Request for sanity check of basic ETL process and database placement
-
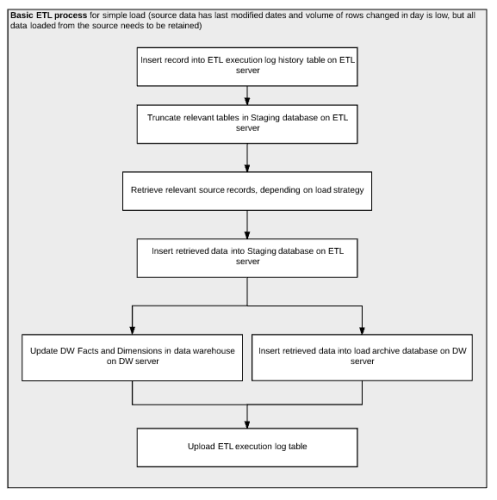
Is anything below obviously impractical, or against accepted practices in the below flow chart for a PoC ETL? I'm a little unsure on the physical data storage placement for a Data Warehouse ETL, and I'd really appreciate some advice on this.

I'll give server specs / database sizing / load estimates if they would be helpful, I haven't included them in-case they would distract from the above query - I'm trying to get the logic of where to store data during the ETL sorted before nailing down detailed hardware / load plans.
Andrew -
I mean, it seems pretty basic. You're starting off by logging your process then truncating the prior load data right off the bat. I assume this is so you can keep the staging data available in case of issues after the next load, which is fine. Then you load the data into staging and make a decision whether or not to update or insert a record based on some conditions unknown in the diagram (assuming using something like a MERGE statement). Once records have moved to production, then you update the log table. All pretty basic, straight forward and easy to follow.
Are there better ways to do this? Just depends on the data and what you're trying to do. If the data is large, you may want to try and load the data in parallel with multiple ETL processes. You may even want to split the data into smaller chunks on the physical device (i.e.: hard disk) before you even begin to load the data into staging. Maybe even do that split on a separate machine all together in order to distribute the workload while breaking a large problem into smaller manageable chunks.
Off the bat, I would say a major piece missing from your flow here is validation. How are you validating the source data? Another piece is how you are handling failed records during the transaction phases of your ETL? What happens when these records fail to update or insert from staging to primary? Better yet, what happens if the records fail to insert all together into staging? What happens? Does the ETL fail? Does it push the records to another table marked for failed records? What happens if the source data is not ready? Is it fine to log the execution of the job and truncate the prior load of records when the source is not ready? Etc.
Hope that helps
- xsevensinzx - Tuesday, March 7, 2017 6:31 AM
Heh... +1000. I can tell you've had to sweat this out before. 😉
I agree with the basic diagram first provided especially since it's impossible to correct a blank piece of paper. 😉 It's really nice to see someone mapping out a plan for a change. It will also serve well for 60,000 ft executive overviews but I'll also add "What are the concurrency requirements"? "What method is being used to ensure the entire file has been received" (also known as "File Reliability"? "How are you making the determination that a file is no longer locked by whatever load process that creates it"? "How long do the source files need to be kept"? "What happens to a file source once it's been loaded? Can it be zipped, moved, or removed"? "What does the source folder structure look like and how can you tell which files have already been loaded"? "How do you identify which files or parts of files go to which table(s)"? "Whom shall be notified in the event of failure and who should the errata list be sent to for each type of file (think "stakeholders")"?
I'm missing a dozen or more considerations especially if you want to all operate auto-magically.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - xsevensinzx - Tuesday, March 7, 2017 6:31 AM
Data cleansing and data validation are very important for a Data Warehouse, and can sometimes be the trickiest part. Just remember that the data warehouse is supposed to represent the one true representation of the business facts, and places where you work around bad data in an OLTP system may need additional cleansing in a data warehouse environment.
-
Thanks xsevensinzx, Jeff and Chris. I appreciate the confirmation there's nothing obviously wrong with the data placement in the diagram above, besides the lack of detail. I was being asked to give hardware requirements on a deadline before I'd designed the ETL strategy, which is why this is so oversimplified. Your responses tell me having a dedicated ETL server is OK, and locating the staging database on that ETL server is also an acceptable practice. I feel a little more confident about this now.
I think your comments are a very solid checklist on what I need to consider next - this is also really appreciated. I have Kimball's Data Warehouse Toolkit, which I think will be a good resource for helping me work through the pointers you've given me. And thanks for the encouragement.
Andrew P.
- Andrew P - Monday, March 13, 2017 12:56 AM
I've found the Kimball group's books and their websites to be extremely valuable in understanding data warehouse analysis, design, and implementation:
http://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/
Ralph Kimball himself has retired but some of the other major contributors to the Kimball Group started a new group:
http://decisionworks.com/category/articles-design-tips/
Viewing 6 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply