The OUTPUT Clause for the MERGE Statements
-
Comments posted to this topic are about the item The OUTPUT Clause for the MERGE Statements
Thanks,
AMAR
amarreddy23@gmail.com -
HI,
My question is regarding MERGE from SQL server. (Not exactly related output clause in Merge).
So, sorry in advance if I am disturbing this topic.------------------------
I am trying to get the data from One table to 2 temp table with different conditions.
Then update Quantity using mergebut it is giving some syntax error.
Please find my code snippet.///////////////////
Select * INTO #DT0604_MAX_TARGET from DT0604
where WID = @strWID
AND NO = (SELECT MAX(NO) FROM DT0604 where WID = @strWID AND NO <> -1)
/*All data less than MAX number in Source table.*/Select WID,ACD_FL,DATA_NO,SEQ_NO,GCT_COMP_NO,SUM(QTY) AS QTY INTO #DT0604_MAX_SOURCE from DT0604
where WID = @strWID
--AND NO = @str2ndMax_AkajiNo
/*#DT0604_MAX_TARGET Has max Akaji data.
Consider all Akaji data in source table except max Akaji data.*/
AND NOT EXISTS
(
SELECT 'X' from #DT0604_MAX_TARGET
where #DT0604_MAX_TARGET.WID = DT0604.WID
AND #DT0604_MAX_TARGET.NO = DT0604.NO
)
GROUP BY WID,ACD_FL,DATA_NO,SEQ_NO,GCT_COMP_NOMERGE #DT0604_MAX_TARGET AS TARGET /* Syntax error here according to SQL*/
USING #DT0604_MAX_SOURCE AS SOURCE
ON
(
Target.WID = Source.WID AND
Target.ACD_FL = Source.ACD_FL AND
Target.DATA_NO = Source.DATA_NO AND
Target.SEQ_NO = Source.SEQ_NO AND
Target.GCT_COMP_NO = Source.GCT_COMP_NO
)WHEN MATCHED THEN
UPDATE SET TARGET.QTY += SOURCE.QTYOUTPUT $action,
DELETED.WID AS Target_WID,
DELETED.NO AS Target_NO,
DELETED.ACD_FL AS Target_ACD_FL,
DELETED.GCT_COMP_NO AS Target_GCT_COMP_NO,
INSERTED.WID AS Source_WID,
INSERTED.NO AS Source_NO,
INSERTED.ACD_FL AS Source_ACD_FL,
INSERTED.GCT_COMP_NO AS Source_GCT_COMP_NO;Select * from #DT0604_MAX_TARGET
//////////////////I am not sure where the syntax is going wrong.
To my surprise if I execute the code in separate parts then it is executed successfully.Thank you in advance.
-
This filled 2 gaps in my knowledge store, the first being a chance to see an example of the MERGE statement, which is a statement I still know little about, and the second, being able to see the output clause in action.
I appreciate the straight easy to follow examples and commentary.
Thank you very much.
Luther
-
Thanks for such a great article--I'm surprised that I hadn't stumbled upon it sooner. This is going to aid me in qc'ing my own programming.
-
Wish you'd gone into more detail regarding specific uses for the OUTPUT clause in general and with MERGE specifically.
For one thing, MERGE allows you to also include columns from the USING source. Outside of MERGE, you only can access data in the INSERTED and DELETED tables and $action.
We had a project a few years ago that required pulling data from multiple sources and merging it into a single table. Each source had an IDENTITY column as the PK. The table with all the consolidated data also had an IDENTITY column that became the PK for that table.
Once all the data had been loaded we needed to have a table of the old PK and new PK relationship so subsequent FK references could be properly updated. We COULD have added an additional column in the new table that held the old PK value and dropped it after we'd finished all the conversions, but these were production tables and that really wasn't an option.
