SSDT creates a clustered index b4 clustered columnstore index, then drops - WHY
-
Hi.
I've got a database project. A clustered columnstore index on a table in it. When I generate the deployment script, SSDT first wants to create a normal clustered index on the first column in the table (whatever it is, even one that's not allowed in such a construct, e.g., varchar(max)), then wants to execute the creation statement for the clustered columnstore index with the 'with(drop_existing=on)' option. This breaks down when the table's first column is not allowed to be the key column in a clustered index. But SSDT does not check for this! Hence, my deployment fails. How do I convince SSDT to stop creating a clustered index on the table when I just want to create a clustered columnstore index? Here's what the script wants to do:
CREATE CLUSTERED INDEX [egni]
ON [Fact].[EcommGeomappedNew]([DomainName]);
CREATE CLUSTERED COLUMNSTORE INDEX [egni]
ON [Fact].[EcommGeomappedNew] WITH (DROP_EXISTING = ON);How do I prevent this from happening?
Thank you.
Darek
-
Which version of SSDT?
Have you got any other tables with clustered columnstore indexes on them? Is there something special about this table, or does it happen for every table like this?
-
Hi Phil.
Many thanks for coming back on this. It drives me crazy...
It happens at least in VS 2019 and 2020, which I've checked. I have several tables with such an index and it happens for all of them. There's nothing special about these tables. They do have columns of different data types, some of the types are not suitable for a clustered index (as indicated before) but OK for a clustered **columnstore** index. For instance, varchar(max) can't be a key in a clustered index.
If you create a quick db project in VS with just one table in it and put a clustered columnstore index on it in the project, then try to deploy to a server through the Generate Script functionality, you'll find the same issue I've found. Guaranteed.
Best
Darek
- darius.england wrote:
Hi Phil.
Many thanks for coming back on this. It drives me crazy...
It happens at least in VS 2019 and 2020, which I've checked. I have several tables with such an index and it happens for all of them. There's nothing special about these tables. They do have columns of different data types, some of the types are not suitable for a clustered index (as indicated before) but OK for a clustered **columnstore** index. For instance, varchar(max) can't be a key in a clustered index.
If you create a quick db project in VS with just one table in it and put a clustered columnstore index on it in the project, then try to deploy to a server through the Generate Script functionality, you'll find the same issue I've found. Guaranteed.
Best
Darek
I confirm that I have reproduced this in SSDT 2019. The fact that this deploys successfully
CREATE TABLE dbo.ColStore
(
Id INT NOT NULL
,SomeText VARCHAR(MAX) NOT NULL
);
GO
CREATE CLUSTERED COLUMNSTORE INDEX cci
ON dbo.ColStore
WITH (DROP_EXISTING = ON);While this does not
CREATE TABLE dbo.ColStore
(
SomeText VARCHAR(MAX) NOT NULL
,Id INT NOT NULL
);
GO
CREATE CLUSTERED COLUMNSTORE INDEX cci
ON dbo.ColStore
WITH (DROP_EXISTING = ON);Sounds like a bug to me. I could not find a setting to override this behaviour.
-
I believe that most people structure their table definitions with key columns first, which may explain why I have never seen this behaviour before.
-
Hi again, Phil.
You're right, of course. These tables were not under my control when they were created. I then worked for a different company. I can consider this setup a bit like a technical debt I guess. However, these tables were not meant to have a primary key on them anyway. There are no columns that would be suitable for such a key. They are fact tables that at their birth were meant to be clustered columnstores only and nothing more. Of course, Microsoft have not thought this whole matter entirely through, hence the problem.
Thanks.
-
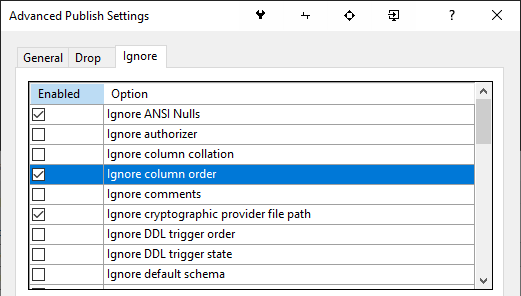
Well, there is something that you can do. Whether it helps you at all is a different matter, but I'll mention it just in case.
If you do the following, your deployments should work:
- In your SSDT projects put the columns in an order which would make deployment successful
- When publishing your project, click on Advanced/Ignore and put a check next to 'Ignore column order'

Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply