string compare again .. :)
-
I have a meta data string with 5 different numbers, for example
@mdtsr ='4,12,13,14,17'
and i have few hundred thousand records in a table with same structure, i mean 5 numbered string with a comma separator.
I need to compare the strings in the table to metadata string and find all the records with at least 2 matches. (Numbers in the same array position should match)
Declare @mdstr varchar(20)
set @mdstr ='4,12,13,14,17'
Create table Strhold ( id1 int, Bstr varchar(20))
Insert into Strhold values(1, '1,2,3,4,5')
Insert into Strhold values(2, '4,12,55,76,89')
Insert into Strhold values(3, '3,9,13,17,45')
Insert into Strhold values(4, '1,12,13,15,17')
Insert into Strhold values(5, '9,10,13,14,17')
Insert into Strhold values(6, '32,33,34,35,36')
Insert into Strhold values(6, '4,12,13,14,17')
/* The output expected
4,12,55,76,89
1,12,13,15,17
9,10,13,14,17
4,12,13,14,17
*/ The above records in output has at least 2 matching numbers in the same array position.
Thanks in advance.
-
Did you mean to have 2 entries in the StrHold table that have a "6" for ID1 or is that a typo???
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Ok... making the assumption that ID1 is actually supposed to be unique, here's the creation/population of the test table that I reformatted the way I normally would write such code as an example (it's just a habit).
--===== Create and populate the test table.
-- This is NOT a part of the solution.
-- We're just setting up test data here
DROP TABLE IF EXISTS dbo.Strhold --Makes reruns in SSMS easier
;
CREATE TABLE dbo.Strhold (id1 INT, Bstr VARCHAR(20))
;
INSERT INTO dbo.Strhold
(id1,Bstr)
VALUES (1,'1,2,3,4,5')
,(2,'4,12,55,76,89')
,(3,'3,9,13,17,45')
,(4,'1,12,13,15,17')
,(5,'9,10,13,14,17')
,(6,'32,33,34,35,36')
,(7,'4,12,13,14,17') --Started off as 6 for ID1 and was possible typo on part of OP
;Here's one solution... the explanation is in the comments.
--===== Define what we're looking for.
-- This could be a parameter for a stored procedure or iTVF.
DECLARE @mdstr VARCHAR(20);
SET @mdstr ='4,12,13,14,17'
;
--===== Split all the "gazintas" to create an inline NVP table, do the comparison,
-- filter to only what match, use GROUP BY to renormalize the data
-- through aggregation, and display it all for demonstration purposes.
-- Comment out the columns you don't want/need for final code.
-- NOTE THAT THIS RELIES ON THE ID1 COLUMN CONTAINING ONLY UNIQUE DATA!!!
-- Note also that the given expected results are actually incorrect. ;-)
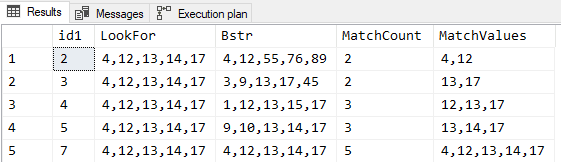
SELECT sh.id1
,LookFor = @mdstr
,Bstr = MAX(sh.Bstr)
,MatchCount = COUNT(*)
,MatchValues = STRING_AGG(split.value,',')
FROM dbo.Strhold sh
CROSS APPLY STRING_SPLIT(sh.Bstr,',') split
CROSS APPLY STRING_SPLIT(@mdstr,',') find
WHERE split.value = find.value
GROUP BY sh.id1
HAVING COUNT(*) > 1 --2 or more matches
;Here are the results, which also indicate that your posted desired results are actually missing the row where ID1 = 3, which actually does have 2 matches.

If ID1 actually DOES have two rows with the value of "6", post back because there's a workaround for that.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s.
If you have to do such lookups a whole lot, it would help a whole lot if you materialized the NVP as a very narrow unique Clustered Index table and use a trigger on the original table to keep the NVP table up to date. The key would be the single value of the Bstr column and the related ID1 column. Think of it as an easy "poor-man's" full text lookup system that will also take trailing wild cards for each "element".
And don't let the row count of such a table scare you.
Almost forgot...
NVP = "Name//Value Pair" table.
This same method is also quite fantastic for partial name or address lookups when all you have is a full name or full address column.
"Fantastic" = "Nasty Fast" and resource-usage efficient.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.p.s.
If anyone wants to do some testing of the method I posted or some other method, here's a 500,000 row test table like the OP said ("few hundred thousand") they had to work with.
