

Finance saw the issue before the pipeline did
At 07:18, finance sent a short message: “Yesterday’s vendor settlement is almost double. Can you check before the cash review?”
That was not a Snowflake health question. The task had completed, COPY had loaded rows, no records were rejected, and the dashboard refreshed before 08:00. From a platform point of view, the pipeline looked normal. From finance’s point of view, the number was wrong, and that was the only thing that mattered.
The feed was a vendor settlement file used for the morning cash view. The business expectation was simple: one vendor, one settlement date, one final extract. If the amount was wrong, finance could start the day with a bad cash number. That is a trust problem, not only a data problem.
The first guess was a duplicate file. That was partly correct. The vendor’s delivery process had retried overnight. The original file landed, and a second file landed a few minutes later with a retry suffix. Both files were readable. Both matched the load pattern. Snowflake loaded both.
The part we missed at first was more important: a few days earlier, the vendor had moved settlement-file generation to a cheaper back-office application. The old file used to include invoice_number, and our downstream logic used that column as the natural duplicate key. The new extract still had amount, date, currency, and description, so it looked usable and loaded cleanly. What it no longer had was the one field that told us whether a row had already been counted.
Their executive was clear about the constraint. The billing platform team would need time to work out how invoice references could be brought back into this export without breaking their new process. They were also in a finance freeze, so they could not make a manual export change just because our pipeline depended on that column.
That is how this incident became possible. A retry file arrived at the same time our best dedupe key had been removed.
Why the invoice number mattered
The old design was not foolish. For this feed, vendor_id + settlement_date + invoice_number was a practical key. If the same invoice appeared twice in the same settlement date, the curated layer could reject or collapse the duplicate. Many production pipelines start this way because the source gives them a stable business identifier.
The vendor changed that assumption during a billing-platform migration. Their explanation was familiar: the new settlement export came from a module that grouped settlement lines differently, while invoice references moved to a separate reconciliation export. They were also in a finance freeze, so they could not add the column back immediately.
Their response was essentially: “We can’t change the export this month. You’ll need to handle it on your side.”
That shifted the incident. If invoice number had still been present, we would compare invoice keys and move on. Without it, count and amount were not enough proof. Two files can have the same row count and the same total while containing different business lines. We needed a way to compare the available content inside the two staged files.
That is where the two-step hash came in. It was not used because hashing is better than a business key. It was used because the business key had disappeared and the vendor could not restore it in time.
Reproducing the incident in Snowsight
The lab below keeps the shape close to the incident. We will create a temporary raw table without invoice_number, place two files in the Snowflake user stage, load both files into raw, and then prove that the two files carry the same available business content.
The first step is the raw table. Notice that load_file_name is captured separately. The filename is not a business key, but it is useful evidence when investigating which staged object produced which rows.
create or replace temporary table vendor_settlement_raw ( vendor_id string, settlement_date date, amount number(12,2), currency_code string, description string, load_file_name string, load_ts timestamp_ntz );
At this point, the table is empty. The important part is the missing column. In the old feed, invoice_number would have made duplicate detection straightforward. In this new layout, the pipeline has to work with weaker information.
Next, create two staged files. The first file represents the normal delivery. The second file represents the retry. Both carry the same settlement rows, but they land under different staged paths.
copy into @~/vendor_retry_lab/original/VND-4182_20260530
from (select * from values
('VND-4182','2026-05-30',1250.00,'USD','software license charge'),
('VND-4182','2026-05-30', 740.00,'USD','support adjustment'),
('VND-4182','2026-05-30',2010.00,'USD','usage settlement'))
file_format = (type = csv field_delimiter = '|') overwrite = true;
copy into @~/vendor_retry_lab/retry/VND-4182_20260530_retry_0214
from (select * from values
('VND-4182','2026-05-30',1250.00,'USD','software license charge'),
('VND-4182','2026-05-30', 740.00,'USD','support adjustment'),
('VND-4182','2026-05-30',2010.00,'USD','usage settlement'))
file_format = (type = csv field_delimiter = '|') overwrite = true;
 This block creates the core production shape: two staged filenames for the same vendor settlement content. Snowflake does not know that the second one is a retry of the first. It only sees two files that match the path.
This block creates the core production shape: two staged filenames for the same vendor settlement content. Snowflake does not know that the second one is a retry of the first. It only sees two files that match the path.
Now load both files into raw, capturing the staged filename with METADATA$FILENAME.
copy into vendor_settlement_raw
from (
select
$1::string,
$2::date,
$3::number(12,2),
$4::string,
$5::string,
metadata$filename,
current_timestamp()::timestamp_ntz
from @~/vendor_retry_lab
)
file_format = (type = csv field_delimiter = '|');
Snowflake should load six rows: three from the original file and three from the retry file. That is technically correct. The files were readable, the format matched, and the rows converted. The load success only proves that the operation completed. It does not prove the second file should count in finance.