Using MERGE / OUTPUT something similar to the following was created:MERGE INTO tblMERGED tgt
USING (SELECT 'tblSourceN' AS srcTable, *) src
ON 1=2 -- this just insures that all rows will be inserted
WHEN NOT MATCHED THEN INSERT
( columnList )
VALUES ( columnList )
OUTPUT src.tblSourceN, scr.ID, INSERTED.ID INTO #myKeysTable(srcTableName, srcID, tgtID);
I can run this merge statement for multiple source tables, changing only the value of srcTable in the USING clause and I have loaded my target table and created a cross-reference table for future use/audit purposes, etc. I can include GETDATE() AS LoadDate in my USING clause and include it in my OUTPUT clause so I know when each table was processed.Another cool feature of the OUTPUT clause is that it can be used as the source of an INSERT statement with the results of the OUTPUT filtered for only specific actions. See Example D in Microsoft Docs.
-
We use MERGE with the OUTPUT clause a lot for maintaining our data warehouse insurance claims table, and like Doug Bishoop says, we use the OUTPUT as the source of the INSERT statement, but we're doing it in multiple statements. We OUTPUT to a table variable--only the columns we need, of course--and not only do we insert from there, but we also use it to get counts of update, insert, and delete actions to put in our logs. In fact, I've recently directed all developers to stop using @@ROWCOUNT and instead to use OUTPUT (to a table) so that I know we're getting the correct number of rows affected. Because I'm suspicious about @@ROWCOUNT, but also because it's not real useful after a MERGE. I'm interested to know if anybody would suggest I get accurate counts another way.
-
Excellent article! We haven't had much call for MERGE yet, but it's good to know that OUTPUT will work fine with it, and your instructions make it clear what we can and can't expect from it.
One really minor point of correction. You mention that '“DELETED” contains the old copy of the rows(UPDATE‘s SET)'. If there are newcomers to OUTPUT reading this, you may want to correct that to state that DELETE and UPDATE both will populate the DELETED magic table. We use this often to confirm what actually got DELETEd. Very handy.
Thanks! -
My favorite use of the OUTPUT clause in a MERGE statement is to output the value of a column that you didn't insert into the target table but need to figure out what incoming data resulted in what identity values when inserted into your target table.
Not sure if anyone else has ever faced the issue of deriving a dataset and inserting it into a table with an identity column, the value of which you need down the line to insert related data in other tables, but when I faced this situation in the past, I resorted to various hacks to accomplish this (our DBAs were loath to grant the level of permissions required to set identity insert on, plus this required locking the table and some additional effort to determine the correct starting value for the identity column, and joining on every column in the table seemed less than optimal). But now I leverage a merge statement, the 'inserted' table, and an output clause for this task.
First, a staging table and some test data
if object_id('dbo.stg_incoming_data_t' , 'u' ) is not null
drop table dbo.stg_incoming_data_t
go/*==============================================================*/
/* Table: stg_incoming_data_t */
/*==============================================================*/
create table dbo.stg_incoming_data_t (
row_id int identity(1000,8) not null,
employee_first_nm varchar(30) null,
employee_last_nm varchar(30) null,
dependent_1_rel_type_cd char(8) null,
dependent_1_first_nm varchar(30) null,
dependent_1_last_nm varchar(30) null,
dependent_2_rel_type_cd char(8) null,
dependent_2_first_nm varchar(30) null,
dependent_2_last_nm varchar(30) null,
dependent_3_rel_type_cd char(8) null,
dependent_3_first_nm varchar(30) null,
dependent_3_last_nm varchar(30) null,
constraint PK_STG_INCOMING_DATA_T primary key clustered (row_id)
)