--===== Create a 500,000 row test table for performance testing
DROP TABLE IF EXISTS dbo.Strhold
;
SELECT ID1 = t.N
,Bstr = STRING_AGG(ABS(CHECKSUM(NEWID())%100)+1,',')
INTO dbo.Strhold
FROM dbo.fnTally(1,500000) t
CROSS JOIN dbo.fnTally(1,5) t5
GROUP BY t.N
;The method I used finds and displays approximately 11,252 matches out of 500,000 rows in about 3 and a half seconds.
(11252 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 2862, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Strhold'. Scan count 1, logical reads 2993, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 3422 ms, elapsed time = 3453 ms.
If you don't already have one, you can get a copy of what I use for the "fnTally" function at the similarly named link in my signature line below. For me, having such a function is quintessential to a lot of the work I do daily in real life and makes life a whole lot easier for things like this.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
wow, i did not thought string_agg can come handy here.Great Jeff.
- Sorry for ID1 had 6 twice, thats a typo.
- But Id1=3 was not expected in the output. Though there are 2 matches, they are not matched in the same array position. What i mean is, @mdstr ='4,12,13,14,17' which has numbers 13 and 17 in 3rd and 5th positions where as in ID1=3 , those numbers 13 and 17 are 3rd and 4th positions. so this is not a Match. That's why i did not output this record in initial post.
Regards
Jus
-
My apologies... I missed the part about the "array position" in your original post. We can fix that but Split_String isn't going to work at all for that because (and why they did it this way, I'll never know) Split_String does not return the "array position" and the methods some people have developed to do so isn't guaranteed to do so correctly.
There IS a solution with good ol' fashioned DelimitedSplit8K, so I'll be back.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Quick question... In all of your example data, the array values appear to be in numerical order. Is this always the case or just a you creating fake test data?
Second observation... All of the sample arrays have exactly 5 elements. Is that the case when it comes to the actual production data?
-
Here you go. DelimitedSplit8K made the changes very simple.
--****** This is for when the position matches, as well... ******
--===== Define what we're looking for.
-- This could be a parameter for a stored procedure or iTVF.
DECLARE @mdstr VARCHAR(20);
SET @mdstr ='4,12,13,14,17'
;
--===== Split all the "gazintas" to create an inline NVP table, do the comparison,
-- filter to only what matches, use GROUP BY to renormalize the data
-- through aggregation, and display it all for demonstration purposes.
-- Comment out the columns you don't want/need for final code.
-- NOTE THAT THIS RELIES ON THE ID1 COLUMN CONTAINING ONLY UNIQUE DATA!!!
-- Note also that the given expected results are actually incorrect. ;-)
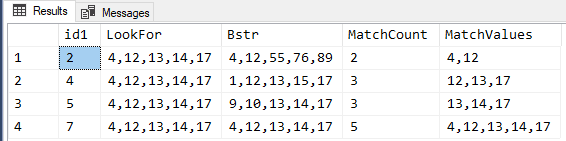
SELECT sh.id1
,LookFor = @mdstr
,Bstr = MAX(sh.Bstr)
,MatchCount = COUNT(*)
,MatchValues = STRING_AGG(split.Item,',')
FROM dbo.Strhold sh
CROSS APPLY dbo.DelimitedSplit8K(sh.Bstr,',') split
CROSS APPLY dbo.DelimitedSplit8K(@mdstr,',') find --This is only executed once because no correlation here.
WHERE split.ItemNumber = find.ItemNumber
AND split.Item = find.Item
GROUP BY sh.id1
HAVING COUNT(*) > 1 --2 or more
;The results look like you posted in your original post along with the extra columns I previously added to make verification a little easier...
I've attached the version of DelimitedSplit8K that I'm currently using as a .txt file (it's ironic that an SQL forum won't allow you to attached a .SQL file).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
yes Jason. The string always in numerical ascending order. and every string will have exact 5 numbers in production.
-
This is awesome. worked great. you made my day Jeff. Always big fan of you.. 🙂
- Jus wrote:
yes Jason. The string always in numerical ascending order. and every string will have exact 5 numbers in production.
In that case, here is a modified version of Jeff's test table code that arranges the arrayed values in ascending order.
--===== Create a 500,000 row test table for performance testing
DROP TABLE IF EXISTS dbo.Strhold
;
SELECT
ID1 = t.N
,Bstr = STRING_AGG(av.array_value,',') WITHIN GROUP (ORDER BY av.array_value ASC)
INTO dbo.Strhold
FROM dbo.fnTally(1,500000) t
CROSS JOIN dbo.fnTally(1,5) t5
CROSS APPLY ( values (ABS(CHECKSUM(NEWID())%100)+1) ) av (array_value)
GROUP BY t.N
;It also means that the STRING_SPLIT FUNCTION will work because we can use the sort order of the values to determine the ordinal positions.
