why query optimizer is using Non-clustered index for count(*) operation
-
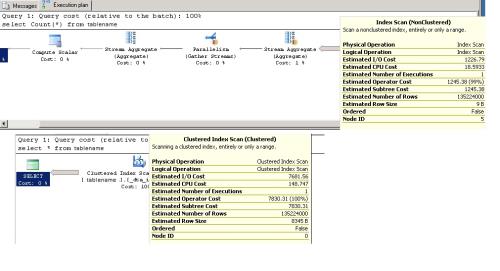
why query optimizer is using Non-clustered index scan for "select count(*)" operation and Clustered Index scan for "select * from tablename" operation.
This table contains both clustered and non clustered Index. The column "file_No" is added to both the indexes as key value.
I have attached execution plan for reference.
Version:SQL version 2008R2
. -
Because a count(*) is asking how many rows are in the table, not the contents of the rows, and hence that can be answered with any index, as all non-filtered indexes have the same number of rows as the table.
Select * however is asking for all columns, all rows, and the fastest way to answer that is a table scan, which is what a clustered index scan is.Gail Shaw
Microsoft Certified Master: SQL Server, MVP, M.Sc (Comp Sci)
SQL In The Wild: Discussions on DB performance with occasional diversions into recoverabilityWe walk in the dark places no others will enter
We stand on the bridge and no one may pass - To expand on that slightly, the optimizer will use the narrowest index it can to achieve whatever it needs to, because there is less data to access.
The index it chose for the 'select count(*)' has an average of 9 bytes, whereas the clustered index is 8,345 bytes - why choose the larger index if the smaller one will achieve the same purpose?
When you use 'select *' you've asked for all of the columns and the non-clustered index can't fulfil that (at least, not alone - other work would be required) - but the clustered index can.
Viewing 3 posts - 1 through 3 (of 3 total)
You must be logged in to reply to this topic. Login to reply