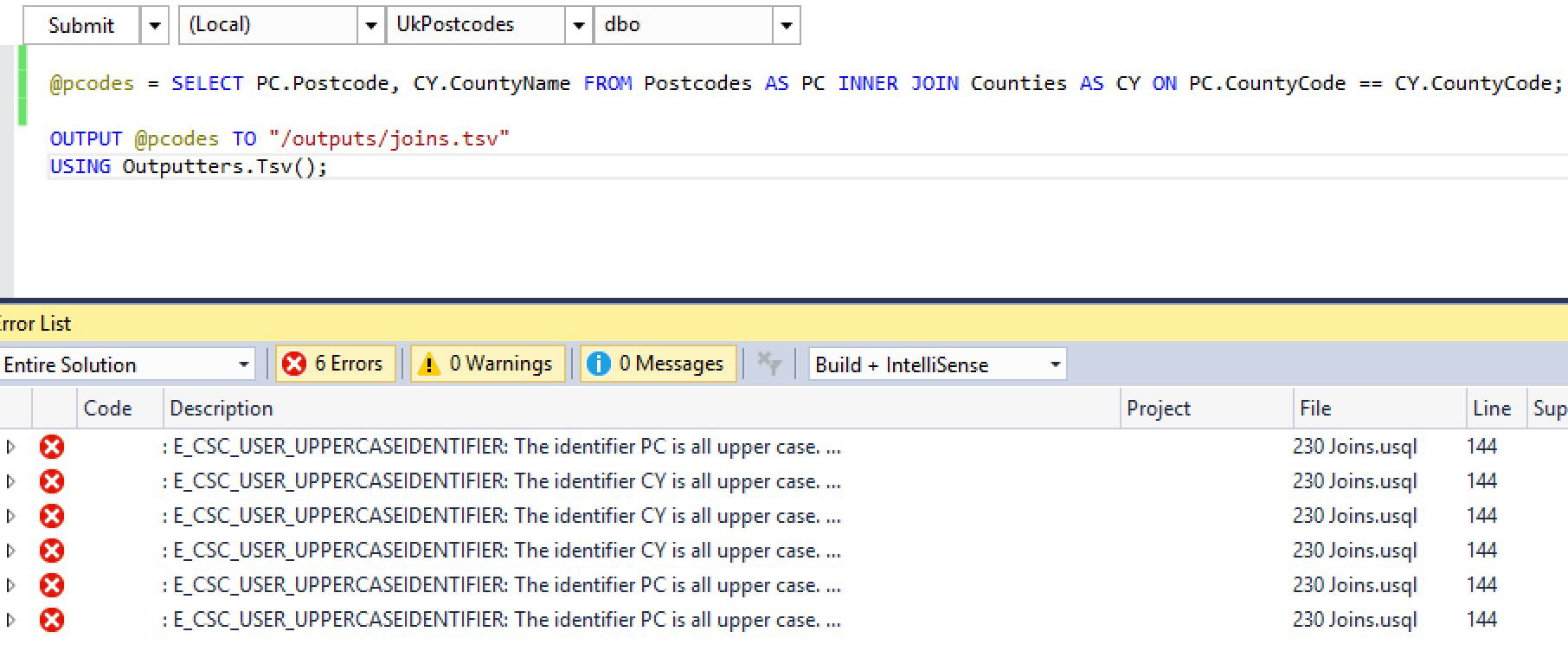
The simple answer is to either make all your aliases lower-case, or just capitalise the first character. As long as you’re consistent you’ll be fine.
Join Operators
There are some noticeable differences between T-SQL and U-SQL joins. Perhaps the most important thing to be aware of is that you can only join using the equality operator (which, remember, is ==, not =). I’ve used not equals, greater than, IN and lots of other filter types in T-SQL joins – but none of those will work here. So this statement is fine:
SELECT p.Postcode, c.CountyName FROM Postcodes AS p INNER JOIN Counties AS c ON p.CountyCode == c.CountyCode;
A nice, simple join on CountyCode. But this would not be allowed:
SELECT p.Postcode, c.CountyName FROM Postcodes AS p INNER JOIN Counties AS c ON p.CountyCode == c.CountyCode AND p.CountyCode != "E10000013";
The line AND p.CountyCode != "E10000013" will raise an error. You’d need to move this to the WHERE clause:
SELECT p.Postcode, c.CountyName FROM Postcodes AS p INNER JOIN Counties AS c ON p.CountyCode == c.CountyCode WHERE p.CountyCode != "E10000013";
U-SQL only supports the equality operator at the time of writing (August 2016). More operators may appear in the future. But not to worry, thanks to the C# language features there are many ways in which we can filter data, as you’ll see.