Confirming why finance saw double
The first useful investigation query should match the business complaint. For the vendor and settlement date in question, check row count, amount total, and number of source files.
select vendor_id, settlement_date, count(*) as row_count, sum(amount) as total_amount, count(distinct load_file_name) as source_files from vendor_settlement_raw where vendor_id = 'VND-4182' and settlement_date = '2026-05-30' group by vendor_id, settlement_date;
Below is the output from running the above query :
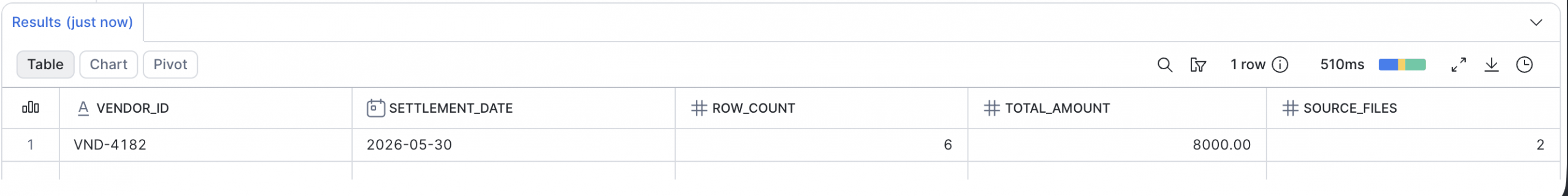
The expected amount was 4,000. The query returns 8,000. The raw table has six rows from two source files. This explains the finance complaint, but it is still not enough to safely delete anything.
Count and amount are only a smell check. A correction file could have the same number of rows and the same total with different settlement lines. The _retry suffix is a useful clue, but production cleanup should not depend only on a filename pattern.
If invoice_number existed, this would be the point where we compared invoice keys. Since that key is missing, we compare the available row content instead.
Proving the duplicate with a two-step hash
The content fingerprint here is calculated in two steps. First, create a hash for each row using the remaining business columns: vendor, settlement date, amount, currency, and description. Second, group those row hashes by filename, sort them, join them, and hash the joined list. Sorting matters because the same rows may appear in a different order across retries.
This is a fallback technique. A stable invoice number would be better. In this incident, that column was not available.
with row_hashes as (
select
load_file_name,
sha2(concat_ws('|', vendor_id, to_varchar(settlement_date),
to_char(amount, 'FM9999999990.00'), currency_code, description), 256) as row_hash
from vendor_settlement_raw
)
select
load_file_name,
count(*) as rows_in_file,
sha2(listagg(row_hash, '|') within group (order by row_hash), 256)
as content_fingerprint
from row_hashes
group by load_file_name
order by load_file_name;
Below is the output from running the above query :

The filenames are different, but the content fingerprint is the same. That means both staged files carried the same available business rows. This is stronger than saying the row count matched or the amount matched. It compares the row content that remained after the vendor removed invoice numbers.
There are trade-offs. The columns used for hashing must represent the real business row. If the feed has transaction id or invoice number, use that first. If descriptions are unstable, they may not belong in the hash. For very large files, persist fingerprints during ingestion instead of calculating them repeatedly in downstream queries. The method is simple, but the column choice is a design decision.
What the pipeline should have done
The fix is not to make finance depend on a hash query run during an incident. The better pattern is an accepted-load control between raw arrival and finance reporting. Raw should record what arrived: staged filename, load time, row count, amount, and the data itself. A manifest or accepted-load table should decide what counts. For each file, store the vendor, settlement date, feed name, filename, row count, amount total, available key status, content fingerprint, and decision status.
The statuses can be plain. The first valid file for a vendor and date is ACCEPTED. A second file with the same fingerprint becomes DUPLICATE_RETRY. A second file with a different fingerprint becomes CORRECTION_PENDING rather than being silently accepted or rejected. That difference matters. A retry duplicate and a correction file are not the same operational event. Finance should not discover either one by seeing a doubled dashboard.
For the lab, cleanup can be shown with a narrow delete against the proven retry filename. In production, I would prefer to keep raw append-only and exclude the duplicate through the accepted-load layer.
delete from vendor_settlement_raw where load_file_name ilike '%VND-4182_20260530_retry_0214%';
After this, the simulated total returns to 4,000. That fixes the lab, but the lesson is bigger than the delete. A raw table can show what arrived; it should not automatically define what finance is allowed to count.
Conclusion
The incident was not caused by Snowflake failing to load data. Snowflake loaded both files successfully. The problem was that our acceptance logic still assumed an invoice number existed, while the vendor’s new export had removed it. When the retry file arrived under a different staged name, the old duplicate protection had nothing stable to compare. Count and amount showed the symptom, but they were not proof. The two-step hash gave us a fallback way to compare file content when the natural key was missing.
The better long-term design is clear: use the natural business key when it exists, fail loudly when it disappears, and keep finance reporting behind an accepted-load layer. Raw should preserve arrivals. The manifest should decide whether a file is accepted, duplicate, or pending correction. Had that control existed, the retry file would have become a boring DUPLICATE_RETRY row instead of an 07:18 finance escalation.