GOinsert into stg_incoming_data_t ( employee_first_nm, employee_last_nm
, dependent_1_rel_type_cd, dependent_1_first_nm, dependent_1_last_nm
, dependent_2_rel_type_cd, dependent_2_first_nm, dependent_2_last_nm
, dependent_3_rel_type_cd, dependent_3_first_nm, dependent_3_last_nm
)
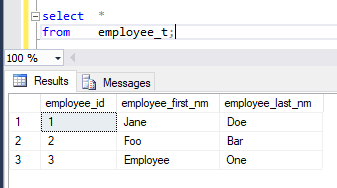
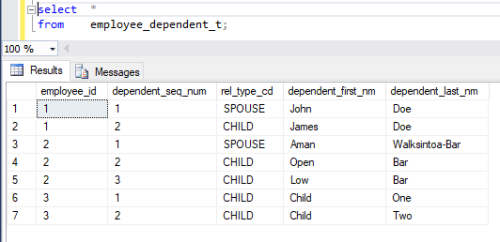
values ( 'Jane', 'Doe', 'SPOUSE', 'John', 'Doe', 'CHILD', 'James', 'Doe', NULL, NULL, NULL )
, ( 'Foo', 'Bar', 'CHILD', 'Open', 'Bar', 'CHILD', 'Low', 'Bar', 'SPOUSE', 'Aman', 'Walksintoa-Bar' )
, ( 'Employee', 'One', 'CHILD', 'Child', 'One', 'CHILD', 'Child' , 'Two', NULL, NULL, NULL )and our target tables:
if object_id('dbo.employee_dependent_t' , 'u' ) is not null
drop table dbo.employee_dependent_t
goif object_id('dbo.employee_t' , 'u' ) is not null
drop table dbo.employee_t
go/*==============================================================*/
/* Table: employee_t */
/*==============================================================*/
create table dbo.employee_t (
employee_id int identity not null,
employee_first_nm varchar(30) null,
employee_last_nm varchar(30) not null,
constraint PK_EMPLOYEE_T primary key clustered (employee_id)
)
GO/*==============================================================*/
/* Table: employee_dependent_t */
/*==============================================================*/
create table dbo.employee_dependent_t (
employee_id int not null,
dependent_seq_num smallint not null,
rel_type_cd char(8) null,
dependent_first_nm varchar(30) null,
dependent_last_nm varchar(30) not null,
constraint PK_EMPLOYEE_DEPENDENT_T primary key (employee_id, dependent_seq_num),
constraint FK_EMPLE1 foreign key (employee_id) references employee_t (employee_id)
)
GOUsing a MERGE statement allows you to include columns in the source for your merge that don't actually get inserted into your target table, unlike your standard INSERT INTO...SELECT FROM statement. You can then OUTPUT those values along with identity values from the inserted table into a table variable, which you can leverage to insert related data into dependent tables, like so (I used the = NULL construct to force them all to be inserts for demonstration purposes):
MERGE employee_t as tgt
USING stg_incoming_data_t src
ON tgt.employee_id = NULLWHEN NOT MATCHED
THEN INSERT ( -- employee_t
employee_first_nm
, employee_last_nm
)
VALUES ( employee_first_nm
, employee_last_nm
)OUTPUT inserted.employee_id
, src.row_id
INTO @identity_output_t;insert into employee_dependent_t
select employee_id
, dense_rank()
over( partition by employee_id
order by rel_typ_cd desc
, dependent_seq_num
)
, rel_typ_cd
, dependent_first_nm
, dependent_last_nm
from (
select row_id
, 1 as dependent_seq_num
, dependent_1_rel_type_cd as rel_typ_cd
, dependent_1_first_nm as dependent_first_nm
, dependent_1_last_nm as dependent_last_nm
from stg_incoming_data_t
where dependent_1_rel_type_cd is not nullunion all
select row_id
, 2 as dependent_seq_num
, dependent_2_rel_type_cd as rel_typ_cd
, dependent_2_first_nm as dependent_first_nm
, dependent_2_last_nm as dependent_last_nm
from stg_incoming_data_t
where dependent_2_rel_type_cd is not nullunion all
select row_id
, 3 as dependent_seq_num
, dependent_3_rel_type_cd as rel_typ_cd
, dependent_3_first_nm as dependent_first_nm
, dependent_3_last_nm as dependent_last_nm
from stg_incoming_data_t
where dependent_3_rel_type_cd is not null
) dt
join @identity_output_t id
on dt.row_id = id.row_id;Results:

(I used DENSE_RANK() for the sequence number so I could force the spouse to the top of this list if there was one, because that's just my special brand of OCD (and of course it assumes knowledge that SPOUSE is the last valid relationship type alphabetically, but, hey, it's my demo so I'm going to go with that)
Anyway, sorry for the novel, and it's my first time posting I think, so I hope I formatted everything correctly, but I hope this helps someone expand their bag of tricks. SQL for the above plus a select on the @identity_output table variable attached as well.