Join Values
In T-SQL, you can write something like this and SQL Server will happily return you a result set:
SELECT p.Postcode, c.CountyName FROM Postcodes AS p INNER JOIN Counties AS c ON p.CountyCode = c.CountyCode AND LEFT(p.Postcode, 3) = ‘FY5’ WHERE c.CountyName IN (‘Staffordshire’, ‘Lancashire’);
But not so in U-SQL! You can only join on actual columns, not prescribed values. If it isn’t a column, you won’t be using it for joins. Columns or bust! Which means the U-SQL version of the above statement would be:
SELECT p.Postcode, c.CountyName
FROM Postcodes AS p
INNER JOIN Counties AS c
ON p.CountyCode == c.CountyCode
WHERE c.CountyName IN ("Staffordshire", "Lancashire")
AND p.Postcode.Substring(0, 3) == "FY5";Again, the solution is to move the filter to the WHERE clause. It’s worth pointing out we’ve introduced the IN keyword here, which we haven’t seen in the series before. U-SQL supports most of the T-SQL keywords you’re familiar with, and they generally work in the same way too (not always, but most of the time).
You can specify multiple equality clauses in a join, so you are allowed to join on more than one column should you need to.
OK, so just to be clear, the rules for joins are:
- Upper-case aliases are not supported
- You can only join on the equals operator
- You can only join on columns
- You can join on multiple columns, as long as all clauses use the equality operator
Join Data Sources
Our old friend, SQL Server, provides access to a huge range of data sources. Apart from tables, you can also create derived tables from sub-queries and join to them, join to table-valued functions (although you’d normally use one of the APPLY operators here), and join to views. There are lots of other ways to create data sources too.
U-SQL also supports a number of different data sources:
- Managed tables - Tables that live in an Azure Data Lake database. These are the tables we’ve been creating throughout this series. We took a detailed look at these in article 5.
- Data Sources (may also be called Unmanaged or External Tables) - One of U-SQL’s big selling points is that it supports the querying of data without needing to bring it into a U-SQL database – that is, the data can be queried from its current location. To do that, you need to create a data source. This creates a metadata implementation of a table, which communicates directly with the underlying data source. We’ll look at data sources in some detail in the future. With these, you can join to data in a SQL Server database running on an Azure virtual machine, an Azure SQL database, or an Azure SQL Datawarehouse instance.
- Sub-queries - This is a SELECT statement that you embed in brackets. To the rest of the query, it acts as a table. Works exactly the same as a sub-query does in T-SQL.
- Rowset variables - You can assign a rowset to a variable, and then join to that variable.
- Files - If you have a file in your Data Lake that you want to join to, but you don’t want to bring it into a U-SQL table, that’s fine. You can either store it in a rowset variable, or join directly to the file via an embedded EXTRACT statement.
- Views - U-SQL supports views, and yes, you can join to them.
Joining Tables to Data Sources
Joining using managed and unmanaged tables (unmanaged tables = data sources) and views offers no syntactical differences – you can’t even tell which type of object you are using. This query left joins a managed table to a managed table:
SELECT p.Postcode, c.CountyName FROM Postcodes AS p LEFT JOIN Counties AS c ON p.CountyCode == c.CountyCode;
Here’s the output:

Not all counties are stored in my Counties table, so the left join has returned some postcodes without a county. We can run a second query that joins to a table in an Azure SQL database. Here’s the Azure SQL table:
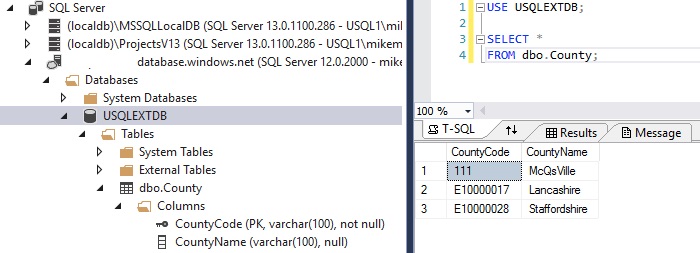
I wonder what life is like in McQsVille…sounds an interesting place. Anyway, you can see I’ve created a table in my Azure SQL database with a couple of valid county records in it. I’ve created an external data source in my UkPostcodes U-SQL database, which references the Azure SQL County table. The external table is called SqlDbCounty. I won’t go into how I created it at this point as it’s a fairly convoluted process. But here’s the same query, using the external table instead of the local version:
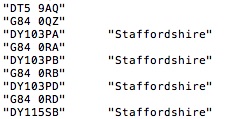
SELECT p.Postcode, c.CountyName FROM Postcodes AS p LEFT JOIN SqlDbCounty AS c ON p.CountyCode == c.CountyCode;
Other than the name of the second table (SqlDbCounty), could you spot the difference? No, neither could I! I know we haven’t seen how to bring data in from external sources yet, but don’t fret. All good things will come to those who wait! Here are a few of the results from that query:
To finish this section off, take a look at this query. It’s the same left join query we used to access the U-SQL Postcodes and Counties tables, but now it’s using a sub-query.