I'll post new code in a followup post...
-
No need for a followup... at least not one using STRING_SPLIT()... By the time you convert the split values to INTs and sort on them, the DelimitedSplit8k() version is way faster than using STRING_SPLIT().
The only other option that comes to mind that may be able to compete would be to manually split the values using nested CHARINDEX()
- Jus wrote:
This is awesome. worked great. you made my day Jeff. Always big fan of you.. 🙂
Glad to have been able to help. Thank you for the feedback.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Just as a side note, depending on how often your columns are updated/modified, you can always split the string ahead of time using a permanent tally table like this:
-- Tally Table Code (if you dont have one)
IF OBJECT_ID('dbo.tally') IS NOT NULL DROP TABLE dbo.tally;
CREATE TABLE dbo.tally (N INT NOT NULL);
INSERT dbo.tally(N) SELECT N FROM dbo.fnTally(1,10000);
ALTER TABLE dbo.tally
ADD CONSTRAINT pk_cl_tally PRIMARY KEY CLUSTERED(N) WITH FILLFACTOR=100;
ALTER TABLE dbo.tally
ADD CONSTRAINT uq_nc_tally UNIQUE NONCLUSTERED(N);
GO
CREATE VIEW dbo.Strhold_Split WITH SCHEMABINDING AS
SELECT
StrId = t.id1,
item =
SUBSTRING
(
t.Bstr,
tt.N+SIGN(tt.N-1),
ISNULL(NULLIF((CHARINDEX(',',t.Bstr,tt.N+1)),0),LEN(t.Bstr)+1)-(tt.N)-SIGN(tt.N-1)
)
FROM dbo.Strhold AS t
CROSS JOIN dbo.tally AS tt
WHERE tt.N <= LEN(t.Bstr)
AND (tt.N = 1 OR SUBSTRING(t.Bstr,tt.N,1) = ',');
GO
CREATE UNIQUE CLUSTERED INDEX uq_cl_Strhold_Split ON dbo.Strhold_Split(Item,StrId);
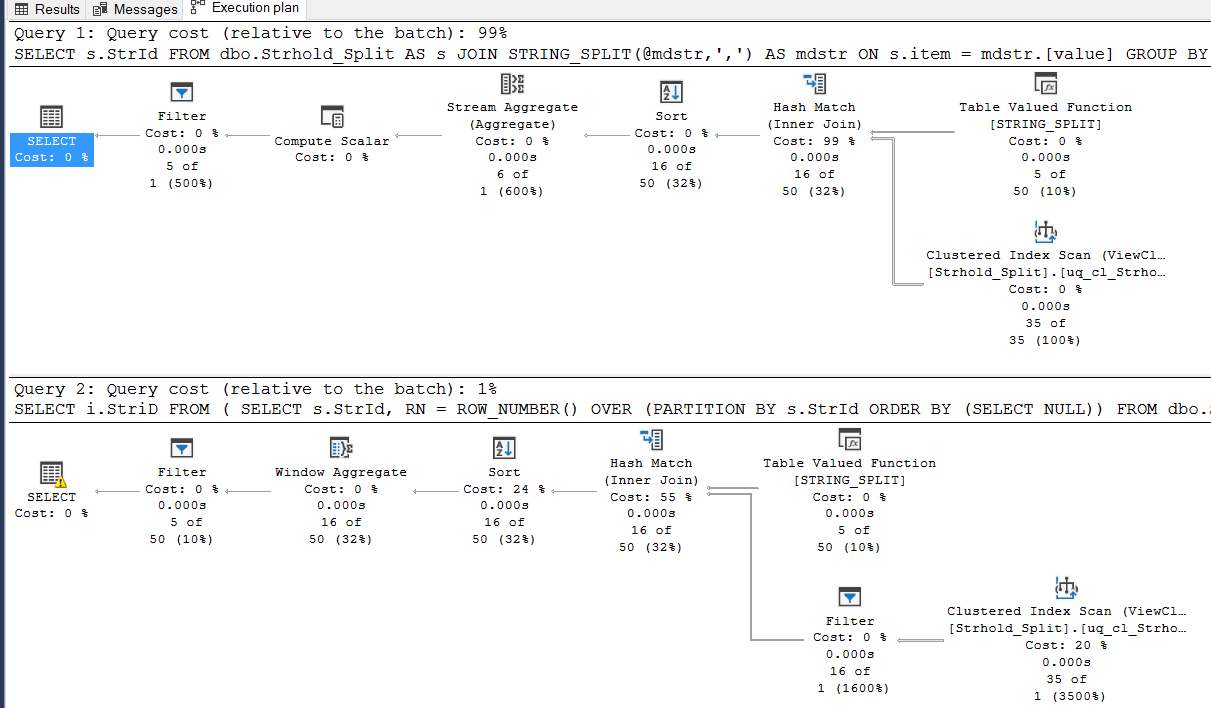
GONote the execution plan using the the persisted tally table for the sort