Regards,
Laura -
I guess that's what I get for starting a post first thing in the morning and not getting to finish it until all my meetings are done later in the day. So now I'm sorry for posting a novel that wasn't even necessary since others got there before me...
- laura.wachs - Friday, March 8, 2019 1:29 PM
Been there, done that. No worries, great example. A lot more detailed than mine.
-
No article on OUTPUT and MERGE should be complete without referencing Aaron Bertrand's cautionary article on using MERGE.
https://www.mssqltips.com/sqlservertip/3074/use-caution-with-sql-servers-merge-statement/
- johnzabroski - Monday, March 11, 2019 7:53 AM
I agree! Here's an excerpt ...
[After listing 29 bugs] is the condensed format of MERGE really worth all of the extra testing that will require?I was so excited when MERGE first came out but after experiencing one anomaly after another, I realized that my list of documented "gotchas" grew longer than my patience. I haven't touched that command in 10 years. - thisisfutile - Monday, March 11, 2019 11:12 AM
In all fairness, it appears Aaron's list is somewhat out of date. I clicked on some of them marked "Won't Fix" and it appeared that, of those I checked, most had been fixed, albeit ppossibly in a later version of SQL Server. Also, just counting the number of issues is not fair either as some as, "Poor error message with MERGE when source/target appear in impossible places" which isn't really a bug but just a confusing error message, and one that is an issue with both MERGE and DELETE.
I have used MERGE since SQL Server 2008R2 for production ETL, loading literally millions of rows of data into tables containing tens of millions of rows of data and have never experienced an issue. I've had people point out to me that if you do A and B and C and D where the conditions are E and F then you'll have problems with MERGE, but I guess I've only done A and B and D without C and gotten lucky.
- doug.bishop - Monday, March 11, 2019 11:23 AM
Thanks for the reply. My experience was uncovering the anomalies personally and that led me to the stance that I was never going to work with it. Over the years I've seen good and bad reviews of the command and I just got the feeling (fear?) that it may get deprecated before it fully matures. So, couple a bad first experience with a guess of early abandonment and I've decided I'll never give it a second try (are my 47 years of age showing?) I remember when I started discovering CTE's and I recalled my MERGE experience and almost decided to avoid them and stick with derived tables just on principle. Fortunately, CTE's worked flawlessly for me and have ever since ... well, until I get wrapped up in recursion.
- thisisfutile - Monday, March 11, 2019 12:18 PM
I guess that is what makes us all unique. I've run across database developers who will always chose to use a table variable over a temp table because table variables are in memory and not written to disk. The first time a MERGE bites me, I'll be more cautious, but won't stop using them. To me, they are much easier to read and understand than replicated code with LEFT JOINS checking for NULLs to do UPSERTS (and possibly add a DELETE in there) and the flexibility of exposing data from the source side of the query in the OUTPUT clause has made them next to invaluable on more than one occasion.
I've learned there is enough room out there in the universe for everyone to have a different opinion about something and that doesn't make them right or wrong or better or worse, just different.

Viewing 15 posts - 1 through 15 (of 21 total)
You must be logged in to reply to this topic. Login to reply