SELECT p.Postcode, c.CountyName FROM Postcodes AS p LEFT JOIN ( SELECT CountyCode, CountyName FROM Counties ) AS c ON p.CountyCode == c.CountyCode;
The query will still perform as well as the original query, but it clearly shows we can embed more complicated statements within our sub-queries if necessary. As always, knowing which tools are available in a language can help you make the correct selection for your particular problem.
Joins Using Rowsets and Files
You can mix and match all the join data sources as much as you wish. You can join a table to a file to a view to an external data source if you wish – U-SQL treats them all the same. A data source is a data source.
Let’s take a look at how we join a rowset variable to a table. We’re using Postcodes, Counties and Districts data. So far I’ve only shown individual SELECT statements, but here’s the full script for this one should you wish to try it out:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
DECLARE @DataFilePath string = "/ssc_uk_postcodes/districts/England_Districts.csv";
@districts = EXTRACT DistrictCode string, DistrictName string
FROM @DataFilePath USING Extractors.Csv();
@counties = SELECT CountyCode, CountyName FROM Counties;
@pcodes = SELECT p.Postcode, d.DistrictName, c.CountyName
FROM Postcodes AS p
INNER JOIN @districts AS d
ON p.DistrictCode == d.DistrictCode
LEFT JOIN @counties AS c
ON p.CountyCode == c.CountyCode;
OUTPUT @pcodes TO "/outputs/joins.tsv" USING Outputters.Tsv();This will work, just as querying three tables would. Here, we are querying a table, a rowset variable populated from a file, and a rowset variable populated from a table. Nifty!
We can reduce the amount of code still further, by joining directly to the @districts EXTRACT statement and the @counties SELECT statement. Here’s the full script:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
DECLARE @DataFilePath string = "/ssc_uk_postcodes/districts/England_Districts.csv";
@pcodes = SELECT p.Postcode, d.DistrictName, c.CountyName
FROM Postcodes AS p
INNER JOIN (EXTRACT DistrictCode string, DistrictName string
FROM @DataFilePath USING Extractors.Csv()
) AS d
ON p.DistrictCode == d.DistrictCode
LEFT JOIN (SELECT CountyCode, CountyName FROM Counties
) AS c
ON p.CountyCode == c.CountyCode;
OUTPUT @pcodes TO "/outputs/joins.tsv" USING Outputters.Tsv();Pretty cool!
Joins Using Views
When used in a join, a view will act, to all intents and purposes, exactly as a table would. I won’t spend any time on views now, we’ll take a look at them in the next article.
What About Table Valued Functions (TVFs)? TVFs exist in U-SQL, but you may be surprised to learn you can’t use them in your queries – not in the way you can in T-SQL, using APPLY, for instance. We’ll look at TVFs in a couple of steps, so you’ll learn more then.
Join Types
To finish off, let’s have a very quick recap of the join types available to us in U-SQL.
- INNER JOIN
- FULL OUTER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- CROSS JOIN - These all directly correlate to their SQL Server equivalents, and behave in the same way too. As I mentioned right at the top, there are many articles explaining how all of these join types work, so if you want more information on these a simple Web search will give you plenty of options.
- LEFT SEMIJOIN
- RIGHT SEMIJOIN - SEMIJOINs return rows from one table that join with rows in another table, but without performing a complete join. Once a match has been made, the query moves to processing the next row. Assume we wanted to return counties that had a match in the postcodes table. With the SEMIJOIN, as soon as a matching postcode was found in the postcodes table for the county, the next county would be processed for a match. This is similar to writing an EXISTS statement, of the form SELECT * FROM x WHERE EXISTS (SELECT * FROM y WHERE x.Id = y.Id).
- LEFT ANTISEMIJOIN
- RIGHT ANTISEMIJOIN - This is the opposite of the SEMIJOIN above. You’d use this to return a result set which is equivalent to a NOT EXISTS statement.
Summary
We’ve covered a whole heap of stuff in this article. It’s clear that joins in U-SQL, although they seem to work similarly to SQL Server joins on the surface, have some key differences, such as the limitation of only being able to use the equality operator and only being able to join on columns. This is made up for by allowing us to filter data in lots of other ways, using rowsets and sub-queries.
We briefly discussed views in this article, but we never actually saw them in action – we’ll resolve that next time around. See you then!