This split only happens once. Each new row added to dbo.Strhold is split once, behind the scenes. Now the items are available and indexed. You can get the rows you need like this:
Declare @mdstr varchar(20) ='4,12,13,14,17'
-- OPTION #1: USING GROUP BY/HAVING
SELECT s.StrId
FROM dbo.Strhold_Split AS s
JOIN STRING_SPLIT(@mdstr,',') AS mdstr ON s.item = mdstr.[value]
GROUP BY s.StrId
HAVING COUNT(*) > 1;
-- OPTION #2: USING GROUP ROW_NUMBER()
SELECT i.StriD
FROM
(
SELECT s.StrId, RN = ROW_NUMBER() OVER (PARTITION BY s.StrId ORDER BY (SELECT NULL))
FROM dbo.Strhold_Split AS s
JOIN STRING_SPLIT(@mdstr,',') AS mdstr ON s.item = mdstr.[value]
) AS i
WHERE RN = 2;Both work on the same number of rows but the ROW_NUMBER solution gets batch mode over rowstore processing in SQL Server 2019 (see this 3-part series by Itzik Ben-Gan, and this article by Paul White.) Note the execution plans. Here the ROW_NUMBER version appears much better than it is (it's not a 99% to 1% performance difference.)
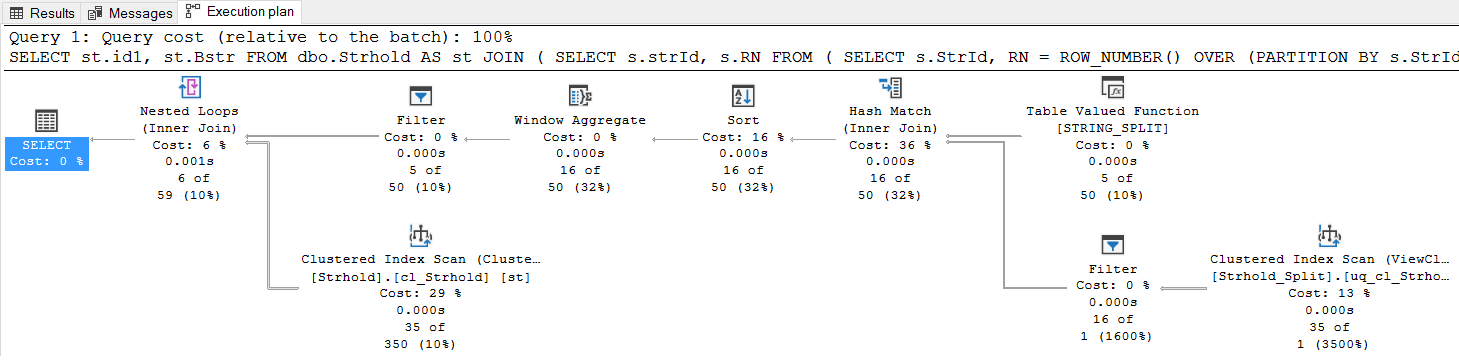
This will get you the results you need while only having to split @mdstr:
Declare @mdstr varchar(20) ='4,12,13,14,17'
SELECT st.id1, st.Bstr
FROM dbo.Strhold AS st
JOIN
(
SELECT s.strId, s.RN
FROM
(
SELECT s.StrId, RN = ROW_NUMBER() OVER (PARTITION BY s.StrId ORDER BY (SELECT NULL))
FROM dbo.Strhold_Split AS s
JOIN STRING_SPLIT(@mdstr,',') AS mdstr ON s.item = mdstr.[value]
) AS s
WHERE RN = 2
) AS s ON s.StrId = st.id1;Here's the solutions actual plan: The rows are retrieved instead of created. The sort can be handled too but that you can figure out.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001

Viewing 15 posts - 1 through 15 (of 19 total)
You must be logged in to reply to this topic. Login to reply